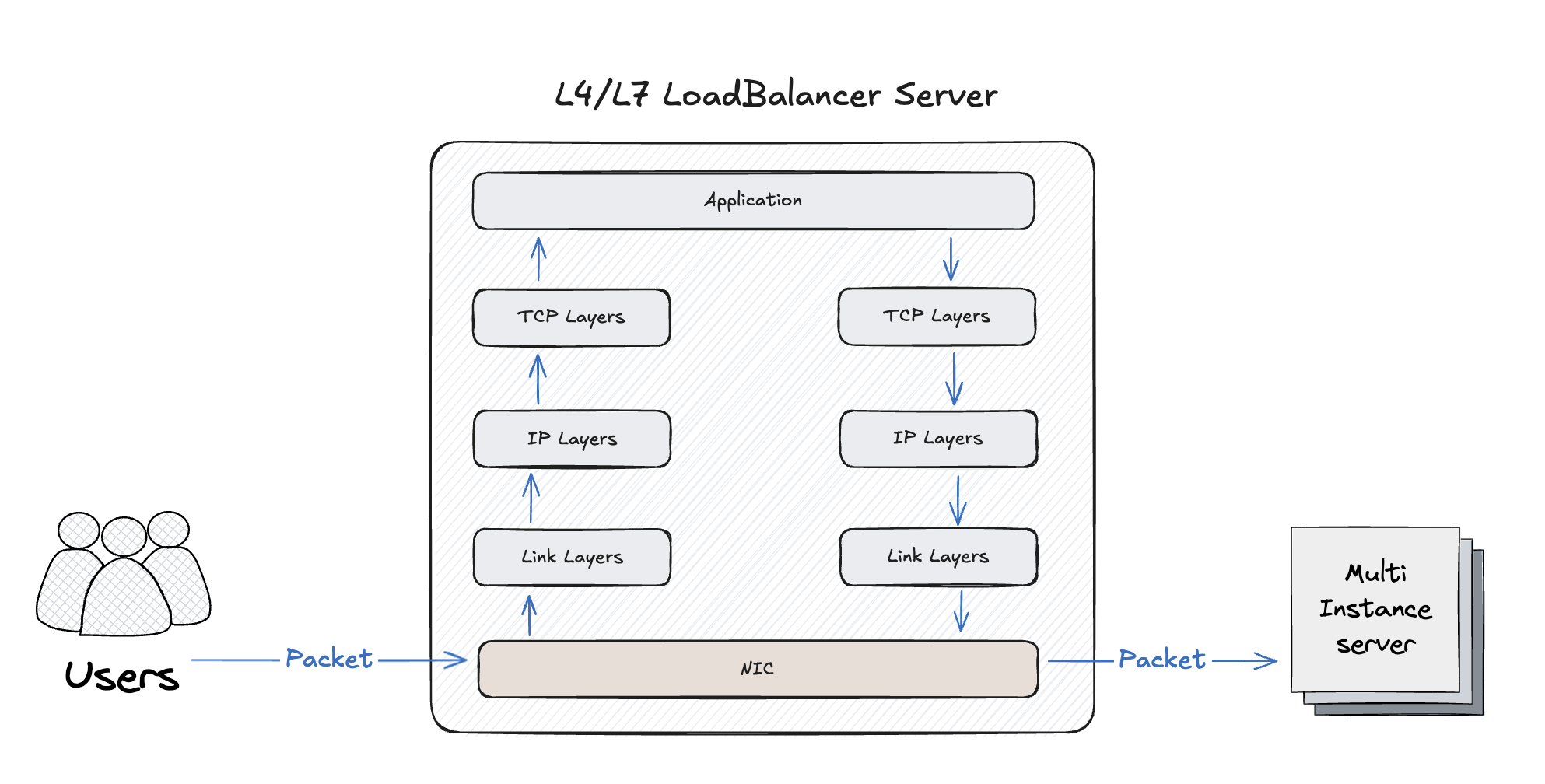
클라이언트의 요청을 여러 개의 멀티 인스턴스 형태 서버에 로드밸런싱하려면, 앞단에서 패킷을 받아 포워딩해주는 로드밸런서 서버가 필요하다. 하지만 일반적인 로드밸런서는 애플리케이션 단까지 패킷을 수신하고 다시 전송하기까지 비용이 크다. NIC에서 수신된 패킷을 기반으로 커널 내에서 SKB를 만들고, 만들어진 SKB는 리눅스 커널 네트워크 스택을 통과한다. 이후 유저 영역의 소켓 버퍼로 메모리를 복사해야 하는데, 이 과정에는 컨텍스트 전환이 포함돼 비용 소모가 크다.
이번 챕터에서는 NIC에서 수신된 패킷을 리눅스 커널 네트워크 스택을 태우지 않고, 유저 영역으로의 메모리 카피도 하지 않는 제로카피 방식으로 원하는 서버로 패킷을 포워딩하는 기법인 eBPF/XDP를 소개한다.
더불어, XDP 기반 로드밸런서가 일반적인 L4, L7 Nginx 로드밸런서 대비 레이턴시(Latency), RPS(초당 요청 처리 수), CPU 사용량 측면에서 어느 정도의 성능 향상을 가져오는지 측정하고 분석해 본다.
본 내용은 XDP를 설명하기 위한 배경 지식이므로, eBPF Virtual Machine이나 Verifier의 상세 동작보다는 역할 위주로 설명한다.
