Google Cloud Next 2023은 매년 미국 샌프란시스코 모스콘 센터를 중심으로 열리는 Google의 행사다. 2019년 이후 코로나19로 대면 행사가 중단됐다가 이번에 다시 열렸다. 행사에서는 주로 인프라, 데이터와 AI, 워크스페이스(Workspace) 협업 및 사이버 보안 솔루션 등의 주제가 다뤄졌다. 8/29 ~ 8/31 진행된 행사 중 기자는 개인 일정상 8/29, 8/30 이틀간만 참석했다.
8/28 – 샌프란시스코 도착
기자는 공항을 빠져나와 미리 모스콘 센터에 들려 Google Cloud Next 2023 행사 Pass 티켓을 구매했다. 샌프란시스코로 내딛는 발걸음은 가벼웠다. 환상적인 날씨를 자랑했고, 요즘 뉴스에서 오르내리는 이슈들에도 불구하고 역시나 다시 방문하고 싶은 도시라는 생각이 가장 먼저 들었다.
8/29 – Google Cloud Next 2023 첫째날
연사 목록에 없었던 순다 피차이 Google CEO가 무대에 나타났다. 그리고 모든 Google Cloud 제품군에 AI를 탑재해 산업과 일상을 뒤바꿀 것이라고 경쟁사들에게 선전포고 했다. Google Cloud Next 2023 키노트, 그리고 이 행사 전체를 단 하나의 주제로 요약해야 한다면 기자는 다음과 같이 요약할 것 같다.
“Build AI and Use AI with Google Cloud”
풀어서 설명하면, 이 말은 다음과 같다.
Build AI
생성형 AI (Generative AI, Gen-AI)를 직접 개발하고 싶다면 Google Cloud에서 Vertex AI를 사용해주세요.
Use AI
Google Cloud와 Google Workspace에서 구글이 개발한 생성형 AI를 사용하고 싶으면, Duet AI를 사용해주세요.
이하는 키노트에서 소개한 내용을 정리한 것이다.
Google Docs에서 블로그 작성, G메일 내용 요약, 미팅 스케줄 생성, 텍스트 자료로부터 Google Slides에 삽입할 이미지 생성 등을 모두 자동으로 수행하는 Google Workspace가 AI Copilot인 Duet AI를 정식 출시(General Availability, GA)한다.
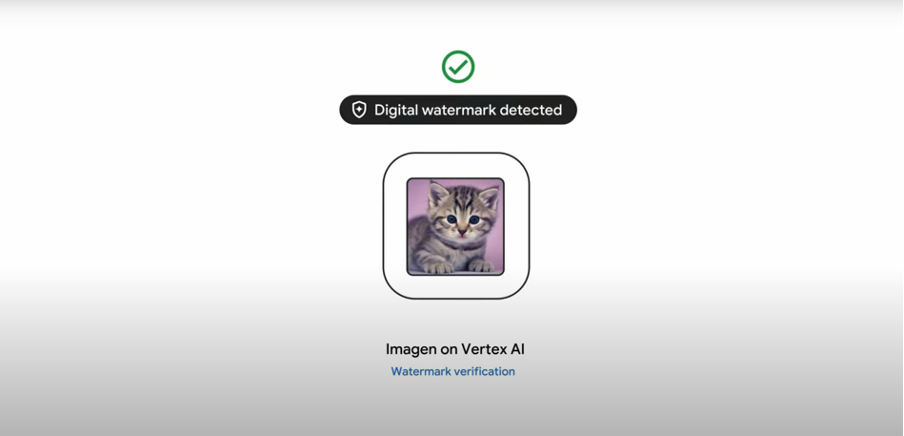
Google DeepMind SynthID를 사용해 AI로 생성한 이미지인지 아닌지 판독할 수 있는 디지털 워터마킹 기술을 개발했다. 이 워터마킹 기술은 이미지 자체에 어떤 흔적도, 이미지 품질 손상도 남기지 않고 AI가 자동으로 생성한 이미지인지 아닌지 사용자에게 알려준다.
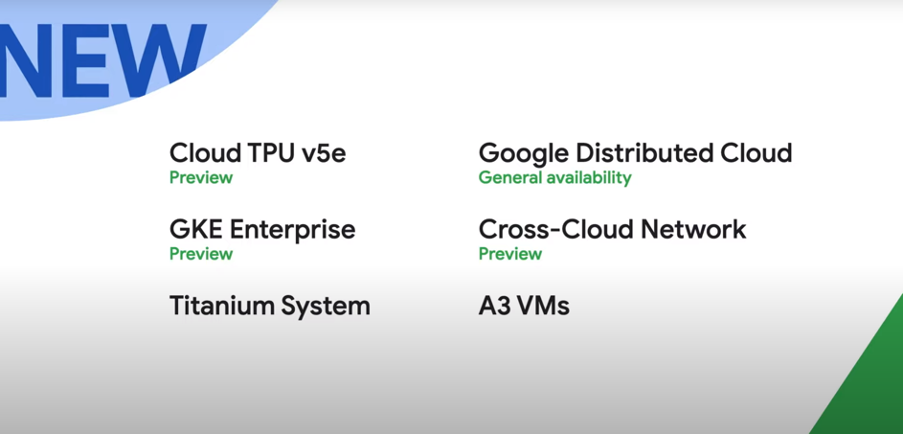
Google Cloud CEO 토마스 쿠리안(Thomas Kurian)이 Google Cloud 6가지 주요 혁신들을 소개했다.
Cloud TPU v5e는 대규모 AI 훈련과 추론을 위한 Google Cloud의 최신 맞춤형 AI 가속기다. TPU v4 대비 달러당 훈련 성능이 최대 2배 개선됐다. 달러당 추론 성능은 최대 2.5배 개선했다고 한다.
