Developer Keynote에서는 「We’re Living in the Legacy Land」라는 곡을 구글 클라우드 직원들이 직접 노래하며 연주하는 공연으로 시작했다. 여기서 ‘레거시’란 개발자들이 실수를 저지르며 고통받으면서도 그렇게 하루하루 레거시를 쌓아나갈 수 있다는 내용인듯했다.
그리고 구글 클라우드가 이러한 당신의 ‘레거시’ 개발 환경에 실질적으로 어떤 도움을 줄 수 있는지(=Building the Next Legacy)를 소개하는 순서로 자연스럽게 이어졌다. 구글 클라우드가 줄 수 있는 도움은 구글 챔피온 이노베이터(Google Cloud Champion Innovator)들의 초청을 통해 인터뷰 형식으로 소개됐다.
기자는 개인적으로 이번 Google Cloud Next 2023에서 Google Cloud 제품인 Duet AI 🔗 ‘AppSheet‘가 가장 인상 깊었다. AppSheet는 기업이 원하는 앱을 자동으로 생성해 주는 No-Code App Builder다. 나중에 데모에서 Google 직원에게 물어봤을 때 PWA(Progressive Web App) 형태로 생성해 준다고 들었다. AppSheet를 사용하면 기존 업무를 상당 부분 자동화하는 것이 가능할 것으로 보인다. 이 제품은 Developer Keynote의 Product 부분과 행사 데모 세션에서 체험할 수 있었다.
Keynote에서는 가게, 공장, 학교 같은 비즈니스 현장에서 제품이나 서비스에 어떤 문제 혹은 이슈가 일어나 이를 보고해야 하는 상황을 가정했다.
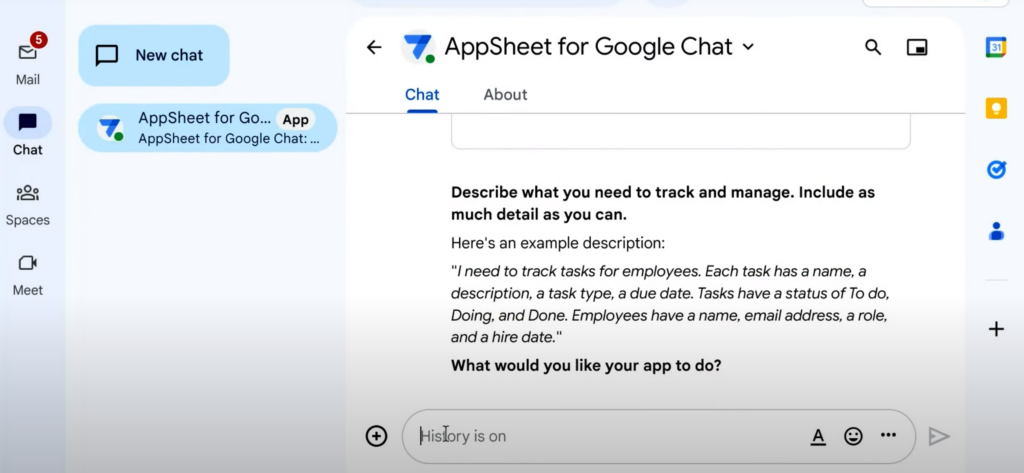
먼저, AppSheet 봇이 연동된 Google Chat에 들어가 보자.
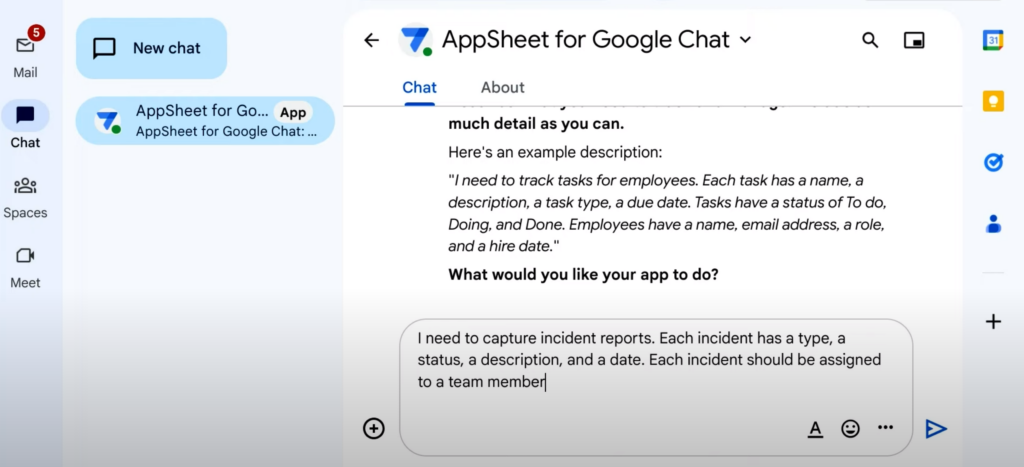
Google Chat에 요구 사항을 작성해 전달해 봤다. 예시로 든 비즈니스 상황에서 필요한 요구 사항은 아래와 같다.
