우리는 게임을 하며 많은 욕설을 마주하게 됩니다. 얼굴이 공개되지 않는 공간에서 게임을 이용하는 유저들 간에 서로를 향한 욕설은 서로에게 큰 상처가 될 수 있습니다. 그래서 많은 게임사들은 채팅을 필터링하여 욕설을 ***(별)로 마스킹 처리를 하거나, 다른 단어로 치환을 하는 등 많은 노력을 기울입니다.
하지만 뛰어난 창의력을 지닌 유저들로부터 작성된 욕설은 필터링이 되지 않고 그대로 노출이 되는 경우가 많습니다. 따라서 이를 모니터링하여 주의를 주거나 제재를 하는 등의 조치가 필요합니다. 모니터링 및 관리를 맡은 서비스 담당자는 수동으로 게임 내 채팅 내용을 읽고 식별하는 프로세스로 업무에 많은 부하가 생기게 되었습니다.
우리는 이런 기존의 수동으로 읽고 식별하는 프로세스를 개선하여, 업무 담당자가 효율적이고 효과적인 업무를 할 수 있도록 채팅 어뷰징 탐지 시스템을 구축하였습니다. 채팅 어뷰징 탐지 시스템 도입 전에는 모니터링 담당자가 한 개의 게임에서 일일 채팅 기준 전체 채널을 확인하는 것이 사실상 불가능하여 비매너 유저가 많다고 판단되던 특정 몇 개의 채널을 약 3시간 정도에 걸쳐서 모니터링하였습니다.
그러나 채팅 어뷰징 탐지 시스템 도입 후, 필터링 등이 추가되어 전체 채널을 약 한 시간 내외로 모니터링하는 것이 가능해졌습니다. 업무 담당자들은 시간 절약 및 모니터링 범위 확장으로 인해 업무 효율성이 극대화될 수 있었다고 피드백을 주었고 인공지능의 큰 장점을 경험할 수 있었습니다.
이 글에서는 전체적인 어뷰징 탐지 시스템을 데이터 사이언스와 엔지니어링 파트로 나누어서 소개합니다. 먼저 데이터 사이언스 파트부터 시작하겠습니다.
데이터 사이언스
기존 채팅 어뷰징 탐지는 금칙어 기반 시스템으로 텍스트 내부에 사전에 정의된 금칙어가 존재하는지를 검사하는 방식이었습니다. 그러나 이런 시스템을 잘 아는 유저들은 금칙어를 우회하여 필터링이 되지 않도록 사용하고 있습니다. 예를 들어 XX를 욕설이라고 할 때 “XX 짜증나”라는 텍스트에는 금칙어가 존재하기 때문에 쉽게 검출할 수 있지만 “ㅅ111발 짜증나”라는 텍스트는 검출하기 어렵습니다. 이를 해결하기 위한 방법으로 금칙어 사전에 “ㅅ111발”을 추가하여 “ㅅ111발 짜증나”라는 텍스트를 검출할 수는 있습니다. 그러나 우회되고 변형된 욕설을 계속 저장소에 추가하며 관리하기에는 어려움이 있습니다.
따라서 우리는 딥러닝을 이용한 자연어 처리를 통해 비매너 채팅을 탐지하는 시스템을 구축하기로 계획했습니다. 딥러닝을 이용하면 금칙어 기반의 시스템의 문제를 해결할 수 있고, 추가적으로 문맥까지 파악하여 금칙어가 존재하지 않는 텍스트도 검출할 수 있을 것이라 생각했습니다. 우리는 딥러닝 방식과 기존 채팅 어뷰징 탐지 방식을 통합하여 하이브리드 방식으로 제공한다면 사용자에게 더 나은 결과를 제공할 수 있을 것이라 판단하여 하이브리드 방식의 시스템을 개발하기로 했습니다.