GKE 엔터프라이즈(Google Kubernetes Engine Enterprise)는 AI/ML 워크로드에 필요한 멀티 클러스터 수평 확장을 지원한다. 또한 자동 확장, 워크로드 오케스트레이션(orchestration), 자동 업그레이드 등을 지원한다고 밝혔다.
엔비디아의 최신 플래그십 AI 칩인 H100 GPU가 탑재된 가상머신 ‘A3 VMs’를 9월에 정식 출시한다고 발표했다. A3는 가장 까다로운 생성형 AI 및 대규모 언어 모델(LLM, Large Language Model)을 구현할 수 있도록 맞춤 설계했다고 한다. 이전 A2 VMs 대비 훈련 속도를 3배 더 향상했다고 전했다.
🔗티타늄 시스템은 차세대 티어 기반 오프로드 아키텍처다. AI 인프라를 뒷받침하는 역할을 한다. 예를 들어, 티타늄 시스템은 Google C3 VM 인스턴스 블록 스토리지가 다른 어떤 경쟁사 Cloud 제품보다도 25% 높은 IOPS를 제공하도록 한다.
구글 분산형 클라우드(Google Distributed Cloud; GDC)는 다른 어떤 곳이 아닌 자신들의 에지 또는 데이터 센터에서 워크로드를 실행하고자 하는 기업을 위한 제품이다. 차세대 하드웨어, 신규 보안 기능, 구글 버텍스 AI와의 통합, GDC 호스티드(Hosted)에서 알로이DB 옴니(AlloyDB Omni)의 새로운 관리형 서비스 등을 제공한다.
크로스-클라우드 네트워크(Cross-Cloud Network)는 중앙에서 클라우드 환경 전반(Google Cloud뿐 아니라 AWS, Azure, Oracle Cloud 등 다양한 클라우드들)을 관리, 보호하고, 애플리케이션 속도를 향상할 수 있는 플랫폼이다.
다양한 SaaS 애플리케이션 서비스와 연동 가능한 개방형 플랫폼으로, 제로 트러스트를 구현한 ML 기반 보안을 제공한다. 크로스 클라우드 네트워크는 고객이 어느 클라우드 환경에서든지 구글 서비스에 보다 쉽게 접근할 수 있도록 설계됐다. 네트워크 지연 시간을 최대 35% 줄인다고 전해진다.
순다 피차이 Google CEO와 마찬가지로 사전 연사 목록에 없었던 엔비디아 창립자 겸 CEO 젠슨 황이 무대에 올랐다. 그리고 엔비디아의 AI 슈퍼컴퓨팅 클라우드인 🔗DGX 클라우드를 Google Cloud Platform (GCP)에 넣을 것이라고 발표했다.
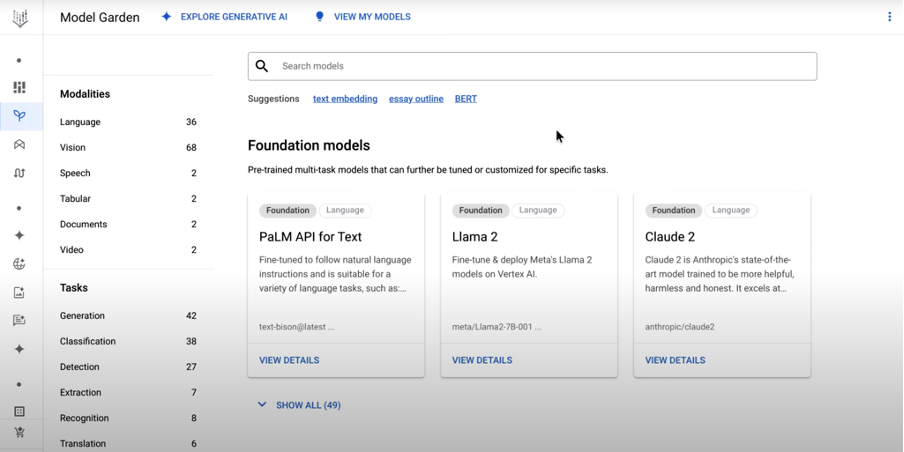
Vertex AI 🔗모델 가든에 업로드돼 있는 Google PaLM, Meta LLaMA2, Anthropic Claude 2
Google Cloud AI의 플랫폼 Vertex AI에 메타의 🔗LLaMA2, 🔗엔트로픽의 클로드 2, 🔗Tii Falcon 등 새로운 🔗기반 모델(Foundation Model)을 추가했다. 기반 모델이란 BERT, GPT-3 등과 같이 대규모 데이터로 비지도 학습을 거친 인공지능 모델이다. 기반 모델을 만드는 데는 천문학적인 비용이 들기 때문에 빅테크를 제외한 대부분 회사들은 대부분 오픈소스로 공개된 이 기반 모델을 가져다가 fine-tuning해 자사 비즈니스에 사용한다.
Vertex AI로 기업용 챗봇을 빌드하거나 자체 검색 엔진을 운영 시 JIRA, Confluence, Salesforce 데이터를 사용해 챗봇이 답변하거나 검색 콘텐츠를 업데이트할 수 있도록 했다.
키노트에서 소개한 다양한 고객 사례 중 서로 고객 관계인 Google과 Workday의 흥미로웠던 사례를 소개하겠다. Workday의 인사, 금융 애플리케이션은 Google Cloud 위에서 서빙되며, Google Cloud의 인사 애플리케이션은 Workday의 도움을 받는다. Workday는 직장 데이터, 직장 위치, 직무 스킬 등 데이터를 사용해 직무 설명(Job Description)을 자동 생성한다. 아마도, 위 직무 데이터로 Bard 또는 Vertex AI에 있는 LLM (Large Language Model) 기반 모델 중 하나를 골라 fine-tuning해 직무 설명(Job Description) 콘텐츠를 자동 생성한 것 같다.