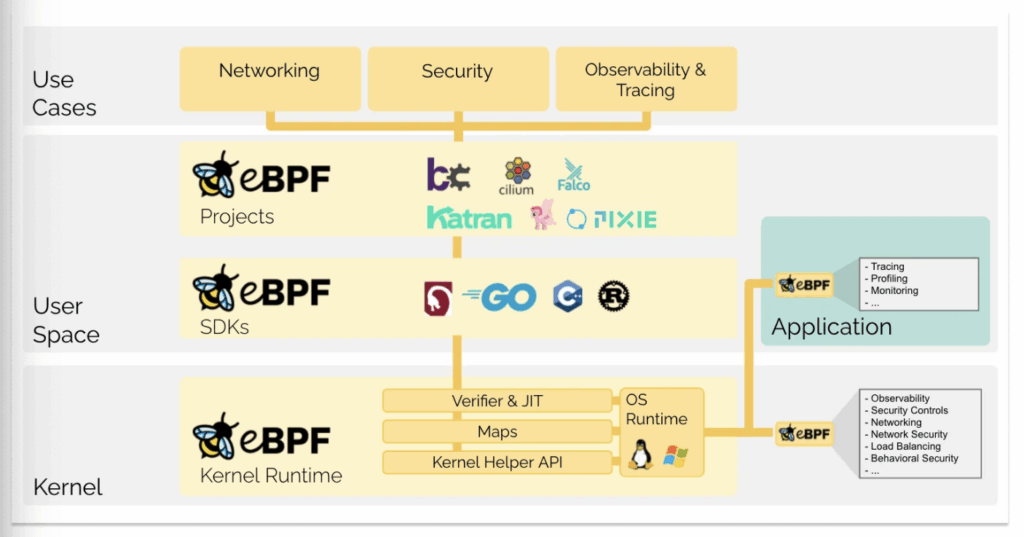
eBPF는 본래 BPF(Berkeley Packet Filter)에서 유래했으나, extended BPF로 발전하며 패킷 필터링을 넘어 관찰 가능성(Observability), 트레이싱(Tracing), 보안 등 다양한 기능을 수행하게 되었다. 이제는 약어로서의 의미보다 독립적인 기술 용어로 통용된다.
eBPF 프로그램은 이벤트 기반으로 동작하며, 커널이나 애플리케이션이 특정 훅(Hook) 지점을 통과할 때 실행된다. 주요 훅 지점은 다음과 같다.
System Calls
Kernel/User Tracing
Network Events
Function Entry/Exit
eBPF 프로그램은 커널 공간(Kernel Space)에서 동작하기 때문에 안정성이 매우 중요하다. 따라서 엄격한 Verifier(검증기)를 통해 코드에 위험 요소(예: 패킷 포인터 접근 시 경계 초과 등)가 없는지 확인한 후, JIT Compiler를 통해 실행된다. 검증기의 제약으로 인해 일반적인 함수 사용이 제한되므로, eBPF는 특수한 형태의 커널 헬퍼 함수(Helper Function)를 제공한다.
즉, eBPF는 크게 BPF MAP, Virtual Machine, Verifier 세 가지 핵심 요소로 구성된다.
XDP(eXpress Data Path)
XDP(eXpress Data Path)는 프로그래밍 가능한 패킷 처리 기술이다. 과거에 많이 언급되던 DPDK는 커널을 우회하기 때문에 보안과 안정성을 보장하기 어렵다는 한계가 있었다. 반면 XDP는 eBPF 프로그램이 검증기와 JIT을 통해 커널 공간에서 안전하게 실행된다. 또한 XDP는 리눅스 커널의 일부로 구현돼 있어 리눅스 네트워크 스택과 완전히 통합된다.
그렇기 때문에 프로그래머는 커널과 사용자 공간 사이의 컨텍스트 전환 없이(Native 기준), 패킷이 NIC에 도착해 CPU에서 처리되는 가장 빠른 시점에 XDP 프로그램을 실행해 패킷 처리 결정 또는 조작 등을 구현할 수 있다.
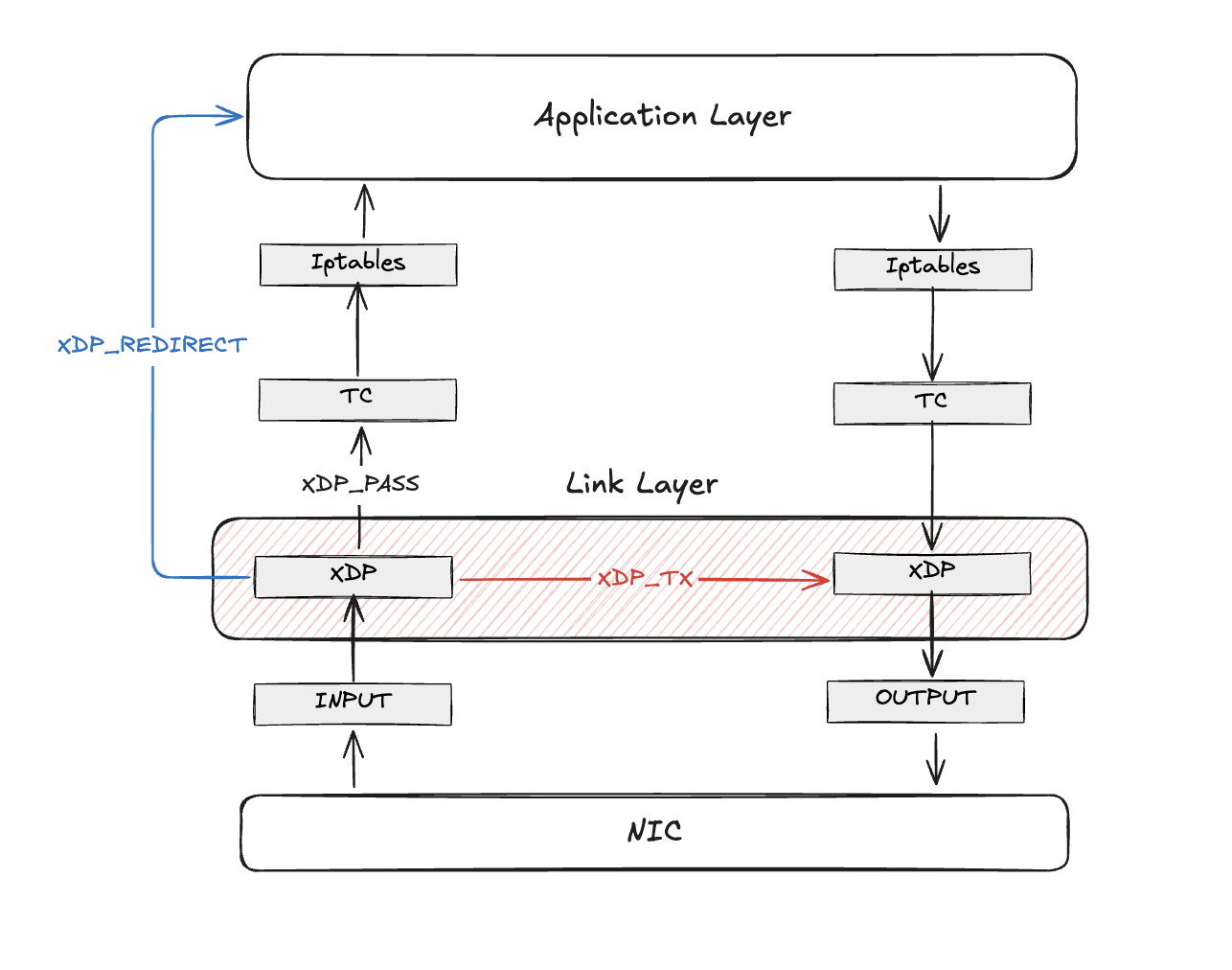
작성된 XDP 프로그램은 종료 시 Action이라는 정수형 반환값을 필요로 하며, 지원되는 값은 다음과 같다.