[요구사항] ✔️폰, 태블릿을 사용해 문제가 된 현장 사진 데이터를 쉽게 캡처하고, 이 데이터를 바탕으로 보고서를 작성할 수 있어야 함 ✔️ 현장 사진을 AI로 분석할 수 있어야 함 ✔️ 관리팀은 운영 대시보드에 접근해 보고된 문제를 추적할 수 있어야 함 ✔️ 이슈가 발생하면 각 팀원에게 할당해야 함
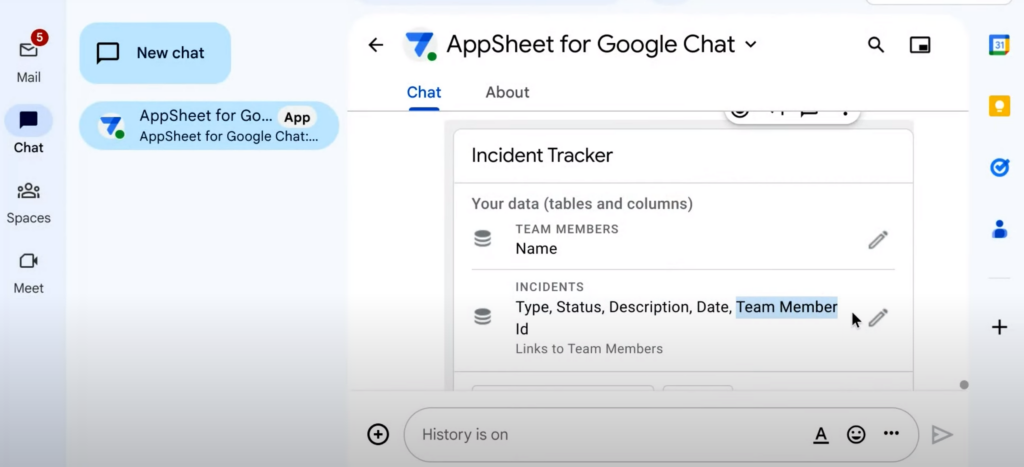
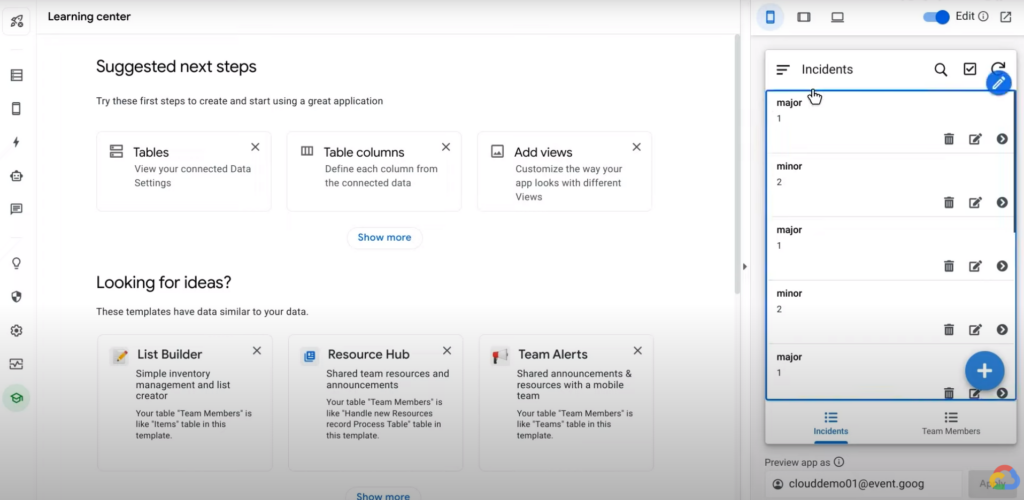
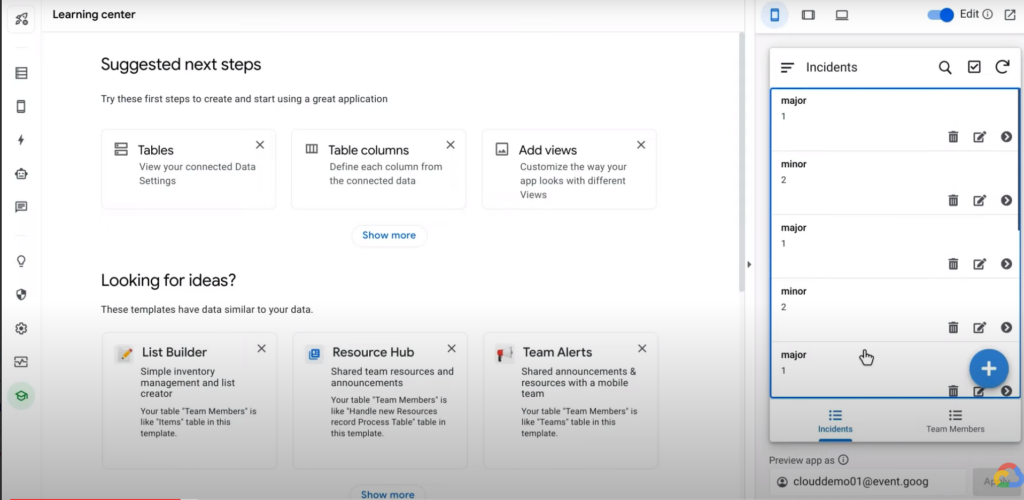
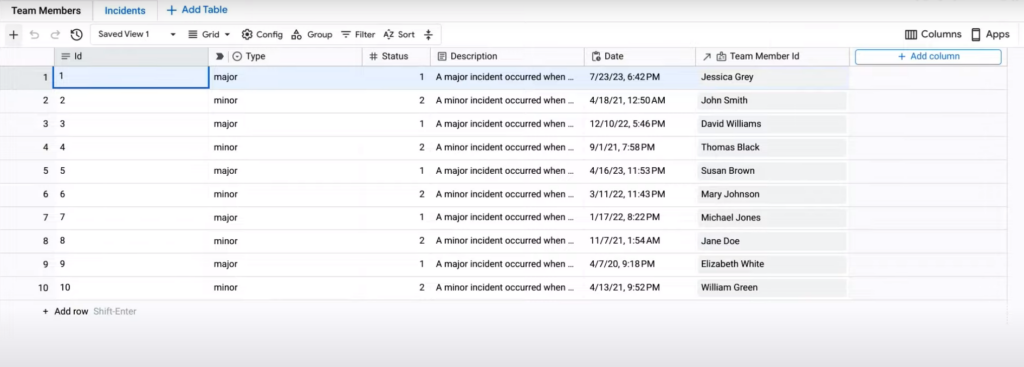
AppSheet는 2개 테이블을 답변을 내놓았다. 팀원 정보를 담은 팀원 테이블과, 발생한 이슈 정보를 모아놓은 이슈 테이블이다. 그리고 이슈 테이블에 이 2개 테이블을 서로 연결하기 위한 키 값으로 보이는 팀원 Id 열이 존재했다.