8/29 Google Cloud Next 2023키노트 풀영상
8/29 키노트 풀영상 링크
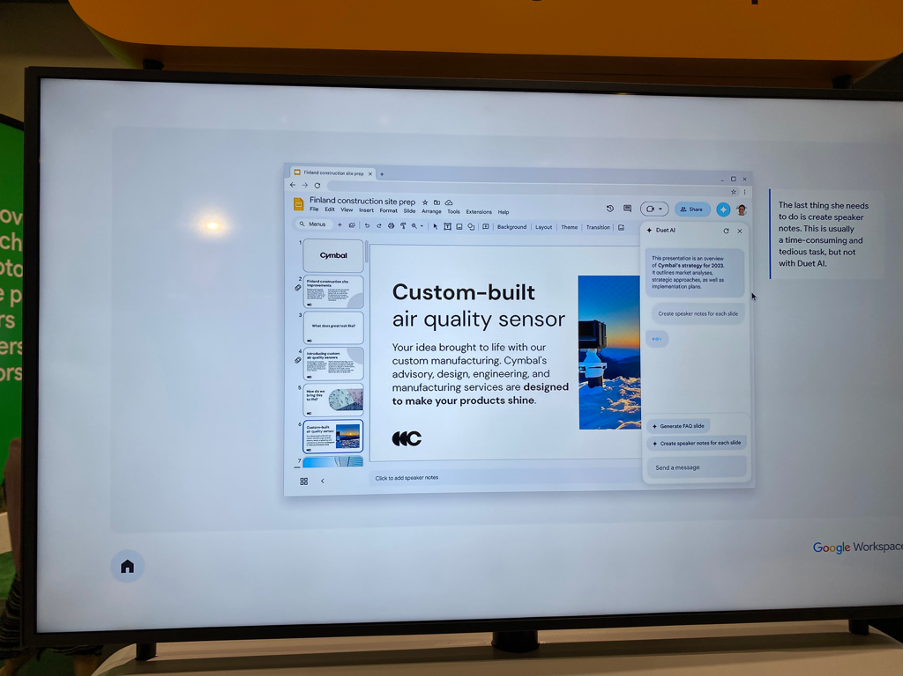
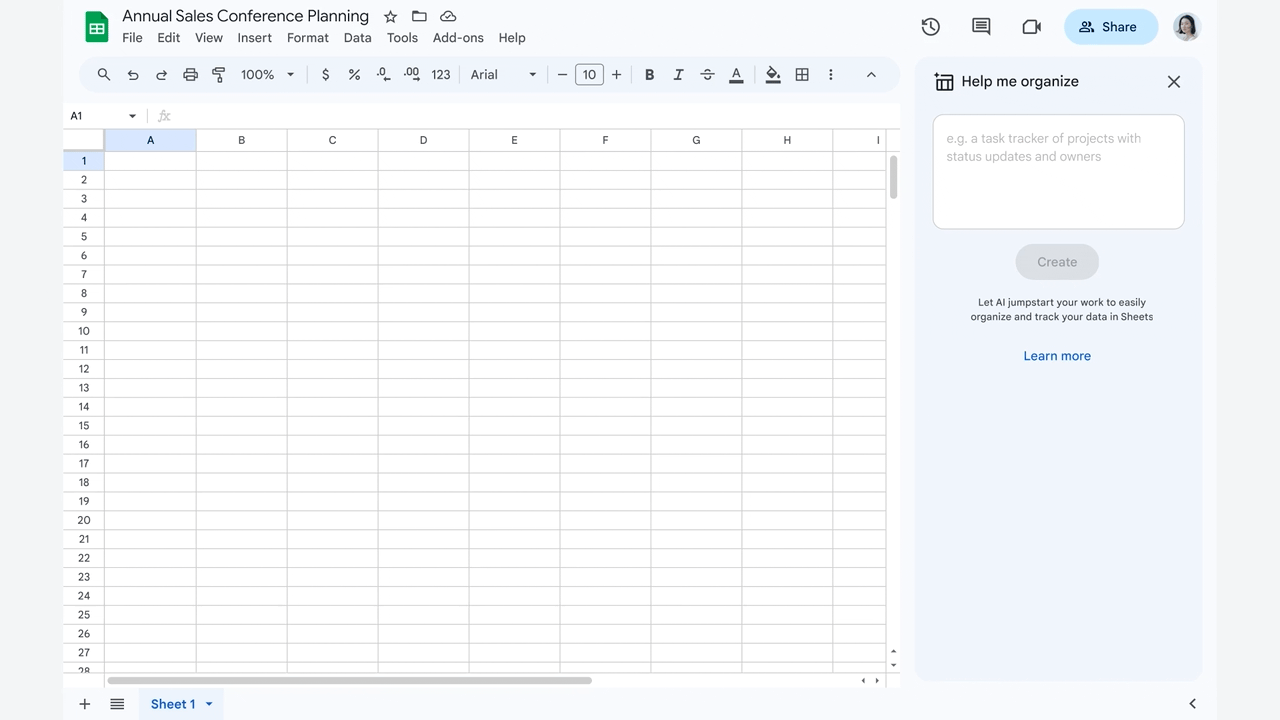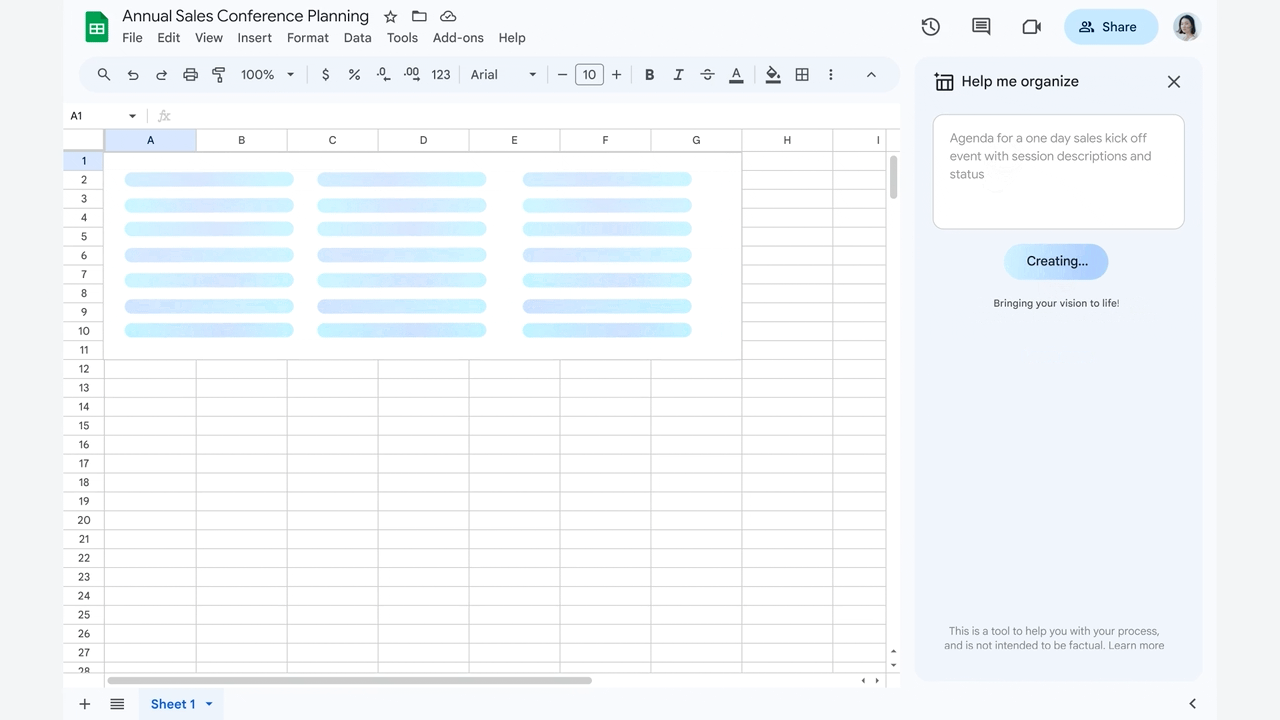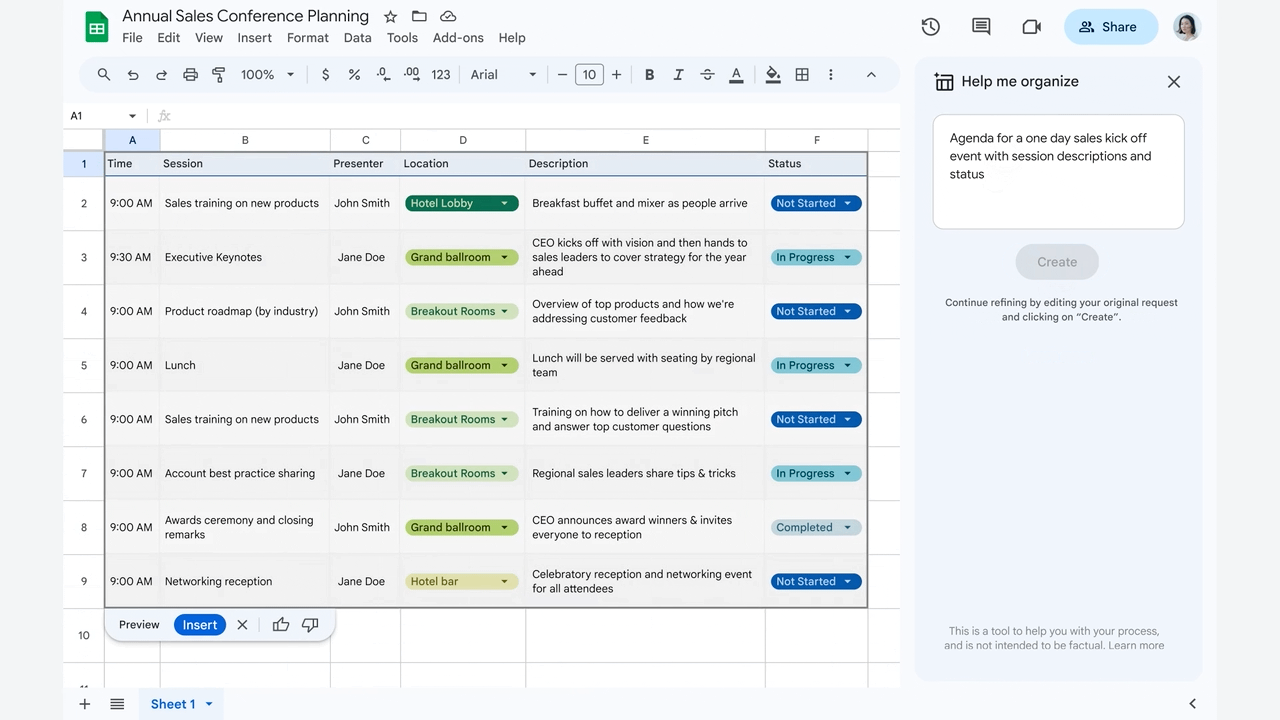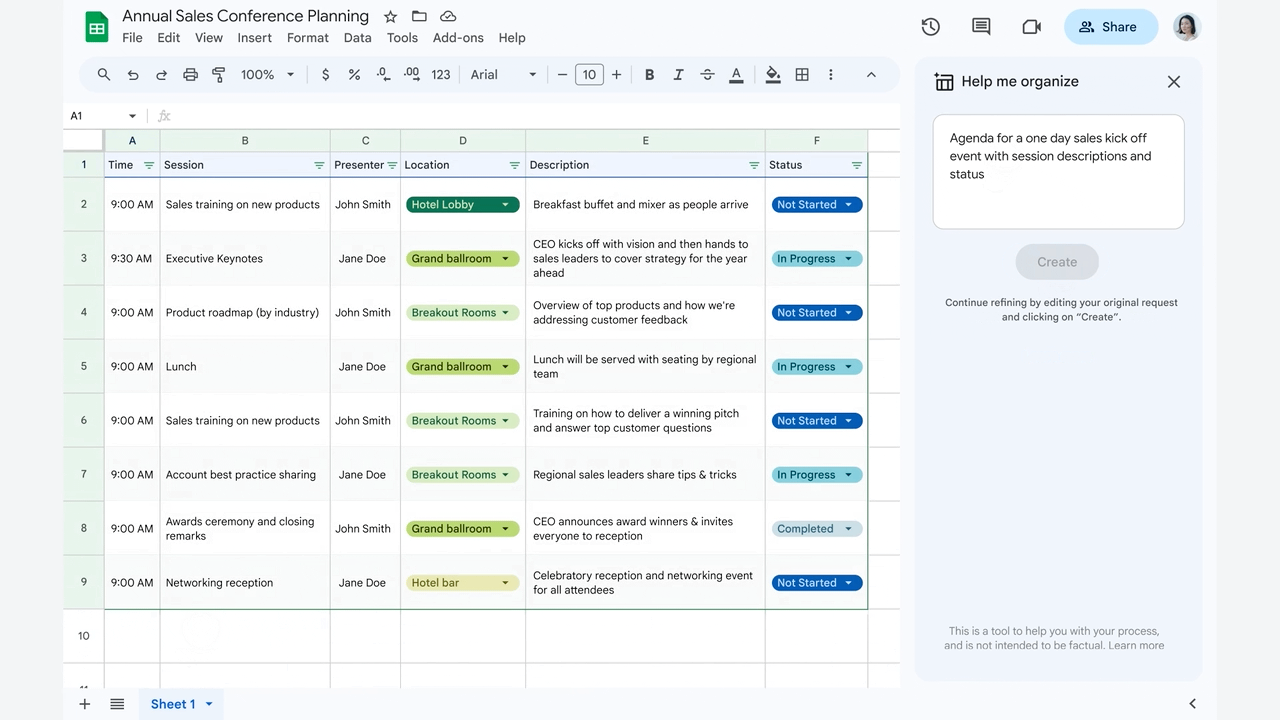
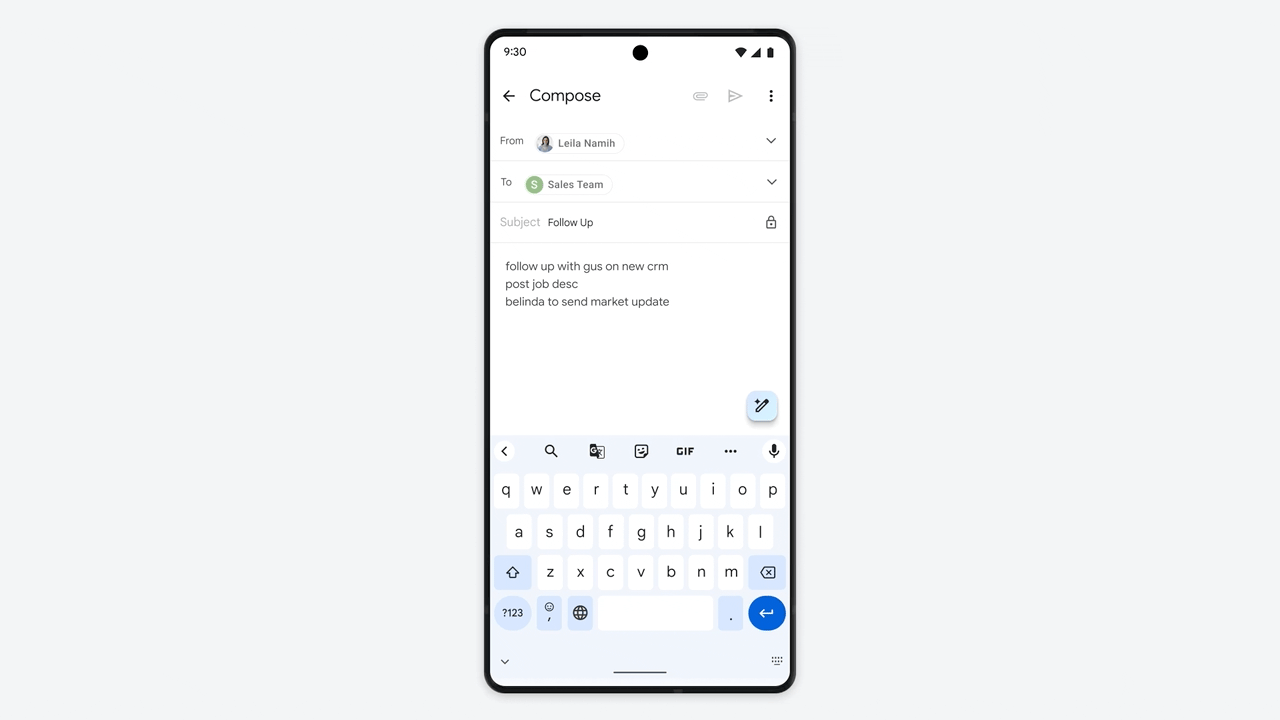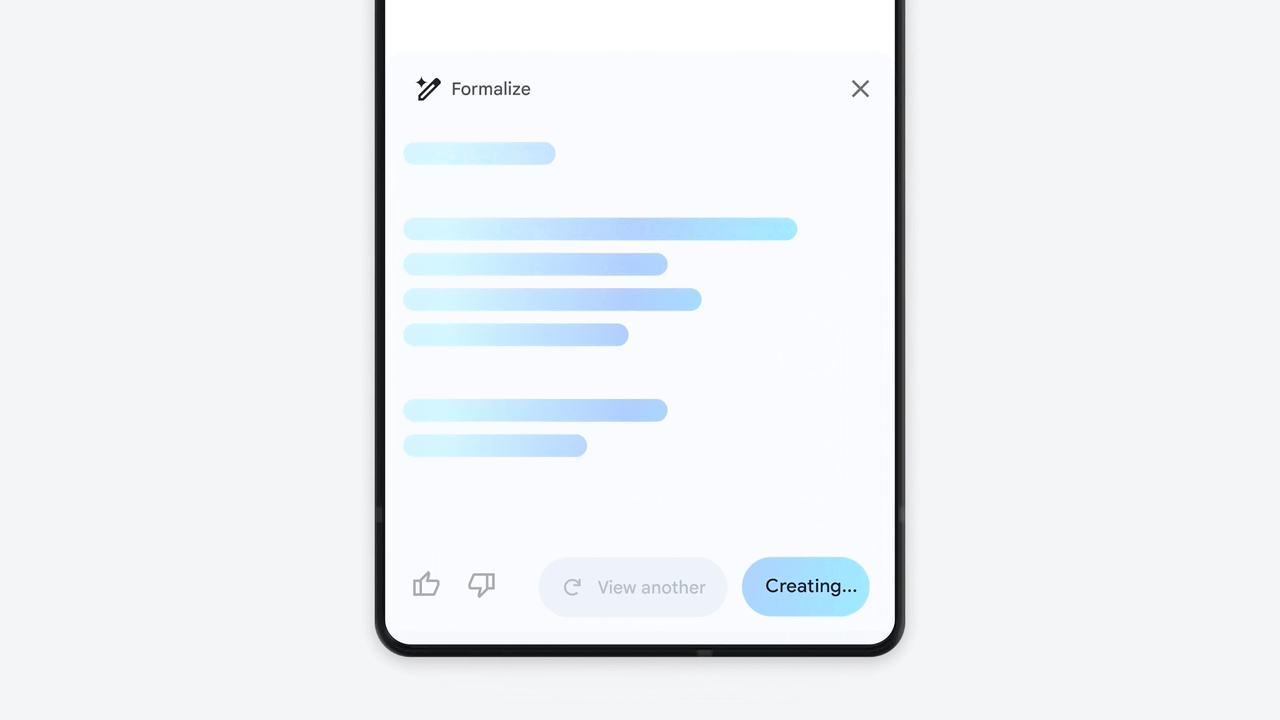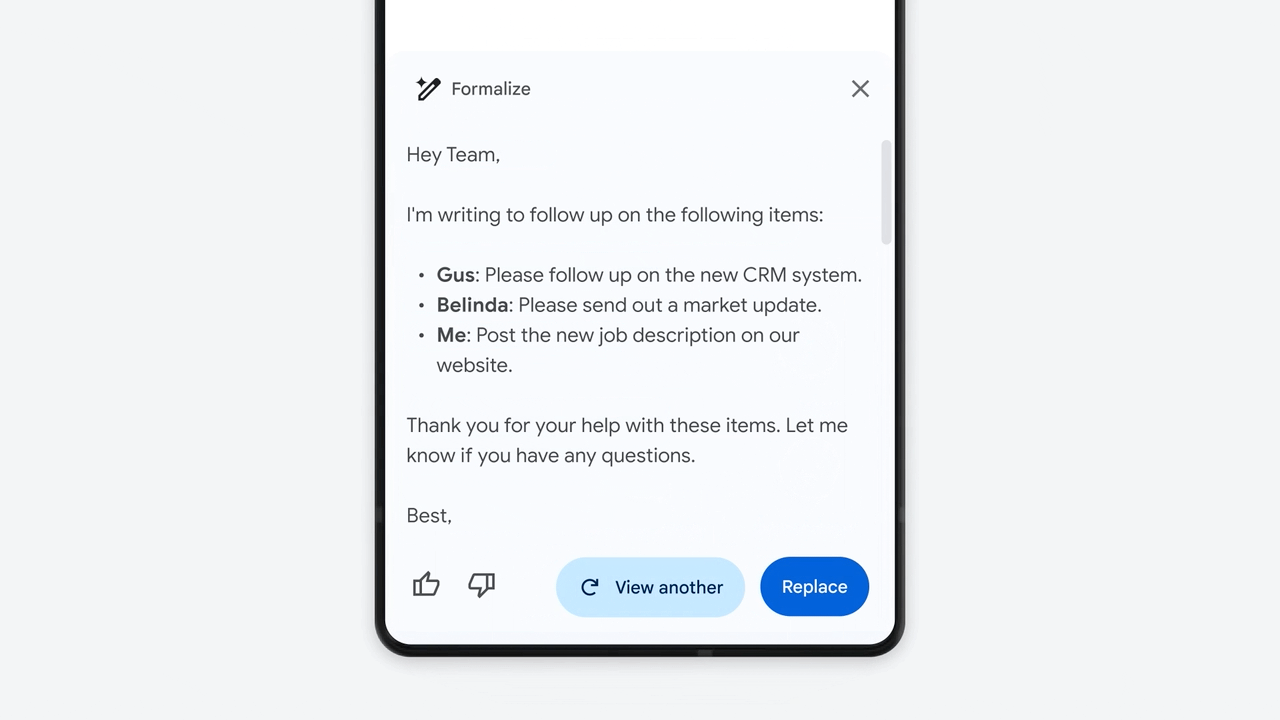