탐색적 데이터 분석(EDA, Exploratory Data Analysis)
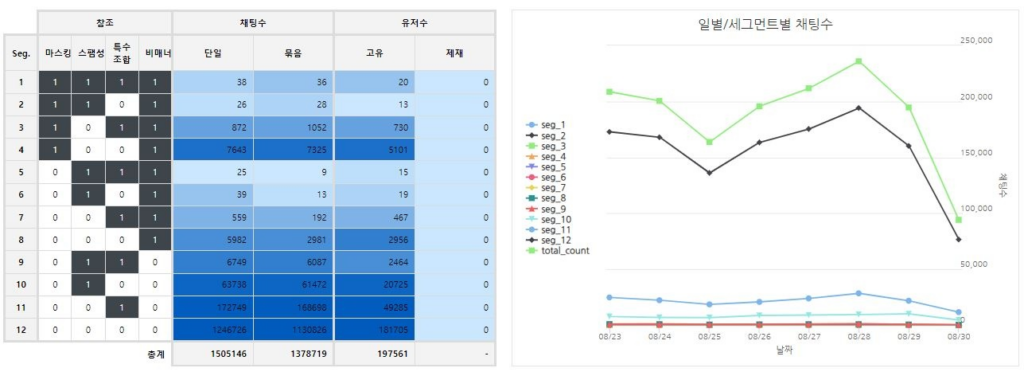
탐지 모듈을 개발하기 전에 게임 내 유저들의 채팅 데이터로 EDA를 진행하였습니다. EDA를 통해 유저들의 채팅 사용 패턴, 채팅의 특징 등 다양한 인사이트를 얻을 수 있었습니다. 얻은 인사이트를 통해 우리는 채팅 특징별로 세그먼트를 나누어 세분화할 수 있었습니다. 또한 전처리 단계에 묶음 채팅 모듈을 적용하였고, 이를 통해 더 많은 비매너 채팅을 검출할 수 있었습니다. EDA 과정 및 결과는 실험 파트에서 자세하게 설명될 예정입니다.
비매너 채팅 정의
비매너 채팅은 다양한 형태로 나타날 수 있습니다. 심한 욕설이 포함된 채팅뿐만 아니라 타인에게 시비를 거는 채팅도 비매너 채팅에 해당됩니다. 한 사례로 프로야구 특정 구단을 모욕하며 타 유저에게 피해를 주는 채팅도 비매너 채팅에 속할 수 있습니다. 우리는 욕설이 포함되었거나 성적 발언, 비하 등 타 유저에게 피해가 될 수 있는 채팅을 비매너 채팅으로 정의하였습니다.
데이터
우리는 더 나은 채팅 어뷰징 탐지 시스템을 개발하기 위해 채팅 원천 데이터를 수집하여 채팅의 특성을 파악하고 인사이트를 얻는 과정이 필요했습니다. 또한, 인공지능 모델을 학습하고 평가하기 위한 데이터 수집이 필요했습니다. 채팅 데이터 특징상 개인정보가 존재할 수 있으므로 수집한 데이터에서 개인정보가 포함되는 데이터는 제외하고 사용하였습니다. 원천 데이터로 채팅 어뷰징 탐지 시스템을 개발하기 전 데이터 분석을 위해 약 1,510만 건의 채팅 데이터를 대상으로 하였습니다.
머신러닝을 이용한 탐지 시스템에서는 채팅 데이터가 이진 분류(즉, 비매너 채팅이 맞다 혹은 아니다) 될 것이므로 비매너 채팅 데이터와 비매너 채팅이 아닌 데이터가 필요합니다. 따라서 우리는 원천 데이터로부터 비매너 채팅 데이터와 일반 채팅 데이터를 구분하였습니다. 학습 데이터는 약 10만 건으로 원천 데이터를 직접 라벨링하여 생성하였습니다. 원천 데이터에 비매너 채팅보다 일반 채팅의 비율이 훨씬 높았지만, 클래스 불균형(class imbalance) 문제를 해결하기 위해 비매너 채팅과 일반 채팅의 비율이 1:1이 되도록 맞춰주었습니다. 학습 데이터의 20%에 해당하는 비율을 랜덤하게 추출하여 모델 평가에 사용하였습니다.
모델
채팅 비매너 탐지를 위해 기존에 많이 사용하던 방식은 로직형 모델입니다. 채팅에 욕설 및 금칙어가 포함이 되어있는지 판단하는 로직형 모델은 단순히 텍스트 내부에 금칙어의 존재 유무를 파악합니다. 우리는 채팅 비매너 탐지를 위해 기존에 많이 사용하던 로직형 모델을 고도화하고 딥러닝 모델을 적용하여 하이브리드 모델을 구축하였습니다. 각 모델에 대한 설명은 아래와 같습니다.