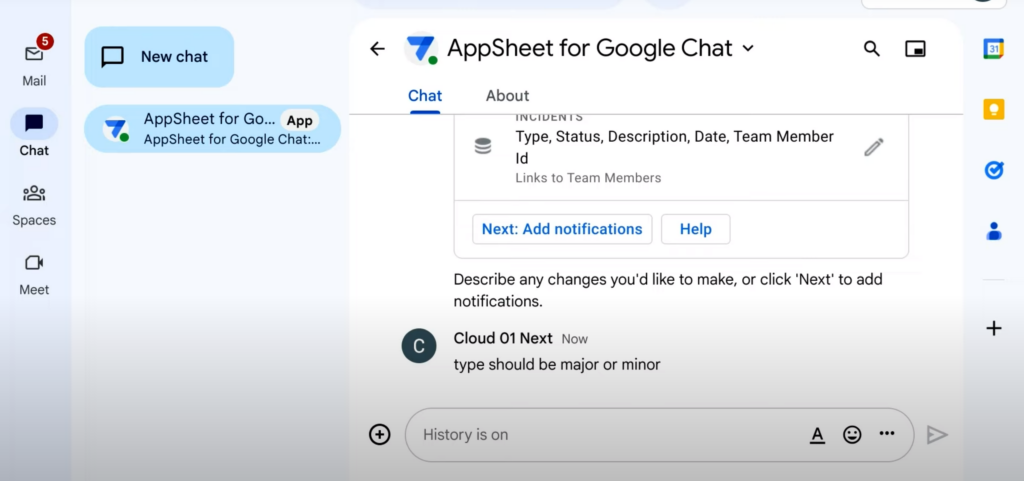
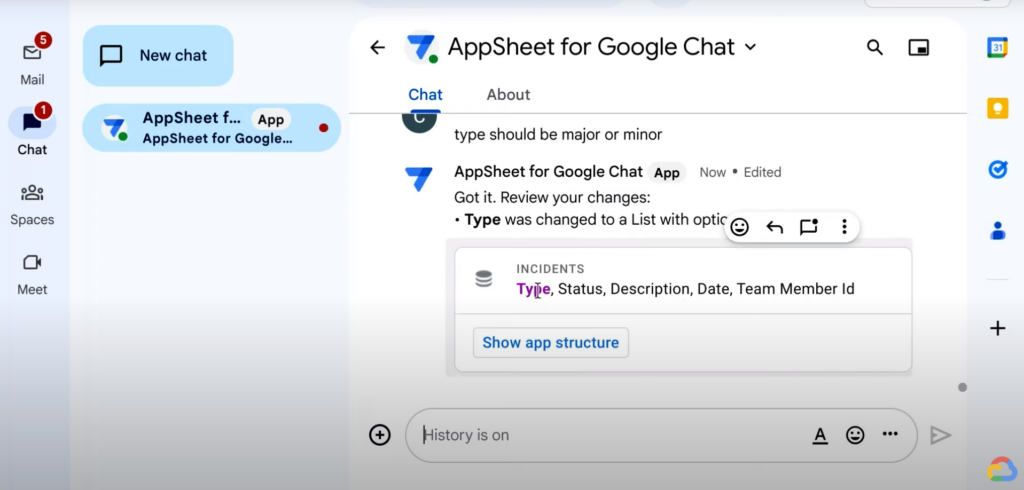
이슈 타입을 ‘major’ 또는 ‘minor’ 두 가지 타입으로 제한하길 원한다면, 해당 내용을 채팅에 넣으면 된다. 결과적으로 테이블에 반영되며, 연필 모양을 눌러서 테이블 정보를 직접 수정할 수도 있다.
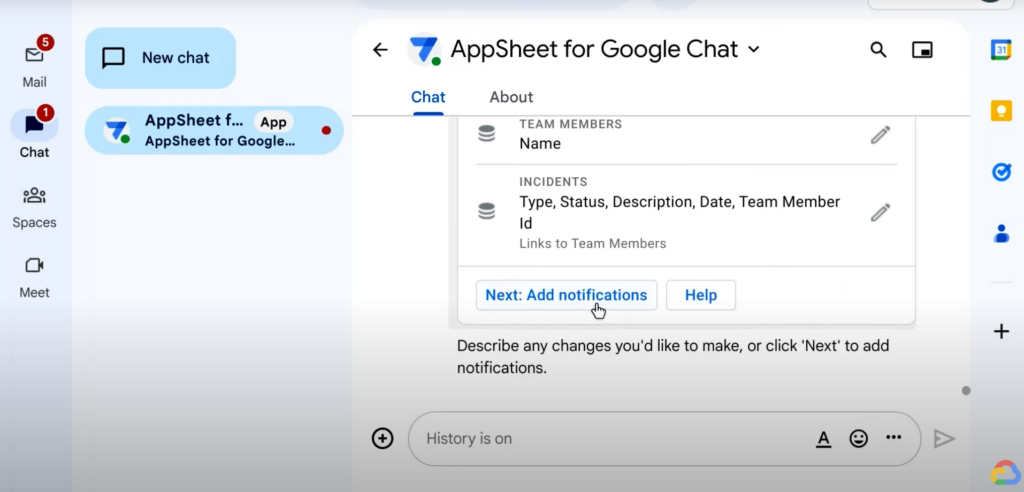
Next: Add notifications를 눌러 다음 단계로 진행한다. 이슈 보고 건이 올라올 때마다 팀원에게 이메일로 알림을 전송할 수 있다.
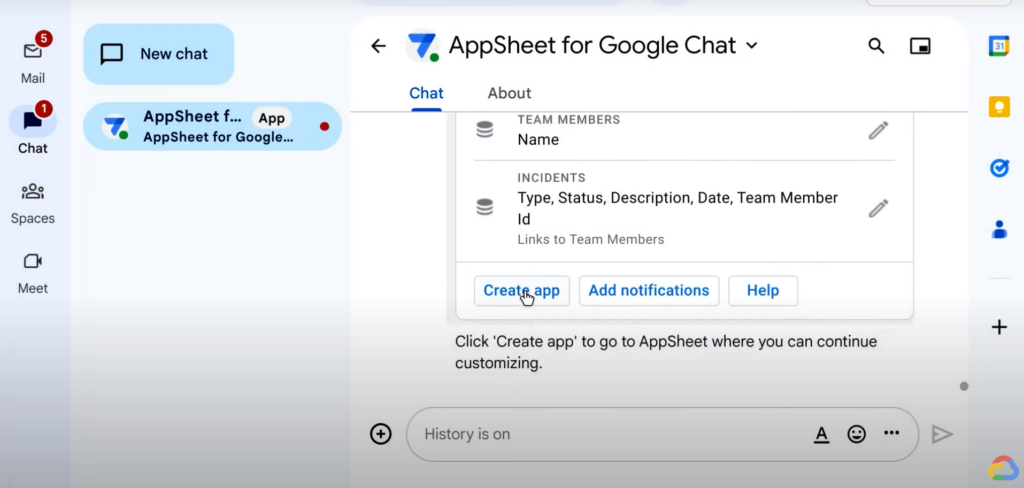
Skip을 누르고 Create App을 누르면 지금까지 설정한 요구 사항을 바탕으로 앱을 생성한다.