XDP_ABORTED: 패킷을 DROP 함과 동시에 예외(Exception)를 발생시킨다.
XDP_DROP: 패킷을 즉시 폐기한다.
XDP_PASS: 패킷을 리눅스 커널의 네트워크 스택으로 올려 보낸다.
XDP_TX: 수신했던 NIC로 패킷을 다시 내보낸다. (로드밸런서 구현의 핵심)
XDP_REDIRECT: 패킷을 다른 NIC, 다른 CPU, 또는 사용자 공간(AF_XDP)으로 전달한다.
Note: XDP_REDIRECT는 다른 Action과 달리 별도의 BPF Helper 함수를 필요로 한다.
위 그림에서 알 수 있듯이, XDP_REDIRECT는 커널 네트워크 스택을 우회해 다른 대상으로 전달하고, XDP_PASS는 기존처럼 커널 네트워크 스택을 타도록 한다. XDP_TX는 수신했던 NIC로 패킷을 재주입한다. XDP 로드밸런서가 XDP_TX 액션 값을 이용해 패킷을 Link Layer에서 처리한다는 점에서 매우 중요한 개념이다.
XDP 실행 흐름과 Veth (Virtual Ethernet)
XDP가 무엇인지는 대략 감이 와도 “어디서, 어떻게 동작하는지”는 바로 와닿지 않을 수 있다. 실제로 XDP Program이 실행되는 과정을 짧게 살펴본다. 사용되는 시스템은 실제 호스트가 아닌 가상머신(virtual machine)과 가상이더넷(veth) 기반으로 진행할 예정이므로, 리눅스 커널의 veth를 중심으로 살펴본다.
또한 실제 XDP 프로그램을 veth에 attach할 예정인데, veth에 XDP 프로그램이 붙었는지 여부에 따라 동작이 달라진다. 이 부분도 집중적으로 살펴본다. XDP에는 Native와 Generic 모드가 존재하며, Generic 모드는 간단히만 보고 실제 구현과 동작은 Native 모드를 기준으로 진행한다.
XDP INSTALL & ATTACH
XDP 프로그램을 네트워크 인터페이스에 설치(Install)하고 연결(Attach)하는 커널 내부 로직을 살펴보자.
dev_XDP 프로그램을 설치하면 dev_xdp_attach를 호출해 XDP를 붙이는데, 이때 dev_xdp_mode를 통해 XDP 동작 모드를 Generic 또는 Native 중 하나로 선택한다. dev_xdp_install 내부에서 Generic의 경우 generic_xdp_install을 호출해 generic_xdp_needed_key 값을 세팅한다.
Generic 모드에서 해당 값이 세팅되면 __netif_receive_skb_core → do_xdp_generic을 호출해 XDP 프로그램을 실행한다. 함수 구조상 sk_buff 할당 이후에 실행되기 때문에, 일반적으로 알려진 “sk_buff 할당 이전에 실행되는 Native 모드”와 차이가 있고 성능도 떨어진다. 다만 모든 드라이버에서 동작 가능하다는 장점이 있어 테스트 환경 구성에는 유용하다.
그 외의 경우에는 ndo_bpf에 연결된 함수 포인터를 호출한다. virtio_net은 virtnet_xdp, veth는 veth_xdp가 된다. 실제 로드밸런서 구현에서 XDP 프로그램이 실행되는 곳은 veth이므로 이 구간을 살펴본다. NAPI는 아래 링크를 참고하면 좋다.
veth_xdp에서 타고 들어가면 veth_enable_xdp_range를 확인할 수 있다. 이 구간을 통해 NAPI poll 함수 포인터에 veth_poll이 등록된다. 즉, NAPI가 활성화되고 polling 함수로 veth_poll을 사용한다는 의미다. 지금은 XDP 설치 및 실행 흐름이 핵심이므로, NAPI 자체에 대한 깊은 설명은 생략한다.
kprobe를 사용해 veth_enable_xdp_range가 호출되는 시점에 커널 스택을 출력했다. 이 역시 eBPF 기반 커널 트레이싱 도구이며, 여기서도 eBPF의 편리함과 강력함을 확인할 수 있다.
여기까지가 XDP 프로그램을 attach했을 때의 로직이다. NAPI 관련은 보여야 할 내용이 많아, 기회가 된다면 다른 챕터에서 다루고 싶다.
번외) veth가 Native XDP를 지원하나요? 2018년 커널 패치를 통해 veth 드라이버에도 Generic이 아닌 Native XDP 지원이 추가되었다. 상세 내용은 [Merge branch ‘bpf-veth-xdp-support’] 커밋을 참고하기 바란다.
