










관련글

Under the Hood: Linux Epoll — 리눅스 커널 소스코드로 살펴보는 epoll의 내부 동작
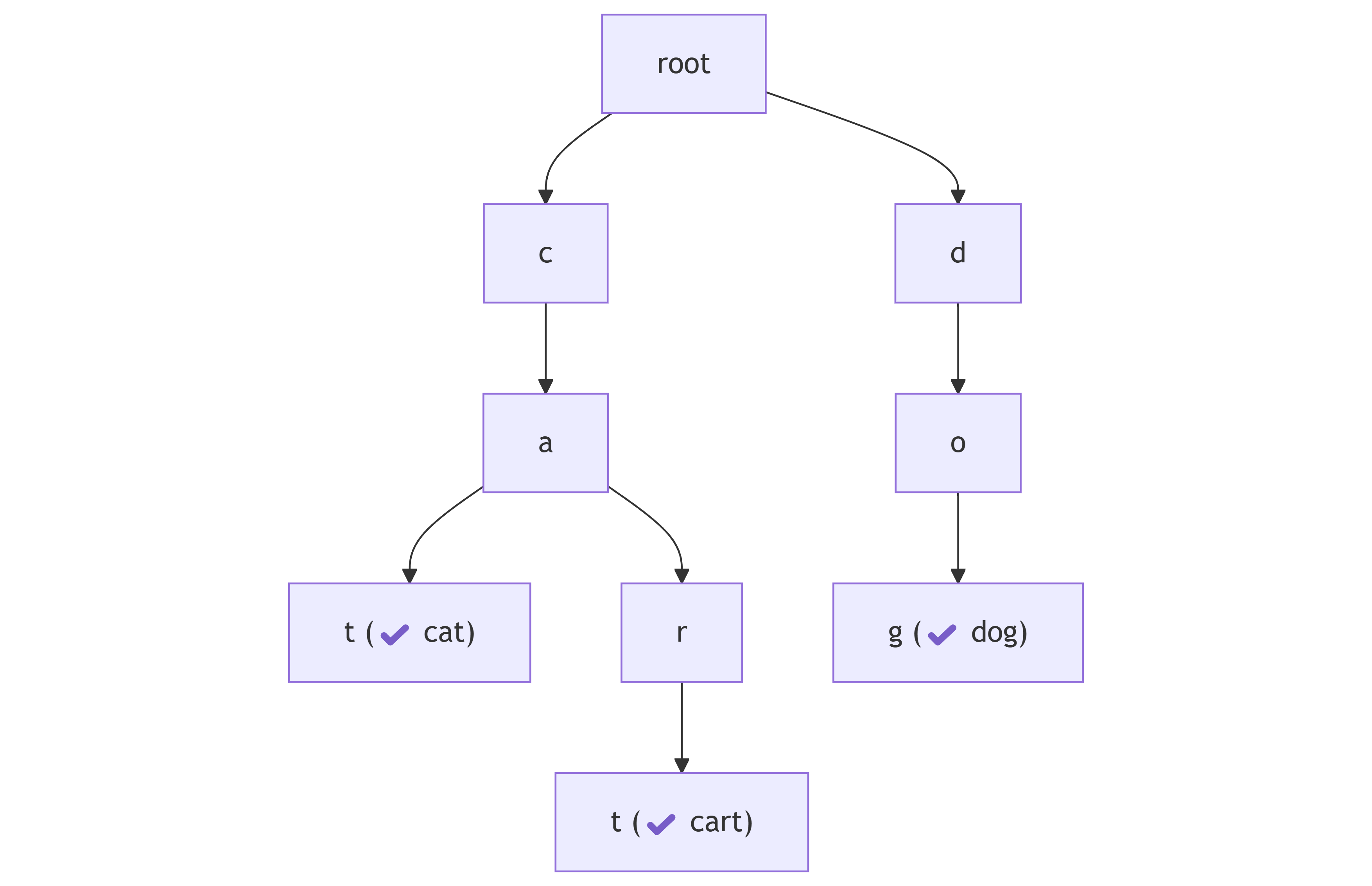
개론 클라이언트의 요청을 처리하는 서버를 구축할 때는 일반적으로 TCP, UDP 프로토콜을 기반으로 통신을 처리한다. 이때 모든 네트워크 통신은 기본적으로 소켓(Socket)이라는 단위를 통해 관리된다. 아키텍처 관점에서 보면 하나의 프로세스 또는 스레드가 하나 이상의 소켓을 동시에 처리할 수 있다. 하지만 여러 소켓을 효율적으로 처리하려면 I/O Multiplexing(입출력 다중화) 메커니즘이 필요하다. 이를 통해 단일 스레드 또는 프로세스가 여러 I/O […]