앱은 모바일, 데스크탑, 태블릿을 모두 지원한다. 앱에서 보고한 이슈 목록과 팀원 목록을 확인할 수 있다.
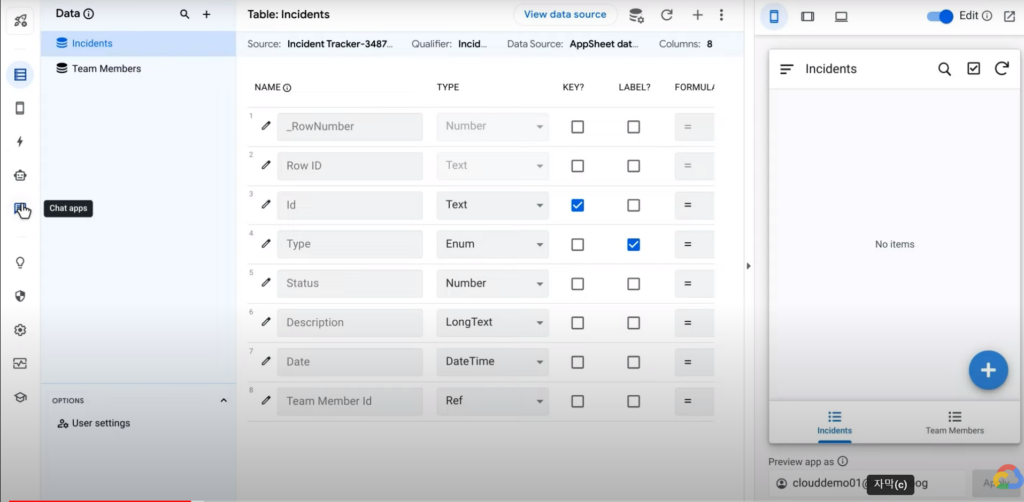
좌측 탭에서 Data를 누르면, 각 테이블 데이터를 편집할 수 있다.
화면 상단에 View Data Source를 누르면, 이슈와 팀원 데이터가 들어있는 실제 관계형 데이터베이스( 🔗Spanner) 테이블에 접근할 수 있다.
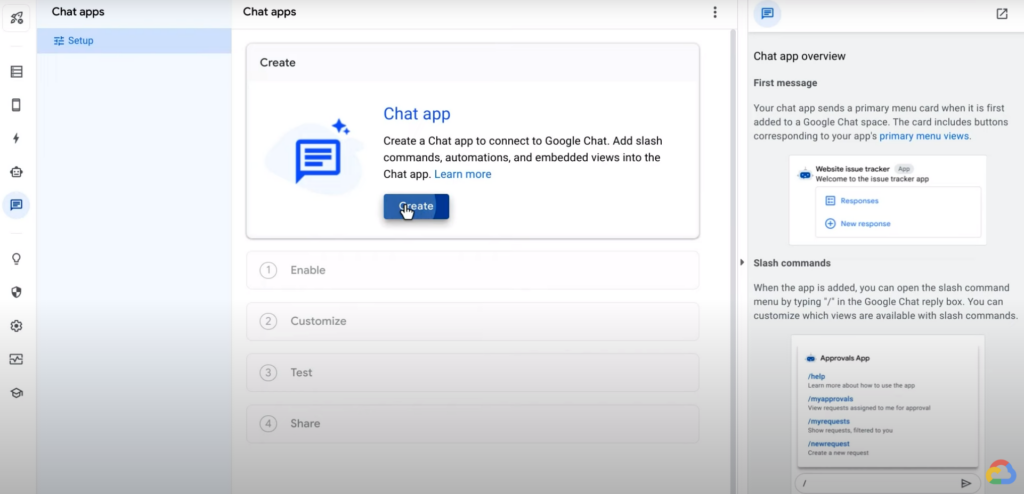
누군가 이슈를 보고하면 이메일 외에도 Google Chat으로 알림을 받을 수 있다. 좌측 탭에서 Chat app을 누르고 Chat app을 생성하면 된다.
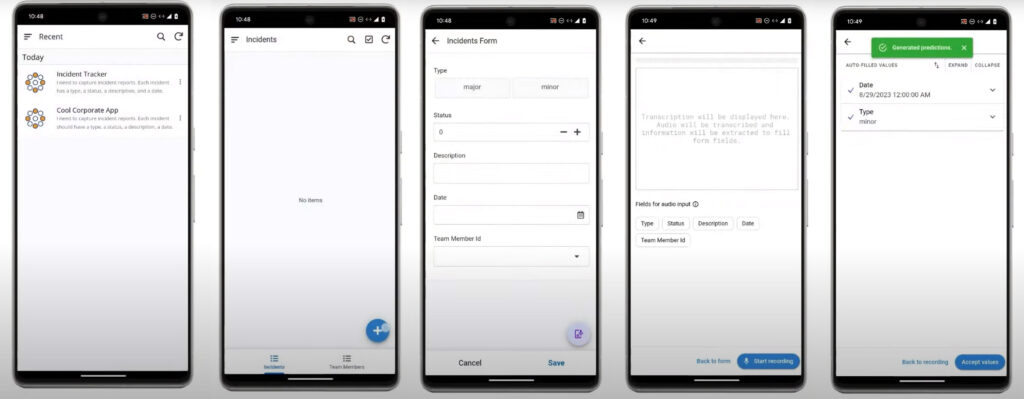
폰에서 AppSheet 모바일 앱을 클릭하면, 생성했던 이슈 관리 앱이 등록되어 있는 것을 볼 수 있다. 플러스 버튼을 누르면 모바일에서도 이슈를 등록할 수 있으며 이슈를 말로 설명하면 이 오디오를 캡처해 바로 보고할 수 있다.