XDP EXECUTION Flow
로드밸런서를 구현하려면 XDP_PASS가 아니라 XDP_TX를 Action으로 반환하고, 패킷을 실제 서버로 전송해야 한다. 따라서 설치된 XDP 프로그램이 실행되는 구간과 XDP_TX를 반환했을 때의 동작 구조를 살펴볼 필요가 있다.
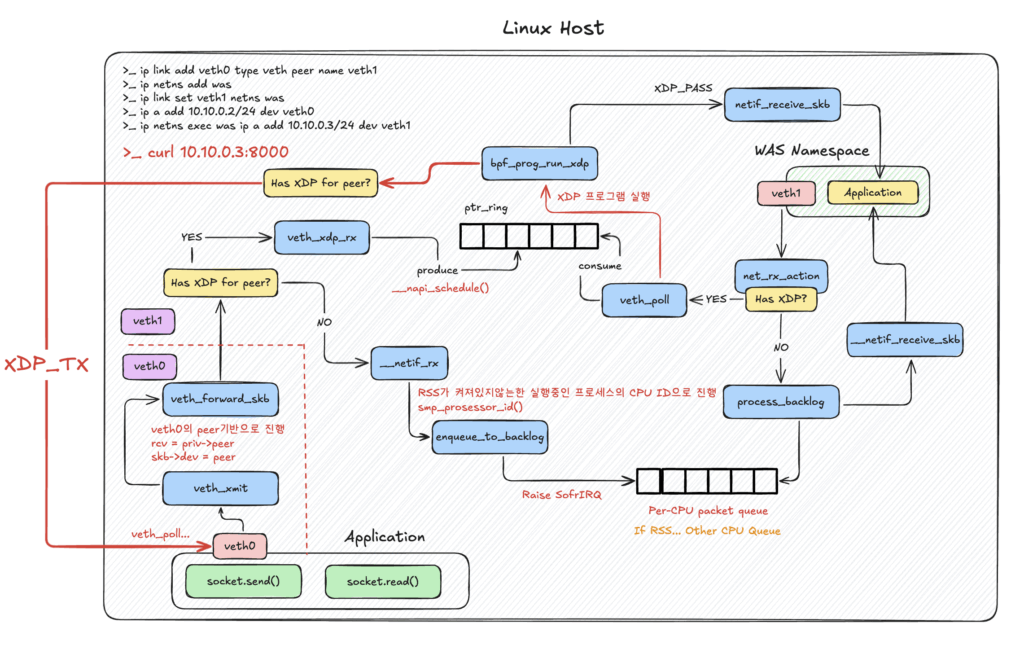
패킷 처리 과정에서 XDP Program을 실행시키는 공통 흐름은 bpf_prog_run_xdp 호출로 이어진다. veth 기준으로 해당 함수가 실행되기까지를 설명하자면 다음과 같다. 아래와 같이 was라는 network namespace를 만들고 veth를 배정한다.
# was라는networknamespace를만든다.$sudoipnetnsaddwas# veth0, veth1쌍을생성한다.$sudoiplinkaddveth0typeveth peer name veth1# veth1를 was network namespace에 배정한다.$ sudo ip link set veth1 netns was# 배정 확인$ sudo ip netns exec was ip link# veth0에 10.10.0.2 IP 주소를 부여한다. veth1에도 10.10.0.3을 부여한다.$ sudo ip a add 10.10.0.2/24 dev veth0$ sudo ip netns exec was ip a add 10.10.0.3/24 dev veth1# veth0, veth1 up으로 변경한다.$ sudo ip link set dev veth0 up$ sudo ip netns exec was ip link set dev veth1 up# 삭제$ ip netns del was### 1$ sudo ip link13: veth0@if12 UP 0a:31:b3:03:2a:a9 <BROADCAST,MULTICAST,UP,LOWER_UP>### 2$ sudo ip netns exec was ip linklo UNKNOWN 00:00:00:00:00:00 <LOOPBACK,UP,LOWER_UP>12: veth1@if13 UP fe:2d:16:44:5c:c4 <BROADCAST,MULTICAST,UP,LOWER_UP>
ifindex가 각각 13, 12로 출력된다. 이 상태에서 was 네임스페이스에서 웹서버를 실행한다.
패킷 전송 시 콜스택을 보면 기본적으로 상위 레이어부터 dev_hard_start_xmit → xmit_one → netdev_start_xmit → __netdev_start_xmit → ndo_start_xmit 흐름을 수행한다. ndo_start_xmit 함수 포인터는 앞에서 설명했듯 veth_xmit과 연결된다.
veth_xmit의 두 번째 인자인 struct net_device *dev는 전송자인 veth0이다. 내부에서 peer(veth1)를 꺼내 rcv에 저장한다.
XDP가 꺼져 있는 일반 경우: __netif_rx가 호출되고 내부적으로 enqueue_to_backlog()가 실행돼, 패킷을 처리 중인 CPU의 백로그에 패킷을 넣는다. 그 CPU에 SoftIRQ를 트리거해 peer(veth1)의 net_rx_action이 트리거되고 process_backlog()가 호출돼 패킷을 처리한다. 물론 RSS가 켜져 있다면 다른 CPU로 이동 처리도 가능하다.
XDP가 설치된 경우: veth_xdp_rx를 호출하고 ptr_ring 버퍼에 패킷을 주입한다.
/* drivers/net/veth.c */staticintveth_xdp_rx(structveth_rq *rq, structsk_buff *skb){if (unlikely(ptr_ring_produce(&rq->xdp_ring, skb)))returnNETDEV_TX_BUSY; /* signal qdisc layer */returnNET_RX_SUCCESS; /* same as NETDEV_TX_OK */}
어느 경우든 패킷을 주입한 뒤 __napi_schedule()을 호출해 SoftIRQ가 raise된다. XDP가 붙어 있다면 veth_poll, 아니라면 process_backlog가 호출돼 수신된 패킷을 처리한다.
여기서 중요한 포인트는 다음이다.