웹 상점은 혼자 크지 않는다: 커뮤니티·PG 결제가 완성하는 게임 매출 구조
게임 산업에서 웹 상점은 이제 선택지가 아니라 전략 그 자체가 되었다. 앱 마켓 수수료 절감, 낮은 결제 수수료를 통한 수익 개선, 유연한 글로벌 결제 전략 구성. 표면만 놓고 보면 웹 상점은 더없이 매력적인 무기다. 특히 모바일 게임 시장에서는 앱 마켓의 수수료 구조를 벗어나기 위해 웹 상점을 도입하는 흐름이 빠르게 확산되고 있다. 그런데 정작 많은 게임사들이 […]

WebRTC TURN/STUN 서버 구축기: COTURN으로 연결 성공률 높이기
1. 안녕하세요! COTURN입니다. (그런데 누구신지?) WebRTC에서 “연결이 왜 안 되지?”라는 문제를 파고들면 결국 ICE(Interactive Connectivity Establishment) 과정과 마주하게 된다. ICE는 두 단말이 서로 통신 가능한 경로 후보(candidate)를 수집하고, 그중 최적의 경로를 선택하여 연결하는 절차다. COTURN은 ICE 과정에서 필요한 STUN/TURN 서버 역할을 수행하는 대표적인 오픈소스 구현체다. P2P가 가능한 환경에서는 연결을 빠르고 간편하게 만들고, P2P가 불가능한 환경에서는 […]

AI 디자인의 현재와 미래를 엿보다: IMAGINE 2026 참관기
데이터야놀자가 주최하고 AI 디자이너 김진영 작가가 기획한 <IMAGINE 2026 with Dnol>은 AI 디자인과 아트의 최전선에서 활동하는 12명의 크리에이터가 한자리에 모인 뜻깊은 자리였다. 각 연사는 자신의 프로젝트 경험을 바탕으로 AI를 어떻게 해석하고 실제 실무에 활용하고 있는지 생생한 인사이트를 공유했다. 현재 팀 내 AI 스터디에 참여하며, 단순한 툴 사용법을 넘어 AI와 디자인 전반에 대한 지식을 쌓고 실습 […]