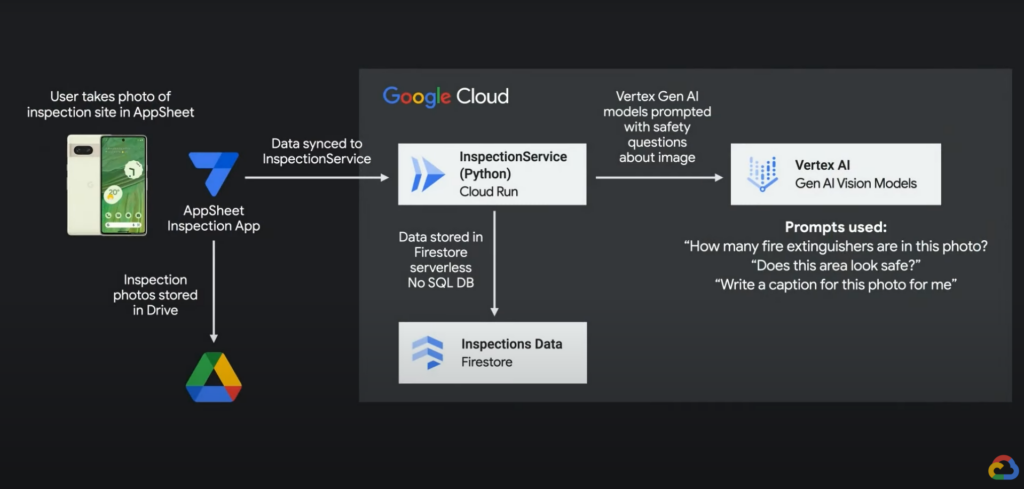
현장 사진을 찍었을 때 이 사진을 AI로 분석하고, 그 결과 문제가 있다면 이를 이슈로 보고할 수 있다. 다만 이는 AppSheet 단독으로는 안 되고, Vertex AI와 연동하면 가능하다.
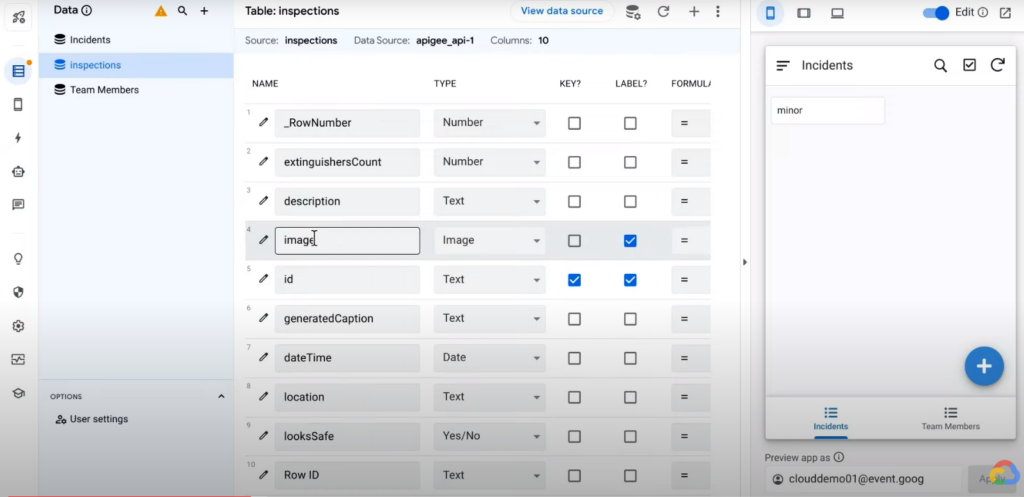
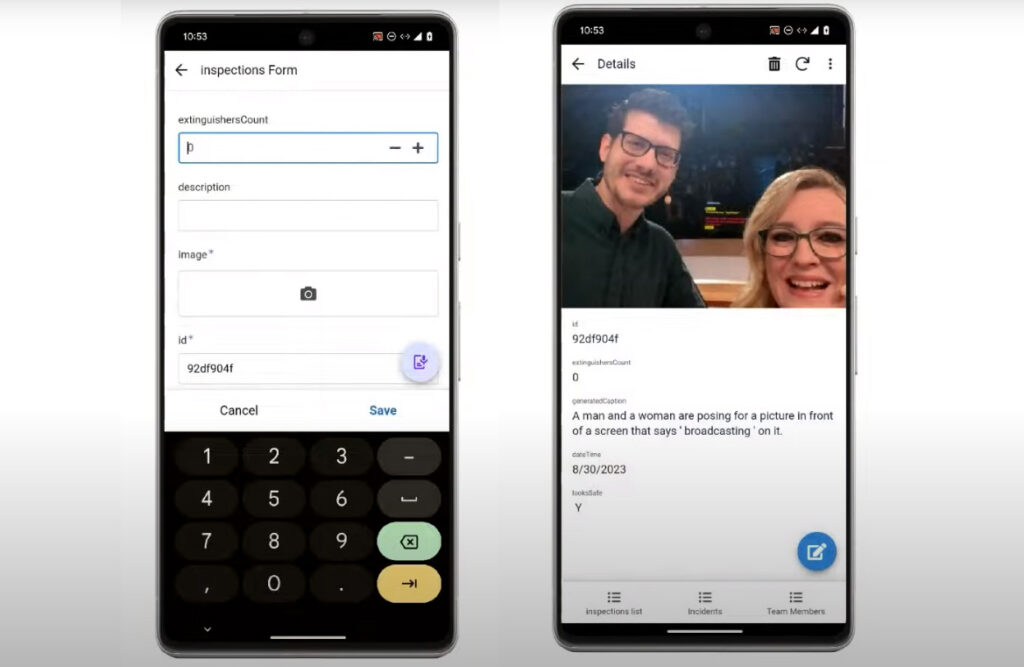
예시에서는 🔗Cloud Run 서비스를 통해 Vertex AI에 있는 Vision 모델들을 사용하며, 이 과정은 🔗Apigee API로 구현되어 있다. AppSheet에서 이를 연동하려면 AppSheet > Data 탭 > Add 메뉴에서 Apigee API를 추가하는 방식으로 이미지 분석 결과를 담은 테이블(Inspections 테이블)을 불러오면 된다.