__napi_schedule() 호출은 veth0(전송자) 측에서 발생한다.
veth_poll 또는 process_backlog 호출은 veth1(수신자) 측에서 발생한다.
veth_xdp_rcv는 __ptr_ring_consume로 xdp_ring에서 데이터를 소비한다. 소비된 데이터는 veth_xdp_rcv_one 또는 veth_xdp_rcv_skb를 호출하며, 두 함수 모두 내부적으로 bpf_prog_run_xdp를 호출해 실제 XDP 프로그램을 실행한다.
XDP_PASS면 netif_receive_skb 등으로 커널 네트워크 스택 처리를 진행한다.
/* drivers/net/veth.c */staticintveth_xdp_xmit(structnet_device *dev, intn,structxdp_frame **frames,u32flags, boolndo_xmit){[...]/* The napi pointer is set if NAPI is enabled, which ensures that * xdp_ring is initialized on receive side and the peer device is up. */if (!rcu_access_pointer(rq->napi))gotoout;[...]for (i = 0; i < n; i++) {structxdp_frame *frame = frames[i];void *ptr = veth_xdp_to_ptr(frame);__ptr_ring_produce(&rq->xdp_ring, ptr); }[...]}staticvoidveth_xdp_flush_bq(structveth_rq *rq, structveth_xdp_tx_bq *bq){[...]sent = veth_xdp_xmit(rq->dev, bq->count, bq->q, 0, false);[...]}staticvoidveth_xdp_flush(structveth_rq *rq, structveth_xdp_tx_bq *bq){[...]veth_xdp_flush_bq(rq, bq);rcv = rcv_dereference(priv->peer); // veth1이 수신이라면 상대는 veth0rcv_rq = &rcv_priv->rq[veth_select_rxq(rcv)];[...]__veth_xdp_flush(rcv_rq);}
여기서 혼동하기 쉬운 지점이 있다. 수신 측 가상 이더넷이 veth1이고 XDP_TX 상황이라면, veth1의 peer인 veth0을 꺼내 rcv에 저장한다. 그리고 전송할 데이터를 veth0에 주입해 veth0에서 veth_poll이 트리거되도록 만든다. 즉, veth1에만 XDP가 설치되면 안 된다. XDP_TX를 쓰려면 veth0, veth1 페어 모두 XDP가 설치돼야 하는 이유다.
이 함수 구간을 통해, 처음 말한 XDP_TX가 어떻게 수신했던 NIC로 패킷을 되돌리는지 확인할 수 있다.
veth는 터널링 개념이 있다는 걸 알면서도, 대부분 “veth1로 전송하면 바로 veth1로 가겠지”라고 생각하기 쉽다. ‘수신했던 네트워크 인터페이스로 돌려보낸다’고 하면 veth1을 떠올리는 것도 자연스럽다. 하지만 코드와 결과는 그렇게 단순하지 않다.
veth826ee2b와 pair인 eth0를 만들고, eth0는 네트워크 네임스페이스로 격리한 뒤 XDP_TX를 반환하는 XDP 프로그램을 붙인다. 또한 veth826ee2b에도 XDP_PASS를 반환하는 XDP 프로그램을 똑같이 붙인 뒤 아래 명령을 실행한다. 그리고 nc로 3-way handshake만 진행하는 패킷을 전달한다.
veth_xdp_xmit는 앞서 말했듯 XDP_TX를 리턴하면 호출되는 함수다. 3-way handshake는 클라이언트와 서버 간 3개의 패킷을 주고받으므로, 중간 로드밸런서에서 bpftrace를 걸었을 때 veth_xdp_xmit가 3번 모두 eth0로 찍히는 건 자연스럽다.
veth_poll 트레이싱 결과를 보면, 클라이언트가 로드밸런서로 패킷을 줬을 때 veth_poll이 트리거된다. 그리고 앞서 말했듯 XDP_TX를 반환하면(가상 이더넷 기준) 자신이 수신했던 인터페이스의 peer에게 패킷을 주입하고 __napi_schedule()을 호출해 peer의 veth_poll 호출을 유도한다. veth826ee2b 인터페이스에서는 변경된 MAC 주소 기반으로 브릿지를 통해 원하는 가상 인터페이스로 프레임이 전달된다. 이 부분은 XDP와 veth를 넘어서는 내용이므로 여기서는 다루지 않는다.
참고로 다른 조작된 패킷(MAC 주소)을 전송하는 함수는 br_handle_frame이다. 분석은 따로 하지 않고 넘어간다.
여기까지가 XDP 프로그램을 설치하고 XDP_PASS, XDP_TX일 때의 간략한 동작 과정이다. 앞서 언급했듯 XDP는 커널 내부 소스와 통합돼 있어 커널 안정성 기반으로 동작할 수 있다. 다만 드라이버마다 Native 모드 지원 여부는 다르며, 지원되지 않는 드라이버는 Generic 모드를 사용해야 한다.
NAPI, 네트워크 스택 등 실제 네트워크 구조에 대한 설명은 여러 부분 생략했다. 그 과정에서 예상치 못한 잘못된 내용이 있을 수 있으나, 큰 흐름을 이해하기 위한 구조로 봐주면 좋겠다.
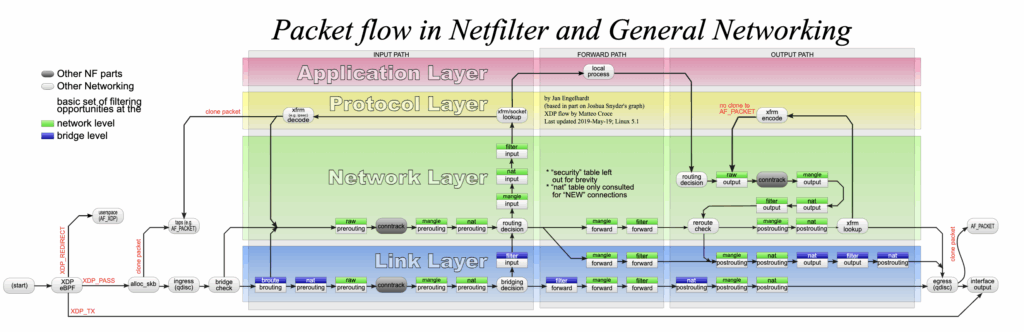
위 그림은 지금까지 설명한 내용을 한 장으로 정리한 것이다. 제한된 공간에 담다 보니 네트워크 스택은 대체로 생략했다.