컨테이너 환경에서의 eBPF/XDP 로드밸런서 Deep Dive
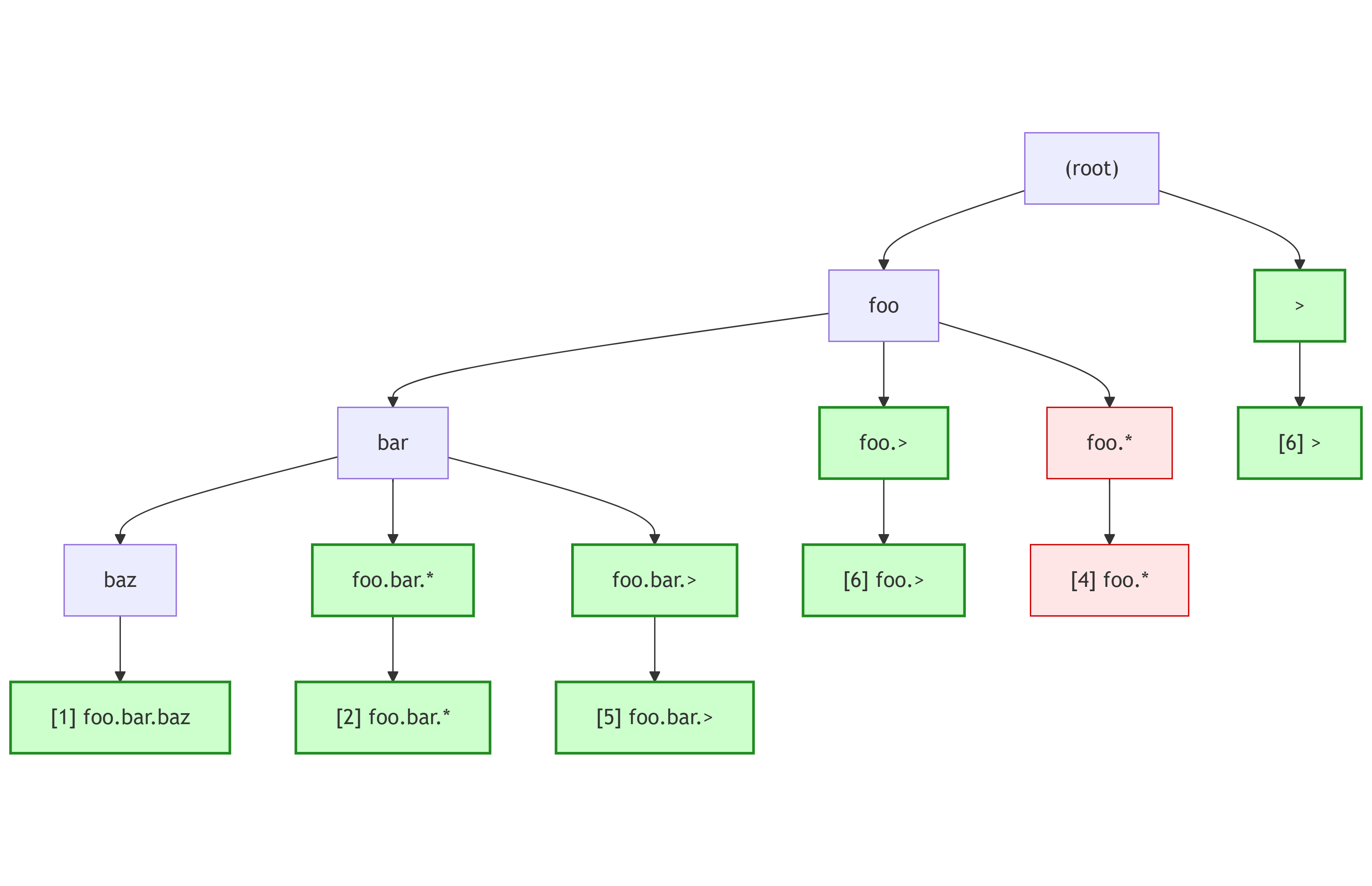
클라이언트의 요청을 여러 개의 멀티 인스턴스 형태 서버에 로드밸런싱하려면, 앞단에서 패킷을 받아 포워딩해주는 로드밸런서 서버가 필요하다. 하지만 일반적인 로드밸런서는 애플리케이션 단까지 패킷을 수신하고 다시 전송하기까지 비용이 크다. NIC에서 수신된 패킷을 기반으로 커널 내에서 SKB를 만들고, 만들어진 SKB는 리눅스 커널 네트워크 스택을 통과한다. 이후 유저 영역의 소켓 버퍼로 메모리를 복사해야 하는데, 이 과정에는 컨텍스트 전환이 포함돼 […]

AWS re:Invent 2025: AI 에이전트와 인프라 혁신의 최전선을 가다
AWS re:Invent란 무엇인가 AWS re:Invent는 전 세계 클라우드 개발자, 엔지니어, 아키텍트가 한자리에 모이는 연례 최대 클라우드 기술 컨퍼런스다. 매년 미국 라스베이거스에서 열리는 이 행사는 2025년 11월 30일부터 12월 4일까지 5일간 진행되었으며, 6만여 명이 참석했다. 기조연설에서 발표되는 AWS의 최신 서비스와 기능, 수백 개의 기술 세션, 핸즈온 랩, 워크숍이 펼쳐지며 클라우드 기술을 깊이 있게 학습할 수 있다. […]

웹 보안의 기준을 세우다: OWASP가 알려주는 안전한 보안의 길
안전한 웹을 위한 선택이 아닌 필수 요즘 뉴스에서 사이버 공격 이야기가 하루가 멀다 하고 들려온다. 그만큼 우리에게 안전한 웹 서비스는 선택이 아닌 필수가 되었다. 이런 변화 속에서 전 세계의 보안 전문가와 개발자들이 함께 머리를 맞대고 ‘안전한 인터넷 세상’을 만들기 위해 힘을 모은 단체가 있다. 바로 ‘OWASP(Open Web Application Security Project)’이다. OWASP는 누구나 참여할 수 있는 […]

Istio Profile 활용법으로 배우는 Helm Chart 심화 가이드
Istio의 Ambient mode 도입을 위해 리서치를 진행하던 중, 일부 설정 값이 예상과 달리 적용되지 않는 문제를 마주했다. 원인을 파악하기 위해 Istio의 Helm 차트를 깊이 있게 분석했고, 이 과정에서 알게 된 Profile 주입 방식과 차트 템플릿 렌더링 순서에 대한 내용을 공유하고자 한다. Helm 차트란? Helm 차트는 쿠버네티스(Kubernetes) 리소스를 템플릿화하여 재사용성과 유지보수성을 높여주는 패키징 도구다. 애플리케이션 배포에 […]