이미지 분석 결과를 업로드할 Inspections 테이블이 만들어진 상태에서, 폰으로 사진을 찍어 업로드하면 Vertex AI에서 이를 분석해 description까지 달아주고 이 정보를 테이블에 추가한다. Keynote에서는 데모 진행자의 셀피를 찍어 업로드했다.
Vertex AI가 셀피 이미지를 분석해 text description을 생성했다.
LLM 기반 모델(the foundation models of Large Language Model)이 B2C 시장에서 상품 검색과 추천에 어떻게 기여할 수 있는지를 소개하는 세션이었다.
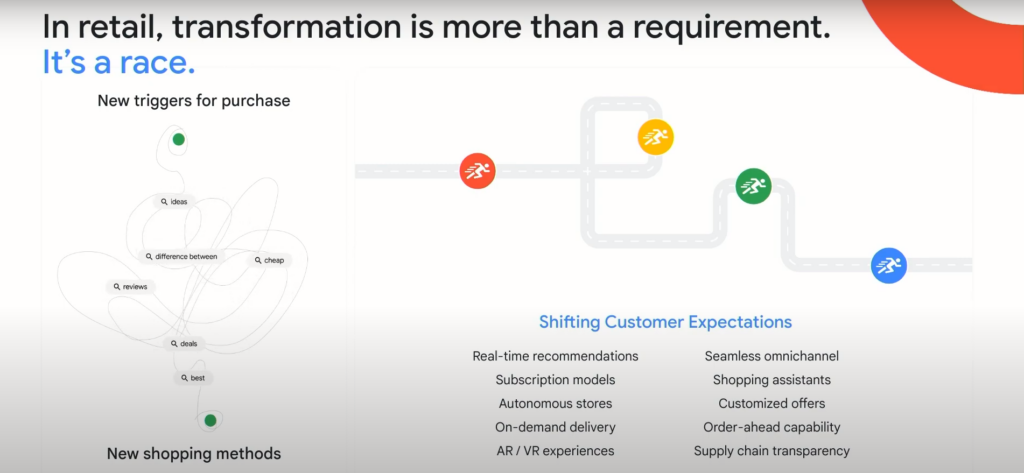
기존에도 상품 추천과 검색을 위해 머신러닝 모델을 사용하고 있었지만, 오늘날 고객(=리테일 기업)들이 요구하는 수준이 더 높아짐에 따라 추천 모델을 자주 변경해야 하는 어려움이 생겨났다. 고객들은 더 높은 수준의 디지털 경험을 요구하고, 모바일/PC 등 플랫폼에 상관없는 개인화된 추천을 원한다. 또한 소비자(=최종 소비자)가 필요한 제품을 언제든 즉시 전달할 수 있는 재고와 제품 관리에 니즈가 있다.
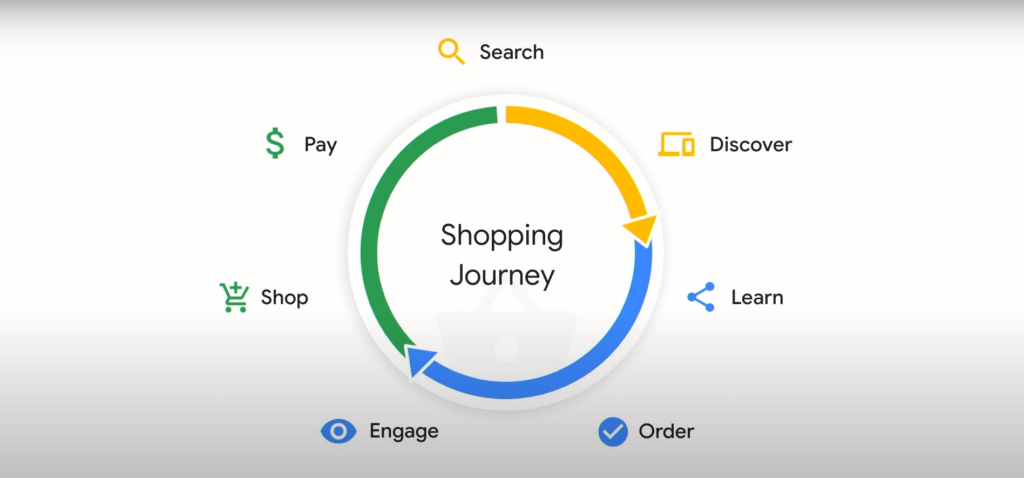
소비자들이 제품을 구매하는 여정은 아래 그림에서 크게 변한 것이 없다.
하지만, 각 단계에서 소비자들이 디지털 도구를 이용하는 양상은 엄청나게 변하고 모양새다. 요즘 소비자들은 IT 기술과 친숙하며 새로운 기술을 적극적으로 사용할 의지를 갖고 있다.