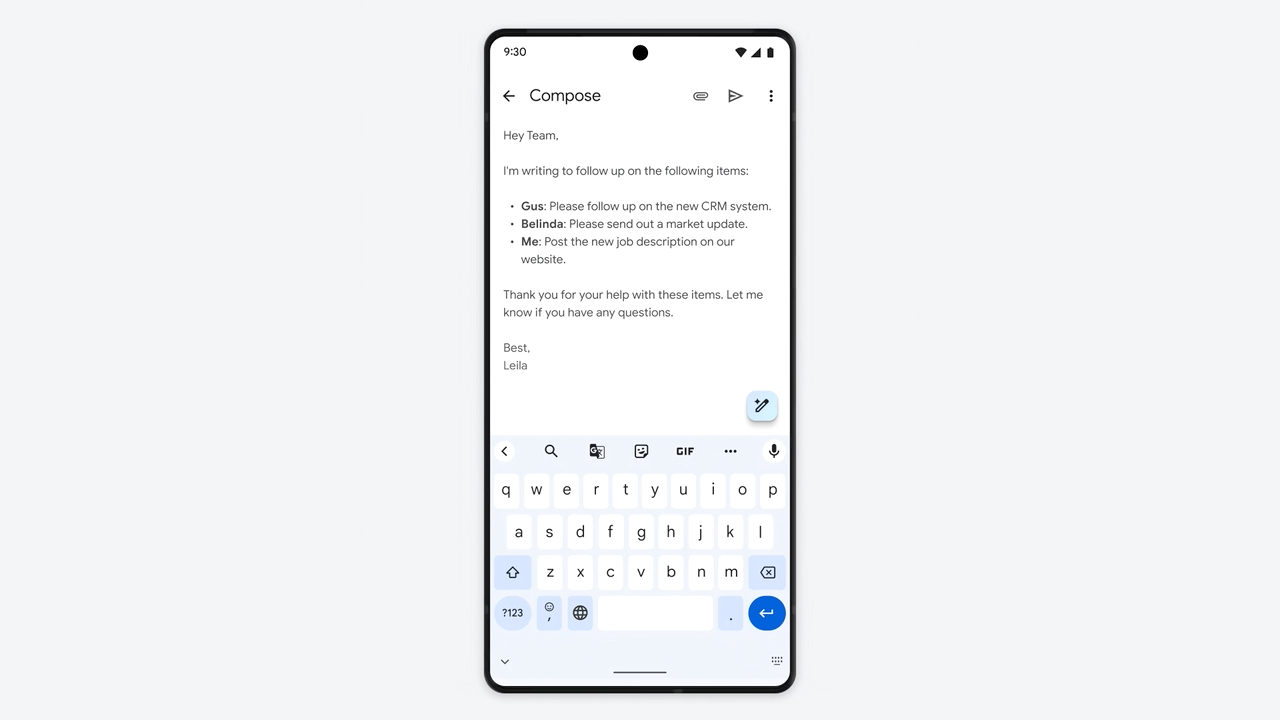
Expo Hall에는 Duet AI를 탑재한 Google Workspace 데모 시현이 이뤄졌다. 이 글을 작성하는 현재(2023년 9월), Google Cloud에서 Duet AI for Google Workspace 무료 트라이얼 (Add-ons)을 사용해 직접 써볼 수 있었다. Google Cloud에 가입하고 Google Cloud 콘솔에 로그인한 후 아래 영상을 참고하면 사용할 수 있다.
Google Slides에서 Duet AI는 슬라이드 또는 슬라이드에 들어갈 이미지를 자동으로 만들어준다. Chat GPT 프롬프트를 쓰는 