로직형 모델(이하 “L-타입 모델”이라 합니다)
L-타입 모델은 채팅 데이터에 금칙어 데이터가 존재하는지 유무를 판단합니다. L-타입 모델의 성능을 높이기 위해서 총 4가지의 전처리 모듈을 추가하였습니다. 먼저, EDA를 통해서 얻은 인사이트로 한 유저가 일정시간 내에 입력한 각 채팅을 통합하는 묶음 처리 모듈을 추가하였습니다. 둘째, 자음과 모음을 분리하여 금칙어를 사용하는 경우가 많기 때문에 자모결합 모듈을 추가하였습니다. 셋째, 모바일 게임 채팅 특성상 띄어쓰기가 올바르게 되어있지 않으므로 띄어쓰기를 교정해주는 모듈을 추가하였습니다. 마지막으로 형태소 분석기를 통해 단어 단위로 토큰화하는 모듈을 추가하였습니다. 각 모듈들을 조합하며 더 나은 성능을 지닌 L-타입 모델을 구성할 수 있었습니다.
딥러닝 모델(이하 “M-타입 모델”이라 합니다)
텍스트 분류를 위한 딥러닝 모델 학습에 우리는 전이학습을 사용했습니다. 전이학습이란 특정한 작업(task: Classification, Detection, Segmentation 등)에 대해 사전 학습된 딥러닝 모델을 다른 작업으로 전이(transfer) 하여 해당 모델을 사후적으로 학습하는 개념입니다. 우리는 기존 BERT의 한국어 성능 한계를 극복하기 위해 개발된 KoBERT와 뉴스 댓글과 신조어가 반영된 한국어 언어 모델인 KcBERT를 이용하여 조세조정(fine-tuning) 하였습니다. 사전 학습된 모델(pretrained model) 두 가지에 대한 설명은 아래와 같습니다.
KoBERT는 기존 BERT의 한국어 성능 한계를 극복하기 위해 개발되었습니다. 위키피디아나 뉴스 등에서 수집한 수백만 개의 한국어 문장으로 이루어진 대규모 말뭉치(corpus)를 학습하였으며, 한국어의 불규칙한 언어 변화의 특성을 반영하기 위해 데이터 기반 토큰화(tokenization) 기법을 적용하여 높은 성능을 보입니다. 대량의 데이터를 빠른 시간에 학습하기 위해 링 리듀스(ring-reduce) 기반 분산 학습 기술을 사용하여, 10억 개 이상의 문장을 다수의 머신에서 빠르게 학습합니다.
KcBERT는 대부분 한국어 위키, 뉴스 기사, 책 등 잘 정제된 데이터를 기반으로 학습한 모델입니다. 한편, 댓글형 데이터셋은 정제되지 않았고 구어체 특징에 신조어가 많으며, 오탈자 등 공식적인 글쓰기에서 나타나지 않는 표현들이 빈번하게 등장합니다. KcBERT는 위와 같은 특성의 데이터셋에 적용하기 위해, 네이버 뉴스에서 댓글과 대댓글을 수집해, 토크나이저와 BERT모델을 처음부터 학습한 Pretrained BERT 모델입니다. 최근 KcELECTRA가 릴리즈 되었습니다. KcELECTRA는 더 많은 데이터셋, 그리고 더 큰 일반 어휘(general vocab)을 통해 KcBERT 대비 모든 작업에서 더 높은 성능을 보입니다.
우리는 두가지 모델에 대해 모두 미세조정(fine-tuning) 학습을 진행 후, 더 성능이 좋은 모델을 선택하였습니다.
실험 전 단계
우리는 실험 전, 원천 데이터를 기반으로 하여 시스템에 적용 가능한 유효 패턴을 식별하고 이를 적용하기 위한 각종 기법 발굴을 목적으로 EDA를 진행하였습니다. EDA는 원 데이터를 가지고 유연하게 데이터를 탐색하고, 데이터의 특징과 구조로부터 정보를 얻는 중요한 단계입니다. 우리는 EDA를 통해 원천 데이터 전반에 수집, 보존, 레이블링 등 다양한 이슈가 존재함을 확인하였으며, 이에 따라 필요 모듈을 생성하고 시스템 구축 방향을 제시할 수 있었습니다.
원천 데이터 전반에 총 3가지 이슈가 존재하였습니다. 데이터의 수집 및 보존 기한이 한정되어 있어 1년 풀 사이클 시즌 이펙트 검출이 불가하였습니다. 또한, 적은 제재 건수로 인한 레이블링 데이터가 부족하였습니다. 마지막으로 채팅 데이터의 전송 단계에서 금지어에 대해서는 이미 마스킹 된 상태로 처리되어 원천 데이터의 정보 가치가 훼손된 상태였습니다.
