클라이언트의 요청을 처리하는 서버를 구축할 때는 일반적으로 TCP, UDP 프로토콜을 기반으로 통신을 처리한다. 이때 모든 네트워크 통신은 기본적으로 소켓(Socket)이라는 단위를 통해 관리된다.
아키텍처 관점에서 보면 하나의 프로세스 또는 스레드가 하나 이상의 소켓을 동시에 처리할 수 있다. 하지만 여러 소켓을 효율적으로 처리하려면 I/O Multiplexing(입출력 다중화) 메커니즘이 필요하다. 이를 통해 단일 스레드 또는 프로세스가 여러 I/O 이벤트를 동시에 감시하고 처리할 수 있다.
리눅스에서는 이러한 입출력 다중화를 지원하기 위해 select, poll, epoll과 같은 API를 제공한다. 그중에서도 epoll은 대규모 동시 연결 환경에서 높은 효율을 제공하는 메커니즘으로 널리 사용된다.
이번 글에서는 epoll의 사용 방법 자체보다는 리눅스 커널 소스코드 관점에서 epoll이 내부적으로 어떻게 동작하는지를 살펴보려 한다. 특히 리눅스 커널 내부 구조와 데이터 흐름을 중심으로 epoll의 동작 과정을 단계적으로 분석한다.
주의 사항
커널 버전: 리눅스 커널 6.19.3 버전을 기준으로 설명하며, 타 버전과는 구현 세부 사항에서 차이가 있을 수 있다.
참고용 자료: 방대한 소스코드를 분석한 내용이므로 실제 커널의 모든 예외 처리를 담고 있지는 않다.
비교 배제: 본 글에서는 select나 poll과의 성능 비교보다는 epoll 자체의 내부 로직에 집중한다.
본론: epoll의 내부 동작 원리
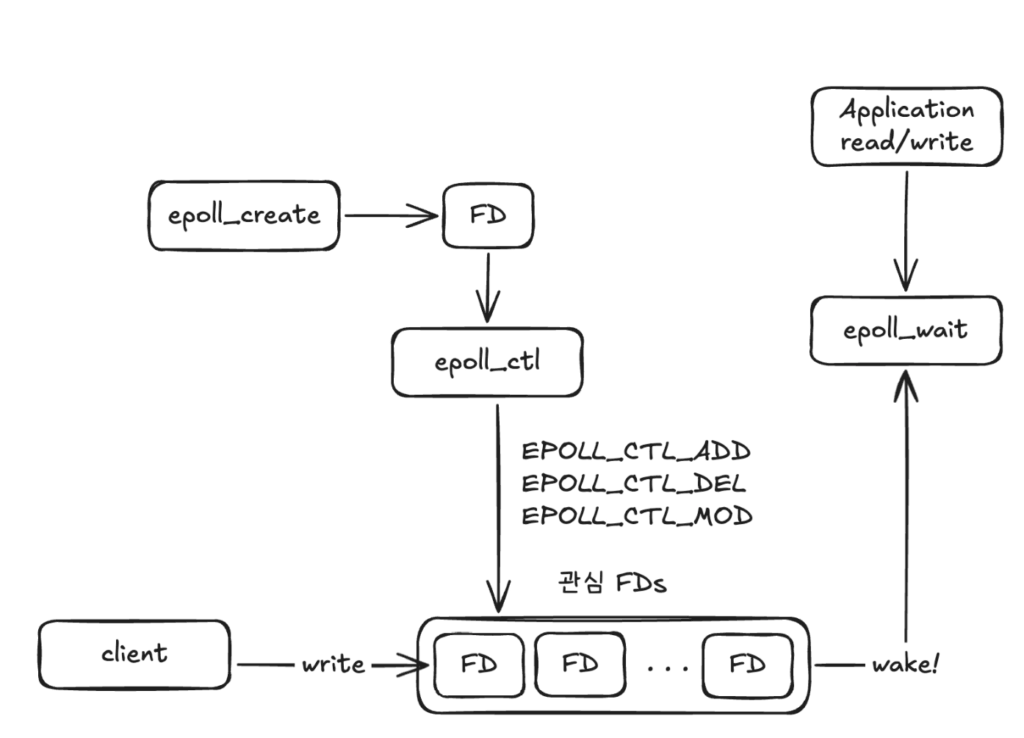
epoll 인터페이스를 구성하는 syscall은 세 가지다. epoll_create, epoll_ctl, epoll_wait이다. 기본적인 소켓 서버에서 클라이언트 요청을 처리하는 흐름은 아래 다이어그램과 같다.