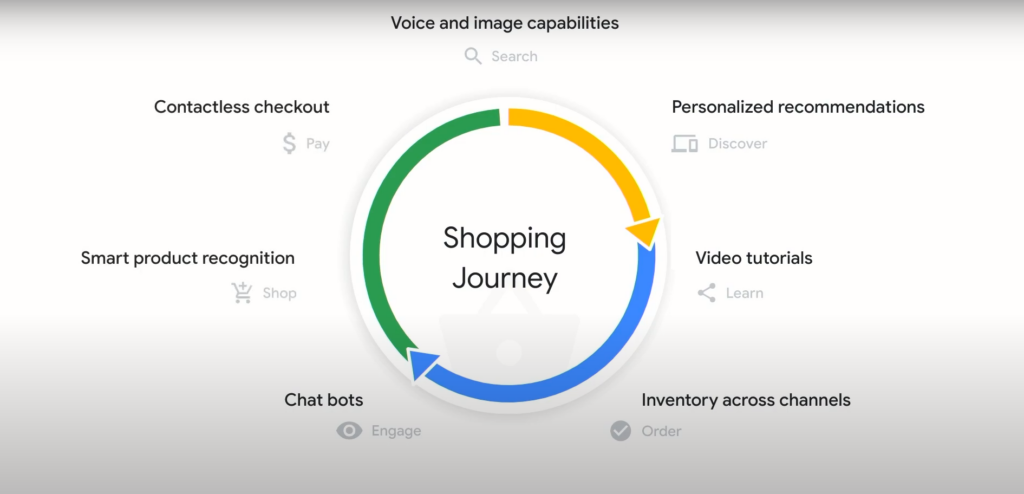
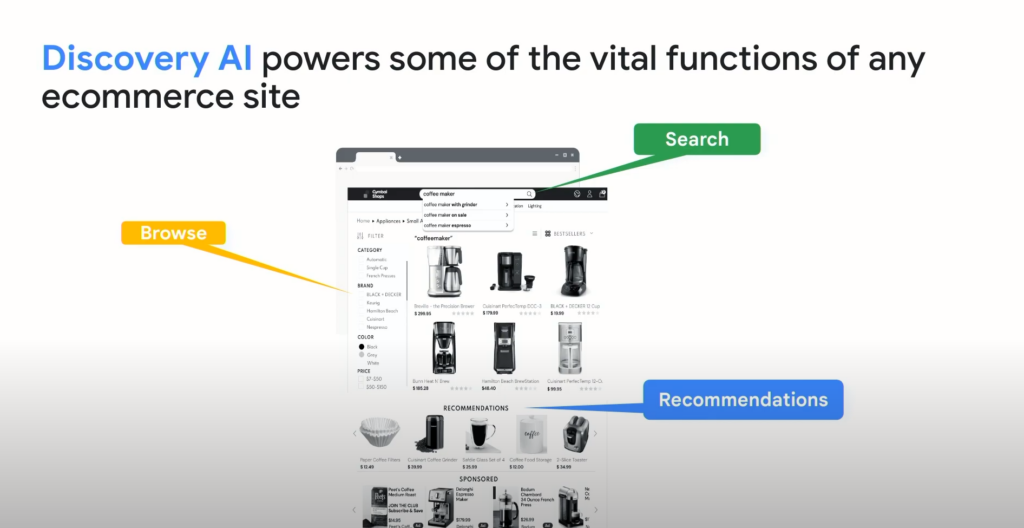
문제는 소비자들의 의도를 온전히 이해하고 소비자가 원하는 개인화 경험을 제공하는 것은 여전히 어렵다는 점이다. 이런 문제들을 해결하기 위해 Google Cloud는 Discovery AI를 제공한다고 밝혔다.
검색, 개인화, 랭킹
Discovery AI가 소비자 경험을 제공하는 과정은 크게 검색, 개인화, 그리고 랭킹으로 나뉜다. 소비자가 검색어를 입력하면, 검색어를 정확하게 이해 후 가장 연관된 결과를 찾고 이를 개인화해 검색 랭킹에 반영한다.
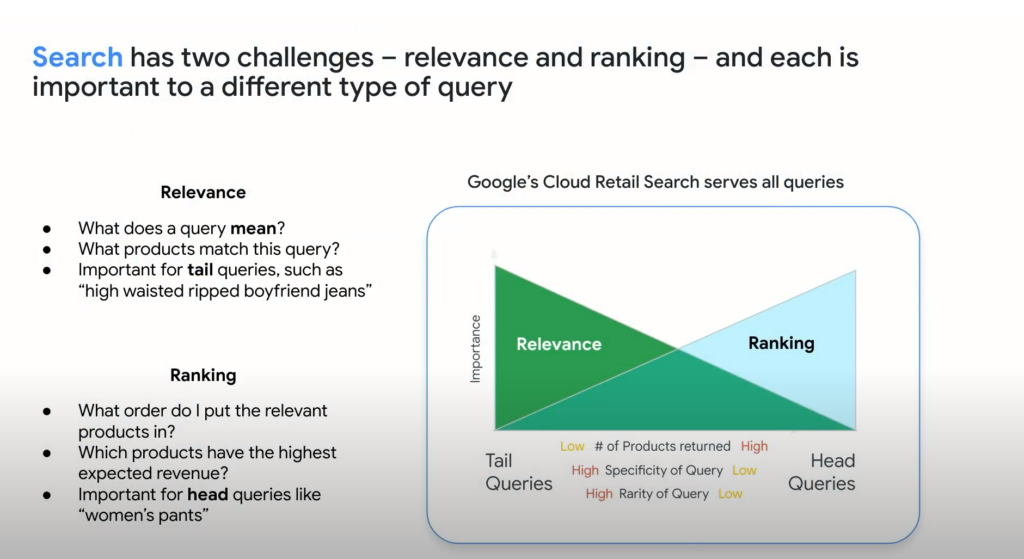
검색은 크게 2가지 문제를 해결해야 하는데, Relevance와 Ranking이다. Relevance는 ‘얼마나 사용자 의도와 일치하는 결과를 보여줄 수 있는가’이며, Ranking은 ‘검색 결과를 어떤 순서로 보여줄 것인가’이다. Relevance는 tail query (사람에 따라 검색량이 제각각인 검색어들, 저빈도 쿼리) 검색 결과에, Ranking은 head query (사람들이 공통적으로 많이 검색하는 검색어들, 고빈도 쿼리) 검색 결과에 영향을 준다.
기존 검색은 단어와 단어 사이의 관련성을 잘 이해하지 못하고, rule-based(사람이 만든 규칙 기반) 검색을 사용하다 보니 새로운 검색어가 등장할수록 검색 품질이 떨어졌다.