채팅 시 흔히 발생할 수 있는 여러 특이 패턴이 존재하였습니다.
파편화된 채팅: 특정 단어 혹은 문장을 분해하여 개별 채팅 라인으로 분리 송출하는 형태
변형된 단어: 주로 탐지(beholding) 패턴에서 발생하며, 금칙어 사이에 숫자, 기호 등을 섞어 시스템 필터링을 피해가는 경우
특수 조합: 자/모의 조합 및 기타 기호와 결합된 채팅 내역
스팸성: 동일한 단어, 구 및 문장 형태를 동일 사용자가 단일 채널 혹은 복수 채널에서 2회 이상 송출하는 경우로 광고 혹은 도배 등 채팅 건전성에 악영향을 주는 경우 다수
불규칙한 띄어쓰기: 비정상적인 어휘 사용과 문법 오용이 합쳐져 AI를 통한 검출이 어려운 경우
유저들은 마스킹 되는 것을 피하려 우회적인 방법으로 비매너 채팅을 하고 있습니다. 예를 들어 비매너에 해당하는 단어 혹은 문장을 의도적으로 분리시켜 개별 채팅으로 송출하면서 마스킹 되는 것을 피하고 있습니다. 우리는 이를 탐지하기 위해 묶음 처리 모듈을 생성하였습니다. 묶음 처리 모듈이란 동일 채널, 동일 유저의 채팅 간 시간 차이를 이용하여 정해진 시간 범위 안에 들어오면 채팅을 묶어주는 모듈이며, 해당 모듈을 사용하여 파편화된 비매너 채팅을 탐지할 수 있었습니다.
우리는 데이터 특성과 이슈들을 종합하여 세그먼트 분류를 제시하였습니다. 비매너 패턴 유무를 포괄하여 마스킹, 스팸, 특수 조합의 총 4가지 특이 패턴을 정의하였고 총 12가지의 세그먼트를 도출하여 채팅을 세분화하였습니다.
그림 1. 세그먼트 분류
L-타입 모델 실험
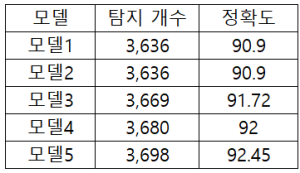
욕설을 사용하는 유저들은 금칙어 필터링이 되지 않도록 우회하거나 변형한 형태로 사용합니다. 변형된 욕설을 탐지하기 위해 우리는 단순히 텍스트에 금칙어가 존재하는지를 판단하는 것이 아닌 몇 가지 모듈을 통합한 금칙어 필터링 모델을 구성하였습니다. 텍스트 데이터 특성상 전처리를 어떻게 하느냐에 따라 성능이 달라질 수 있기 때문에 여러 방식의 전처리 과정을 실험했습니다. 총 5가지 금칙어 필터링 모델을 구성하였고 그 중 가장 성능이 높은 모델을 선택하였습니다. 5가지 모델에 대한 설명은 아래와 같습니다.
• 모델 1: 묶음 처리 → 공백/특문/자모 제거 → 띄어쓰기 처리 → 토큰화 → 탐지 • 모델 2: 묶음 처리 → 공백/특문 제거 → 자모 결합 → 자모 제거 → 띄어쓰기 처리 → 토큰화 → 탐지 • 모델 3: 묶음 처리 → 공백/특문 제거 → 자모 결합 → 띄어쓰기 처리 → 토큰화 → 탐지 • 모델 4: 묶음 처리 → 공백/특문 제거 → 자모 결합 → 띄어쓰기 처리 → 토큰화 → 자음형 비속어 탐지 → 자모 제거 → 탐지 • 모델 5: 묶음 처리 → 공백/특문 제거 → 자모 결합 → 띄어쓰기 처리 → 토큰화 → 자음형 비속어 탐지 → 공백/특문/자모 제거 → 띄어쓰기 처리 → 탐지
테스트 데이터 약 4,000건에 대해 비교한 결과는 다음과 같습니다.
그림 2. 각 모델별 탐지 개수 및 정확도
M-타입 모델 실험
L-타입 모델이 잘 탐지하지 못한 비매너 채팅으로는 우회된 욕이나 공격적인 표현으로 해당 이슈는 인공지능 모델로 해결할 수 있을 것이라 판단하였고 M-타입 모델을 적용하기 위한 실험을 진행했습니다. M-타입 모델은 각 채팅 데이터가 비매너 채팅이 맞는지 아닌지 이진 분류하는 모델입니다. 학습 데이터는 직접 레이블링을 수행하였습니다.