지금까지 XDP를 간단히 살펴봤다. 이제 이 글의 목적인 XDP 로드밸런서를 구현하고 테스트한다. XDP 로드밸런서는 2가지 방식과 DSR 방식이 존재하는데, DSR은 다음 기회에 살펴본다.
이번에 진행하는 방식은 구현 난도가 가장 낮은 방식이지만, 성능 측면에서 다음에 다룰 DSR(Direct Server Return) 방식보다는 좋지 않다.
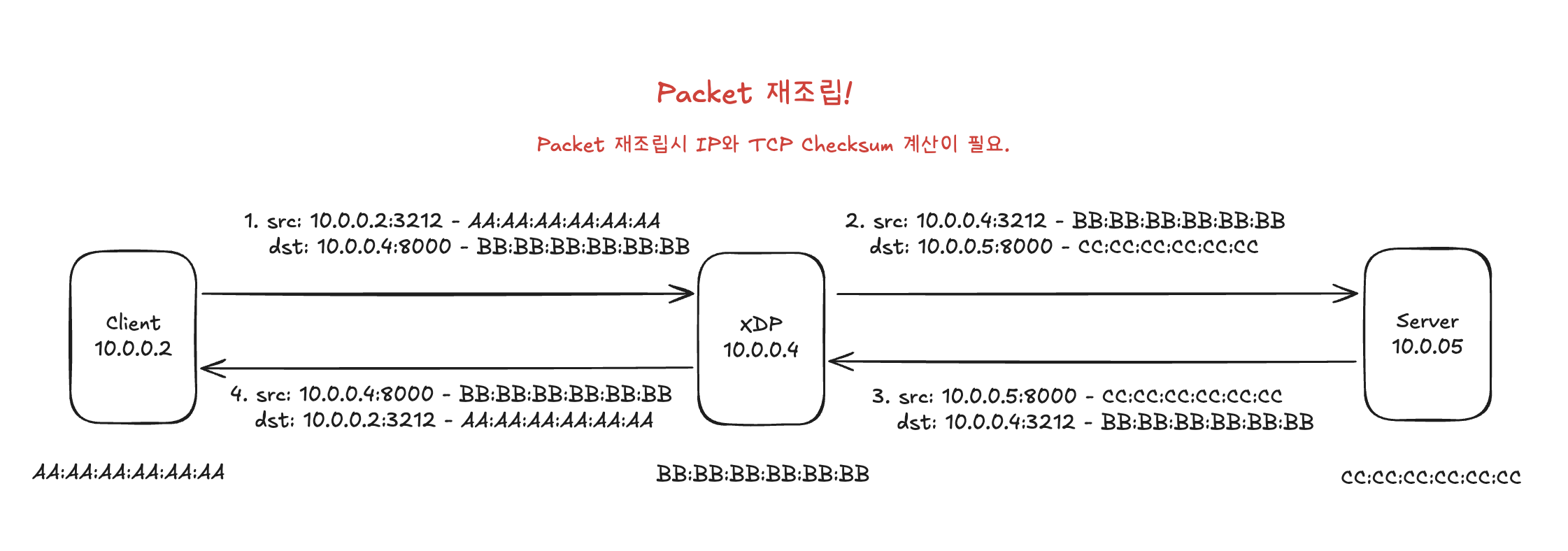
위 모델은 XDP 로드밸런서를 구현할 때 베이스가 되는 구조라고 생각한다. XDP는 NIC에서 패킷 수신 후 리눅스 네트워크 스택에 진입하기 전에 실행되므로, ethernet frame, ip, tcp header 및 option 처리까지 필요하다.
XDP 프로그램이 트리거된 패킷은 목적지가 로드밸런서 쪽으로 돼 있기 때문에, 이를 원하는 서버 목적지 정보로 바꿔줘야 한다. 또한 IP Header, TCP Header가 수정되므로 각 checksum도 재계산해야 한다. 그리고 로드밸런서가 클라이언트와 서버 간 커넥션을 어떻게 유지할지도 중요하다. 아래 챕터에서 조금 더 자세히 살펴본다.
위 구조를 기반으로 Cilium eBPF를 사용해 코드 레벨 설명을 한다. 다만 설명을 위해 전체 코드가 아니라 부분적으로만 다룬다.
실제 내용을 진행하기 전에, eBPF에는 Verifier라는 검증기가 있다는 점을 다시 강조한다. XDP 프로그램 개발 시 패킷 데이터를 직접 접근·수정해야 하는데, 반드시 “접근 가능한 범위인지”, “경계를 넘지 않는지” 조건 검사를 기반으로 프로그래밍해야 한다.
데이터 자료구조 (BPF MAP)
로드밸런서는 클라이언트와 직접 커넥션을 맺지 않는다. 그런데 서버로 포워딩할 때 서로 다른 클라이언트가 동일한 소스 포트를 들고 오면, 포트 충돌로 TCP Sequence가 꼬일 수 있다. 그래서 로드밸런서 측은 클라이언트 소스 포트가 아니라 로드밸런서가 사용할 고유 포트를 하나 확보해 포워딩해야 한다.
클라이언트가 서버에 접속하려면 먼저 로드밸런서 주소에 접근한다. TCP라면 TCP 3 Way Handshake를 진행한다. 로드밸런서의 목적은 클라이언트와 3WH로 커넥션을 맺는 게 아니라, 패킷을 Forward하는 것이다. 그래서 3WH를 대상 서버와 진행할 수 있게 도와줘야 한다.
클라이언트가 첫 TCP 커넥션 요청을 하면 SYN 패킷을 보낸다. 로드밸런서 측에서 TCP header를 파싱했을 때 SYN 플래그가 켜져 있다면 첫 커넥션으로 보고 해시 테이블에 등록한다.