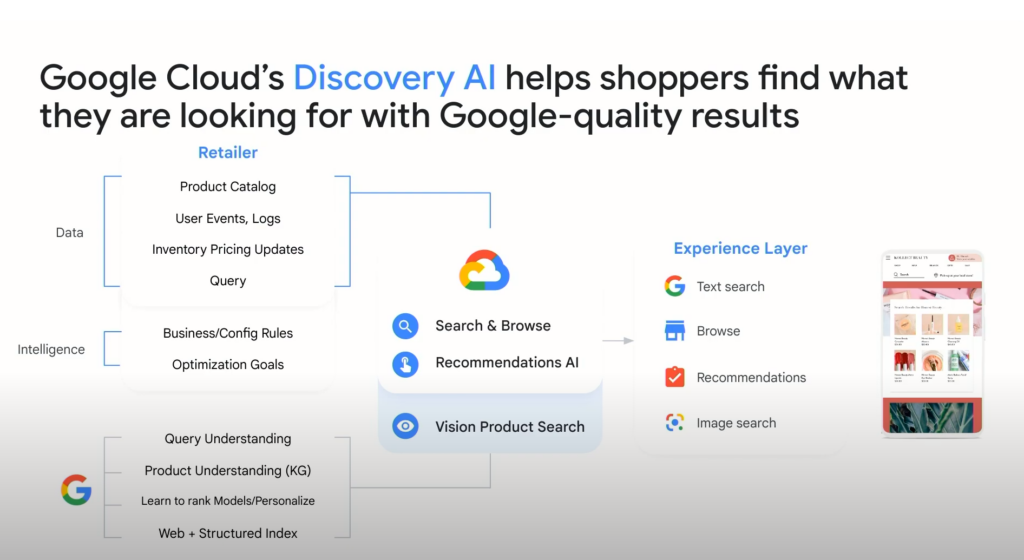
하지만 Discovery AI는 LLM을 사용해 검색에 사용한 단어들을 제대로 이해하고, 정확한 이해를 바탕으로 가장 연관성이 높은 결과를 찾는다(Relevance AI). 그리고 개인화 과정을 거쳐(Personalization AI) 검색 결과(Ranking AI)로 전달하는 구조다.
아무래도 전통적인 방식(=주로 TD-IDF 등 통계적인 방식)의 맹점인 ‘인간이 사용하는 용례대로 단어를 이해하지 못하는 것’을 LLM으로 극복할 수 있다 보니, 검색 결과가 훨씬 더 정확해지는 것은 어쩌면 당연한 것일 수도 있겠다. 아래는 Discovery AI가 검색, 개인화, 랭킹을 서비스하는 구조다.
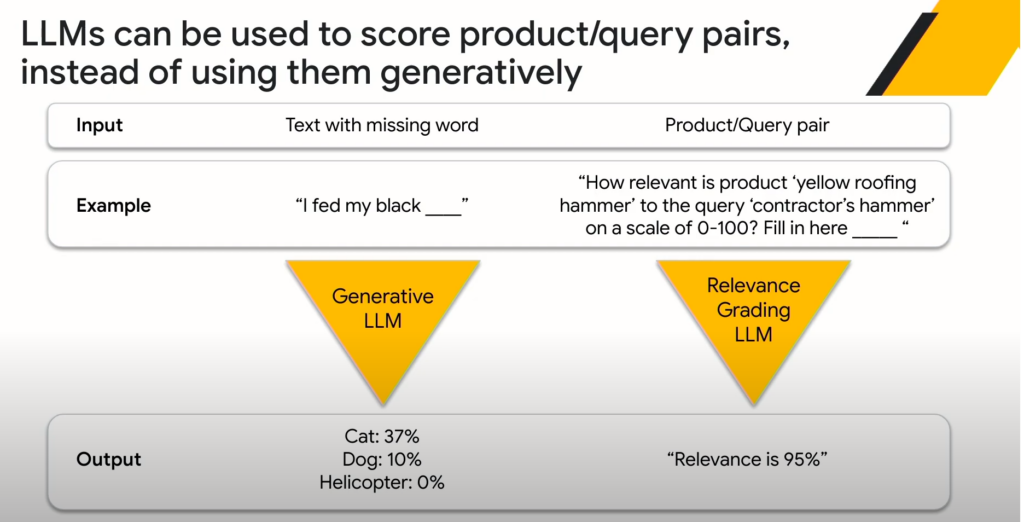
세션을 보면서 LLM을 단순히 검색어 이해(Language AI) 목적으로만 사용하진 않을 것 같다는 생각을 했다. 실제로 세션 후반부에 검색어와 제품 사이의 연관도를 계산(Regression LLM) 하기 위해서 LLM을 사용한다는 설명을 들었다. 프롬프트를 어떻게 구성하느냐에 따라 LLM이 연관도까지 계산해 줄 수 있다는 것이 놀라했다.
메인 스테이지격인 지하 1층을 포함해 사방에서 생성형 AI를 외치고 있었고, 클라우드 기술 자체에 대한 세미나는 별도로 조용한 룸에서 이뤄지고 있었다.
AI 기술을 비즈니스 전면에 내세운 Google의 의지를 느낄 수 있었지만, LLM을 구축하거나 구축하지 않고 이를 클라우드상에서 사용하는 데 드는 비용을 생각해 본다면 기업들은 여러 고민을 하지 않을까 싶었다.
행사장 헬프데스크에 있는 무인 키오스크도 LLM을 탑재하고 있었다. 질문을 던지자 잠시 생각하더니 다소 ‘교과서적인’ 답변을 내놓았다(일론 머스크 xAI의 Grok이 기대되는 이유). 다른 이야기를 하자면, 행사장 내에 와이파이가 끊기니 무인 키오스크가 작동을 바로 멈췄다. 제아무리 LLM이라도 off-grid라면 무슨 소용일지, 모바일 환경이라면 어땠을지 생각이 들었다. AI 성능만큼 중요한 것이 ‘끊김 없는 서비스’를 보장하는 통신 인프라일 것이다.
일정상 마지막 날 세션에 참석하지 못해 아쉬웠다. 후기에서 소개하고 싶은 재미있는 현장 세션들이 더 있지만, 영상이나 자료가 제공되지 않는 세션을 듣다 보니 후기에 쓸 자료를 확보하지 못했다. 그래도 AI 생태계가 태동하는 현장 중심에서 그 열기를 느끼고 돌아오게 되어 기뻤다. 끝으로, 샌프란시스코 날씨는 집에 돌아가기 싫게 만들 정도로 화창하고 선선했다.
샌프란시스코는 여러 이슈에도 불구하고 여전히 활력이 넘치는 도시였고, 세계 각국 다양한 기업에서 온 사람들이 눈을 반짝이며 세션을 듣는 모습을 보니 자연스럽게 동기부여를 받을 수 있어 좋았습니다. 생성형 AI를 클라우드 전면에 도입하는 구글의 시도가 과연 어떤 결과로 이어질지 귀추를 지켜보고 싶습니다.