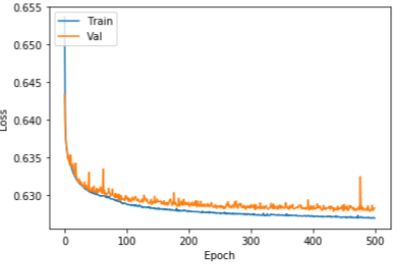
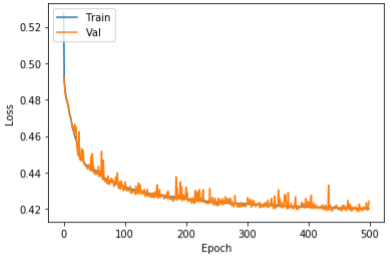
이미 잘 훈련된 모델을 사용하여 전이 학습(transfer learning)을 진행하였습니다. 우리는 잘 알려진 사전 훈련 모델인 KoBERT와 KcBERT 모델을 미세조정(fine-tuning)을 수행하면서 학습을 진행하였습니다. 두 사전 훈련된 모델은 훈련에 사용된 데이터와 단어 사전 등이 상이하여 두 가지 모델을 학습 후에 비교하였습니다. KoBERT 모델과 KcBERT 모델 모두 그림 3, 4와 같이 초반에 손실(loss)이 급격히 줄어들다가 수렴하는 것을 확인할 수 있었습니다.
그림 3. KoBERT 학습 결과그림 4. KcBERT 학습 결과
우리는 두 가지 학습된 모델을 비교한 결과, KcBERT가 더 적합하다고 판단이 되어 KcBERT 모델을 M-타입 모델로 선정하였습니다. 비교 내용은 아래와 같습니다. 두 모델은 학습에 사용된 단어의 양과 특성이 다르고 토크나이저도 다르기 때문에 어떤 사전 학습 모델에 미세조정(fine-tuning)을 하는지에 따라 성능이 달라질 수 있습니다.
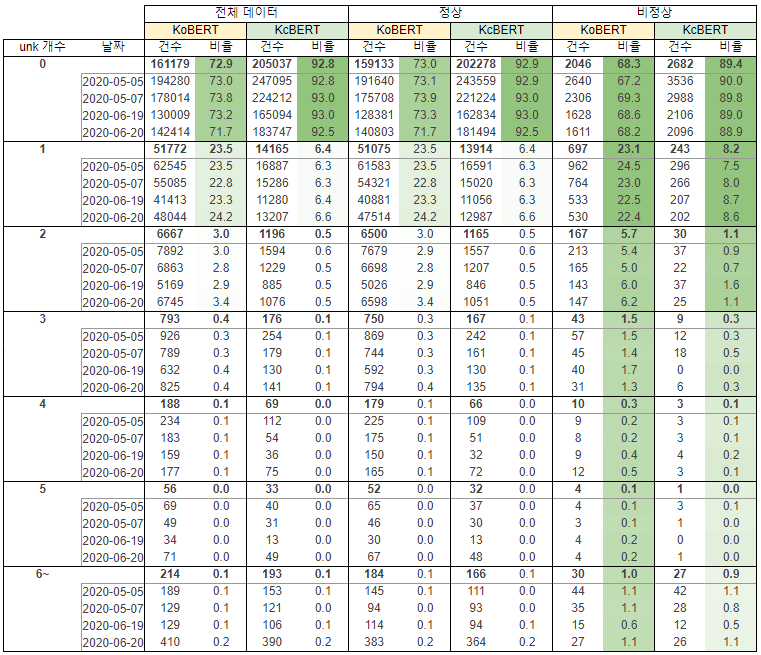
첫째, 특정 단어가 사전에 존재하지 않는 단어일 경우 ‘unknown token’으로 구분되어 학습의 성능이 떨어질 수 있습니다. 따라서 우리는 KoBERT 모델과 KcBERT 모델의 각 ‘unknown token’ 비율을 살펴보았습니다.
그림 5. 모델별 unknown 토큰 비율
그림 5와 같이 KoBERT 대비 KcBERT 모델의 ‘unknown token’ 존재 비율이 20% 낮으며 정상, 비정상 데이터 각각 19%, 1.3% 낮았습니다. 추가적으로 각 모델별로 문장을 토큰화하여 ‘unknown token’ 발생 개수를 확인한 결과(그림 6), KcBERT가 KoBERT 대비 ‘unknown token’이 발생하는 문장이 적었습니다. 이에 따라 우리는 KcBERT를 사용함으로써 ‘unknown token’을 효과적으로 줄이고 학습 성능을 높일 수 있을 것이라 판단하였습니다.