RST는 맵에서 바로 삭제한다. FIN은 TCP 종료 절차를 고려해 클라이언트/서버 모두 FIN을 전송하고 ACK를 수신한 뒤 삭제한다.
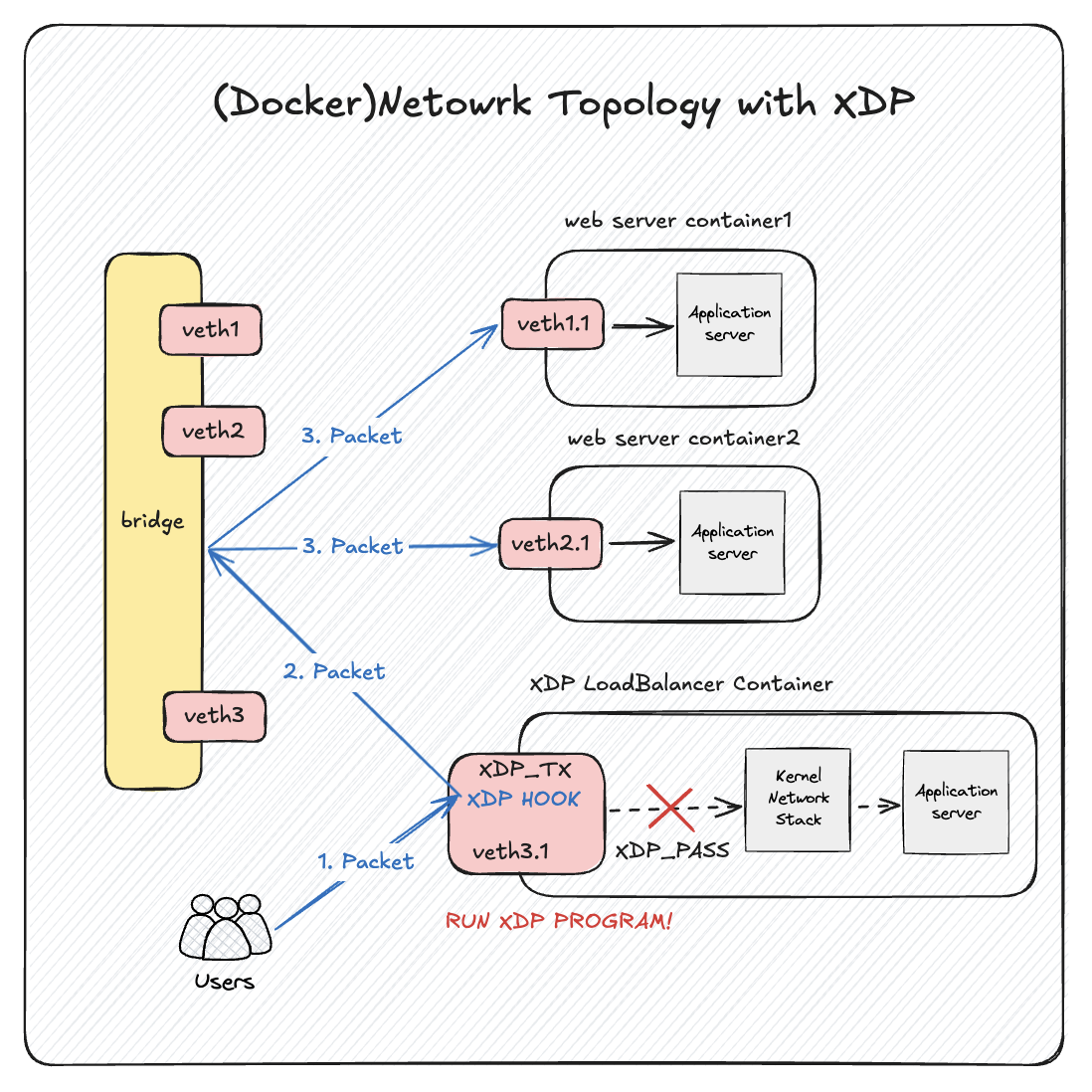
위 그림은 로드밸런서 동작을 한 장으로 표현했다. 클라이언트(Users)가 로드밸런서 컨테이너로 패킷을 전송하면, 로드밸런서의 가상 네트워크 인터페이스(NIC-veth)에 패킷이 도착한다. 도착한 패킷은 XDP hook에 설치된 XDP 프로그램이 실행되며 MAC/IP/Port를 수정하고 XDP_TX를 반환한다. 그러면 도착했던 NIC로 재주입되고, 수정된 헤더 정보 기반으로 목표 서버로 포워딩된다. 반대로 로드밸런서가 XDP_PASS를 반환하면 로드밸런서의 커널 네트워크 스택을 타게 되고 iptables나 애플리케이션에서 처리된다.
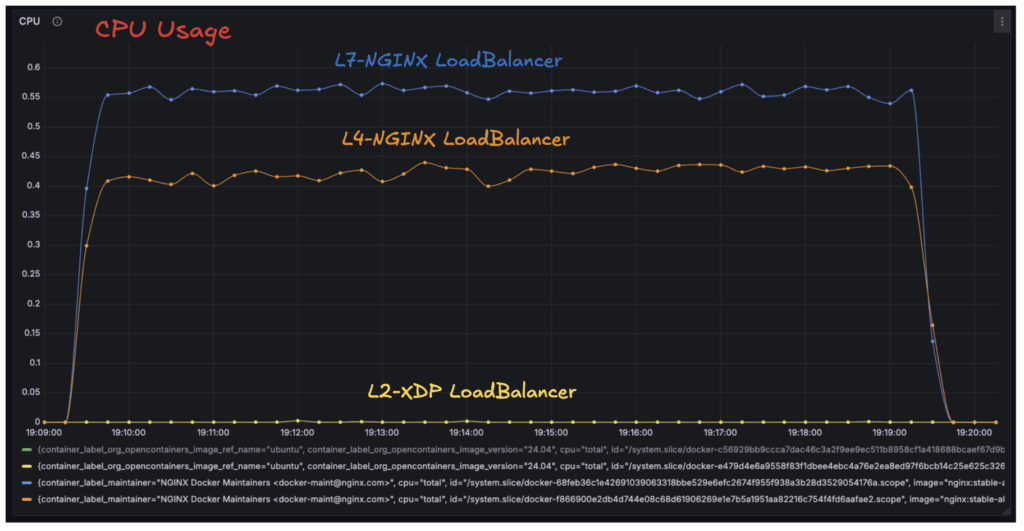
가상 유저 1000명, 전체 요청 3,000,000 기준으로 XDP 로드밸런서는 L7-NGINX, L4-NGINX 대비 각각 P50 기준으로 72.8% 감소, 30.7% 감소를 확인했다. 초당 요청 수는 각각 343.6%, 71% 증가율을 보였다.