것처럼, 채팅으로 어떠어떠한 이미지를 생성해달라고 입력하면 슬라이드에 삽입할 이미지(저작권에 문제 없는 이미지)를 생성해 준다. 또 어떠한 자료 또는 데이터를 기반으로 프리젠테이션을 생성해달라고 채팅으로 명령하면, 자동으로 Google Slides 템플릿을 만들고 슬라이드들을 생성해 준다.
Google Docs에서 Duet AI는 프롬프트 입력으로 원하는 양식의 글(보고서, 블로그 등)을 작성해 준다. 역시 원하는 데이터(구글 시트, 또는 다른 구글 Docs 문서)를 지정해서 이 데이터를 기반으로 글을 작성해달라고 명령하면, 신기하게도 이 자료 내용에 따라 원하는 양식의 글을 작성해 준다.
짐작하겠지만 이 ‘매직’을 무턱대고 믿는 것은 곤란하다. 모델 할루시네이션(Model Hallucination)이 일어나지 않으리라는 보장이 없기 때문이다. 할루시네이션이란 AI 모델이 결과적으로 틀린 내용을 마치 옳은 답처럼 잘 포장해서 결과를 뱉어내는 현상을 말한다. 이는 생성형 AI 모델이 학습하지 않은 내용을 추론하도록 요구받았거나, 학습 과정이 잘못됐기 때문에 발생한다. 따라서 Duet AI를 사용하는 입장에서는 Duet AI가 생성해 준 모든 내용을 반드시 검수하는 것이 필요하다.
RNN과 LSTM에 멈춰있던 NLP쪽 지식을 이번 기회에 업데이트하고자 Transformer와 LLM을 소개하는 랩 세션에 참석했다. 전날 밤, 호텔에서 🔗Attention is All You Need 논문을 정독하고 가려고 했으나 시차로 인해 쏟아지는 잠을 도저히 이길 수가 없었다. 결국 이론 세션을 이해하는 둥 마는 둥 하며 Google Qwiklabs으로 넘어갔다.
LLM 기초를 배우려는 현장 분위기는 대단했고, 2시간은 말도 안 되게 짧은 시간이었다.
이론 파트는 NLP 히스토리(RNN부터 Transformer까지 발전 과정), Transformer 아키텍처 핵심(Multi-headed Self Attention: 영문, 국문) 등을 엄청나게 빠르게 설명하고 넘어갔다. 배경지식이 없는 사람이 즉석에서 이해할 수 있는 수준은 아니었고, Transformer 논문을 이해하고 있는 사람이 요약용으로 들을만한 내용 같았다.