그림 6. unknown token 개수별 분포
둘째, L-타입 모델을 보완해주는 역할로써 모니터링 대상 건수를 줄여 실무 담당자들에게 부담을 덜어줄 수 있는 모델이 무엇인지 살펴보았습니다.
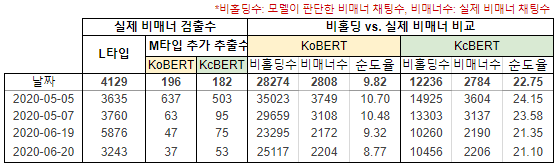
그림 7. 모델별 비매너 채팅 탐지 결과
M-타입 비매너 탐지 결과 L-타입 대비 비매너 채팅을 KoBERT, KcBERT 각각 196건, 182건 추가 추출이 가능하였습니다. 모델이 판단한 비매너 채팅에서 실제 유효한 비매너 채팅 포함률은 각각 9.82%, 22.75%이었습니다. KoBERT 대비 KcBERT 모델이 추가 추출수가 14건 적지만 비매너 포함률이 약 13% 높아 적은 범위에서 비매너 채팅을 최대한 포함시키기 때문에 실무 담당자의 부담을 덜어줄 수 있을 것이라 판단했습니다. M-타입 모델은 채팅 데이터의 비매너 점수를 출력하게 되고 해당 점수를 백오피스에서 내림차순하여 데이터를 제공함으로써 모수를 줄여줄 수 있습니다.
결과
우리는 L-타입, M-타입 모델을 통합하여 하이브리드 모델을 구성하였고 그 결과를 대시보드로 확인할 수 있도록 제공하였습니다. 시스템에서는 필터링 되지 않은 우회된 욕설을 탐지하는 것과 비매너 채팅일 확률이 높은 순으로 정렬하는 기능입니다. 로직형과 딥러닝을 이용한 비매너 채팅 탐지기는 이렇게 실무에 부담을 덜어줄 수 있는 형태로 완성되었습니다. 우회된 욕설뿐만 아니라 문맥을 고려하여 판단하는 형태는 실제 실무에 많은 도움이 되고 있습니다. 대시보드에는 비매너 점수 우선 정렬을 하여 비매너 확률이 높은 순서대로 보여줌으로써 더 효율적으로 업무 할 수 있도록 제공하였습니다.
마지막으로, 상대적으로 비매너 채팅의 데이터 개수가 적었던 우리는 비매너 태깅 시스템을 도입하고 담당자들이 비매너 데이터를 태깅하여 신규 데이터를 쌓을 수 있도록 태깅 시스템을 추가하였습니다. 태깅 시스템을 통해 쌓인 신규 데이터는 학습 데이터로 활용할 수 있으며 머신러닝 파이프라인을 자동화하여 지속적으로 학습이 가능한 시스템도 구축하였습니다.
채팅 어뷰징 탐지 시스템 도입 후, 업무 담당자로부터 전체 채널을 약 한 시간 내외로 모니터링하는 것이 가능해졌다고 피드백을 받았습니다. 해당 서비스를 만들고 보완하며 인공지능의 특장점을 경험할 수 있었고, 인공지능을 통해 절약한 시간으로 우리는 더 많은 것을 할 수 있게 되어 뿌듯하게 생각하고 있습니다.
게임을 사랑하는 유저들에게 무고한 제재가 있으면 안 되는 상황에서 게임 모니터링 업무를 인공지능으로 대체를 할 수는 없습니다. 그러나 사람을 도와주고 보조하는 역할의 인공지능은 업무의 효율을 충분히 높여주고 있고 이젠 없어서는 안 될 존재입니다.
비매너 채팅 탐지 뿐만 아니라 이상 행동 탐지, 아이템 추천 시스템 등 게임 많은 부분에 인공지능이 사용될 수 있다고 생각합니다. 급속도로 발전하는 AI 기술을 뒤쳐지지 않게 습득하고 더 다양하게 적용하고 확장할 수 있도록 우리는 최선을 다할 것입니다.
이상 데이터 사이언스 파트를 마치며 엔지니어링 파트에서 서비스 구조와 부하 분산을 위한 설계에 대한 내용을 다루겠습니다.