리소스 사용량
VUs 100, Duration 10m / VUs 1000, Duration 10m
Container
CPU
Memory
CPU
Memory
L7-NGINX
0.574
6.96M
0.588
16.5M
L4-NGINX
0.440
5.32M
0.53
11.3M
L2-XDP
0.003
26.1M
0.0045
23.4M
VUs 3000, Duration 10m / VUs 5000, Duration 10m
Container
CPU
Memory
CPU
Memory
L4-NGINX
0.621
16.8M
0.672
15.6M
L2-XDP
0.0065
23.5M
0.0247
23.1M
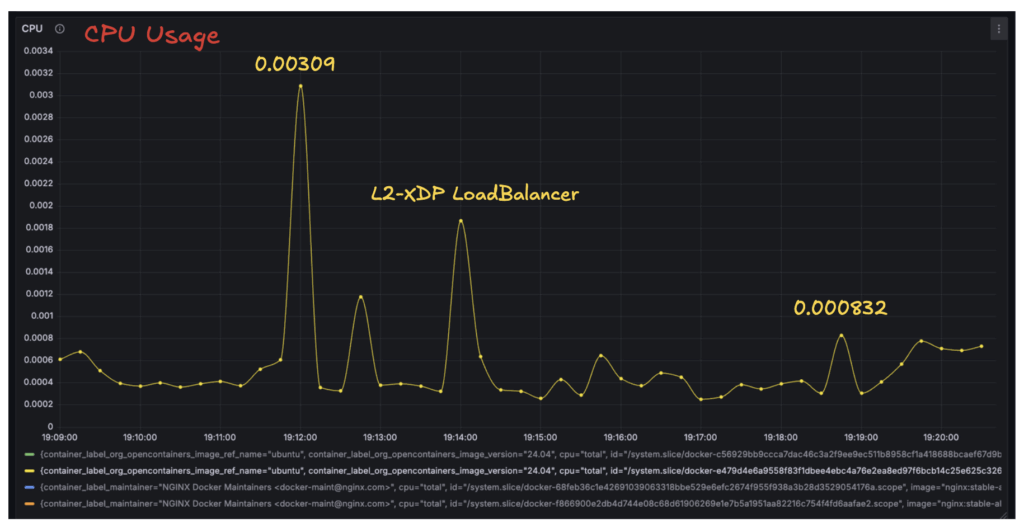
리소스 사용량은 XDP가 앞선 이론에서 설명했듯(Native XDP 기준) 패킷이 NIC에 도착하고 CPU 처리의 가장 빠른 시점에 처리되기 때문에 CPU 사용량이 현저히 낮다는 점을 확인했다.
로드밸런서별 CPU 사용량로드밸런서의 CPU 사용량
한계
제시한 로드밸런서 디자인은 Direct Server Return 방식이 아닌 NAT 방식으로 구성돼 있어, 성능 향상을 추가로 도모할 여지가 있다. 또한 단일 노드에서만 동작 가능하며 쿠버네티스 배포 시 다른 노드로 포워딩하는 디자인 모델을 제시하지 않았기 때문에 한계가 있다.
완전히 L2 레이어에서만 동작 중인 XDP 로드밸런서는 ingress에서만 XDP 프로그램 실행이 가능하고 egress에서는 불가능하다. 이는 TC 레벨에서 추가 작업이 필요함을 의미한다.
결론
NIC에 도착한 패킷을 처리하려면 커널 네트워크 스택을 거쳐 유저 스페이스 영역까지 패킷 데이터를 복사해야 한다. 전송 시에는 역과정으로 또 한 번 진행된다. 이 오버헤드는 불필요하다. 패킷을 수신 즉시 로드밸런싱 처리해 커널 네트워크 스택을 태우지 않고 전송한다면, 오버헤드가 줄어 레이턴시와 리소스 사용량도 자연스럽게 줄어든다.
이 개념은 쿠버네티스에서 kube-proxy 구현에도 적용될 수 있음을 시사한다.
요약
일반적인 로드밸런서나 쿠버네티스의 iptables, ipvs는 공통적으로 네트워크 스택을 타며, 패킷 메모리 카피가 발생하는 순간이 있다. XDP 프로그램은 NIC에서 오프로딩돼 실행될 수 있고, 네트워크 스택을 거치지 않기 때문에 일반적으로 빠르다고 볼 수 있다.
다만 단일 시스템에서 network namespace만 나눈 상태에서 진행한 테스트라 CPU 사용량까지 더 정교한 의미로 해석하기 어려웠던 점은 아쉽다. eBPF/XDP는 지금도 발전 중이며 커널 코드에 많은 기여가 발생하고 있다는 점은 분명하다. 추후 활용 사례가 더 늘어날 것이라고 생각한다.
eBPF/XDP는 매우 강력한 기술이지만 제대로 쓰이기 위해서는 리눅스에서 NIC에서 패킷을 수신하고 처리하는 과정에 대해서 대략적으로 알아야 할 필요가 있다고 생각했기에 관련 설명을 추가했다. 이 글이 컨테이너화 시대에 XDP라는 기술을 사용하고 이해하는 데 도움이 되었으면 한다.
리눅스 커널 코드의 이야기는 매우 방대해 보는 관점에 따라 다르게 해석될 여지가 있기에 완전 신뢰가 아닌 참고용으로 봐주었으면 한다.