이론 파트를 간단히 요약하자면, Transformer 아키텍처는 기본적으로 Encoder와 Decoder로 구성된 모델이며, ChatGPT에서 ‘GPT’는 그림의 우측에 있는 Decoder 모델만을 사용한다.
인공지능은 먼저 학습을 시켜야 써먹을 수 있으므로, 인공지능을 학습시킬 데이터가 필요하다. GPT는 사람이 쓰는 일상 언어 텍스트를 학습시켜야 한다. 이를 위해 우리말을 기계가 알아들 수 있는 형태로 바꿔하는데, 이를 Input Embedding이라고 부른다. Embedding한 데이터를 가공(Positional Encoding)한 다음, 학습을 시작하면 된다(위 그림에서 Nx로 표현한 신경망에 학습 자료를 전달).
이론 파트 요약<2>: 학습
Transformer 인공지능은 학습 자료를 전달받아 학습을 시작한다. Transformer는 어떤 문장을 학습할 때, 문맥에 따라 어떤 단어를 더 집중적으로 학습해야 하는지 깨닫는 방식(Multi-Head Attention)으로 인간 문장의 문맥을 이해한다.
이론 파트 요약<3>: 추론
학습한 문맥의 내용을 바탕으로, Transformer는 불완전한 문장이 주어졌을 때 문장을 자연스럽게 완성할 수 있는 최적의 단어를 확률에 기반해 추천(Softmax)한다.
실습 파트
실습 파트는 주피터 노트북에서 🔗KerasNLP로 🔗구텐베르그 책 1,573권을 담은 데이터셋을 가지고 Transformer를 만드는 방법을 알려줬다. 데이터를 전처리(Tokenize)하고, 모델을 학습(Training)한 후, 추론(Inference)하는 코드를 직접 짜보는 기회가 주어졌다. 그렇지만 시간이 촉박해 기자는 실제로 구현을 하진 못했고 주어진 예제 코드를 보고 진행했다.
Transformer는 Decoder 모델이므로 추론을 하려면 다음 단어로 어떤 단어(token)가 가장 적절한지 결정해야 했다. 단순히 가장 높은 softmax probability 값을 가진 token을 선택(=Greedy search) 하는 것 외에도 다양한 방법들이 있으며, 실전에서는 어떤 방법을 어떤 과정을 거쳐 선택하느냐가 쉽지 않은 문제라고 강조했다. 기자도 예전에 잠시 연구원 생활을 할 때 추론 부분에 관해 같은 고민을 했던 경험이 있어 공감이 됐다.
실습 파트에서 몇 가지 아쉬운 점들도 있었다. 주피터 랩을 위한 Google Cloud 환경 설정이 미리 돼 있는 게 아니라, 세션 참여자가 이를 직접 진행해야 했다. 해서 사용할 CPU, GPU를 선택하고 인스턴스 올리는 데 시간을 다소 소요됐다. 또 독립된 Room에서 세션을 진행한 것이 아니어서 다른 부스에서 들려오는 온갖 소음에 노출됐다. 뒷자리에서는 마이크 소리가 제대로 들리지도 않았다. 이론을 설명하는 속도가 가뜩이나 빠른데 뒷자리에서는 외부 소음으로 강연자 목소리가 정확히 들리지 않았던 점은 상당히 안타까웠다.
어쨌든, 실습 파트를 완료했다면 구텐베르그 책 1,573권을 학습한 Transformer, 즉 Generative Pre-trained Transformer 모델 하나를 생성한 것이다. Generative Pre-trained Transformer를 줄여서 GPT라고 부르고, 이는 ChatGPT의 바로 그 ‘GPT’다. 물론, 이 모델은 그저 구텐베르그 책들에 있는 내용을 기반으로 어떤 문장이 주어졌을 때 다음 단어를 예측하는 기계에 불과하다. 만약 이 GPT 모델이 게임 운영을 위한 Q&A 봇이 되길 원한다면 게임 운영과 관련된 질문과 답변 텍스트 데이터로 이 GPT 모델을 좀 더 학습시켜야 한다. 이 추가 학습 작업을 가리켜 ‘Fine-tuning’이라고 부른다.
Open AI가 만든 GPT는 GPT-1,2,3를 거치며 파라미터 개수 측면에서 점점 거대해졌고 복잡한 문맥 혹은 긴 문장을 더 잘 이해할 수 있게 됐다. 다만, 기본적으로 웹에 있는 텍스트 데이터로 만들었기 때문에 🔗비윤리적인 답변을 하거나 어색하고 부정확한 답변을 내놓을 수 있다. 따라서, GPT가 생성하는 텍스트 품질을 좀 더 사람이 볼 만한 수준으로 향상시키기 위해 Open AI는 RLHF(Reinforcement Learning from Human Feedback)를 포함해 🔗여러 Fine-tuning 테크닉을 적용했고 그 결과물이 GPT-3.5(구 InstructGPT)다. 그리고 이 GPT-3.5 모델이 사람이 대화하는 형식(Chat)으로 텍스트를 생성할 수 있도록 대화 형식 데이터로 다시 fine-tuning한 것이 바로 우리가 현재 무료 버전으로 쓸 수 있는 ChatGPT다.
김현영 기자
샌프란시스코는 여러 이슈에도 불구하고 여전히 활력이 넘치는 도시였고, 세계 각국 다양한 기업에서 온 사람들이 눈을 반짝이며 세션을 듣는 모습을 보니 자연스럽게 동기부여를 받을 수 있어 좋았습니다. 생성형 AI를 클라우드 전면에 도입하는 구글의 시도가 과연 어떤 결과로 이어질지 귀추를 지켜보고 싶습니다.