동작 순서를 간략히 설명하면 다음과 같다. epoll_create로 epoll 파일 디스크립터(epollfd)를 생성하고, epoll_ctl을 통해 관심 FD 목록에 원하는 소켓을 등록한다. 이후 해당 FD에 Read/Write 이벤트가 발생하면 epoll_wait syscall에 의해 블로킹 상태에서 깨어나며, 이벤트를 발생시킨 FD를 처리할 수 있게 된다. 지금부터 각 syscall을 순서대로 살펴보자.
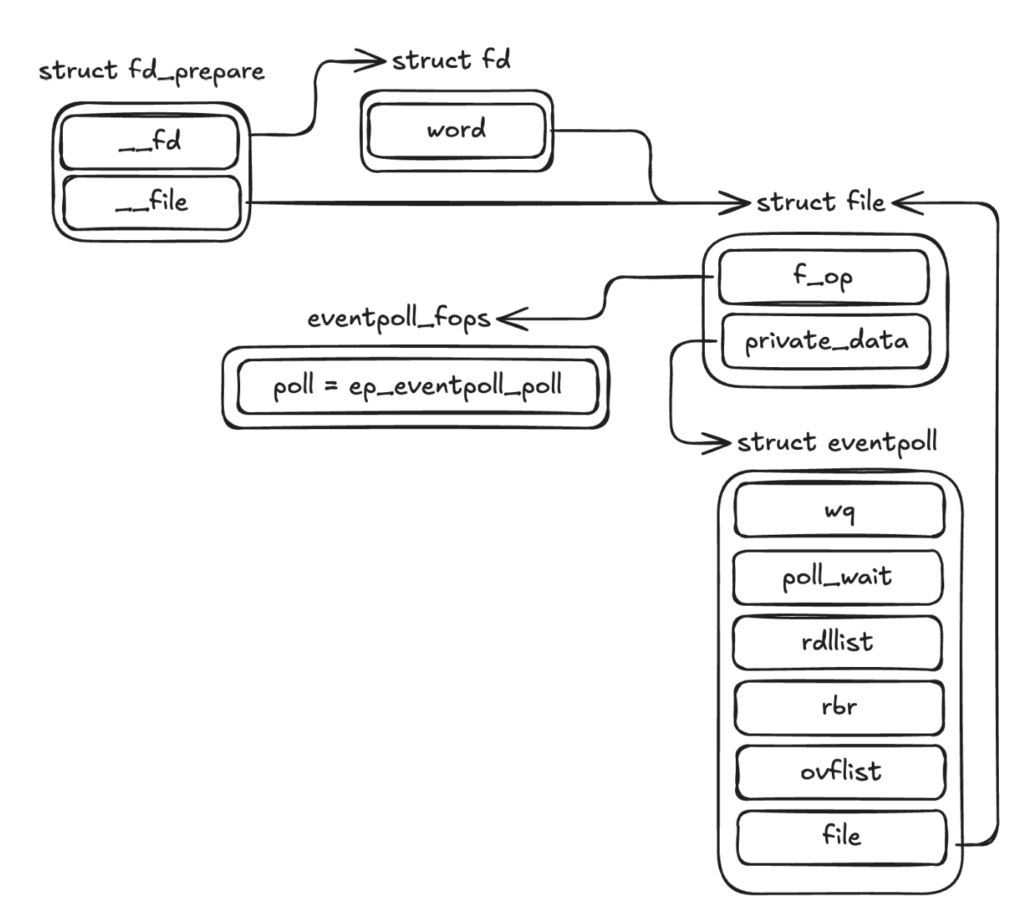
ep_alloc 함수는 struct eventpoll 구조체를 할당한다. anon_inode_getfile 함수는 하나의 파일 인스턴스(struct file)를 생성하고, 그 내부 private_data 필드에 방금 할당한 struct eventpoll을 주입하며, f_op 필드에는 eventpoll_fops를 등록한다. FD_PREPARE 매크로 함수는 struct fd와 struct file을 준비하고, fd_prepare_file을 통해 생성된 struct file을 struct eventpoll의 file 필드에 연결한다. 마지막으로 fd_publish가 fd와 struct file을 맵핑하여 사용자 공간에 반환 가능한 파일 디스크립터를 완성한다.
리눅스의 가상 파일 시스템(Virtual File System, VFS)은 커널 내 소프트웨어 계층으로, 사용자 공간 프로그램에 일관된 파일 시스템 인터페이스를 제공한다. 또한 커널 내부에서 추상화 계층으로 동작하여 서로 다른 파일 시스템 구현이 공존할 수 있도록 한다. 여기서 private_data는 해당 파일 인스턴스가 실제로 가리키는 커널 객체 포인터이고, f_op는 VFS가 열린 파일을 조작하는 방법을 정의하는 함수 테이블이다. f_op에는 read, write, poll 등의 연산이 포함되며, poll은 프로세스가 특정 파일에 대한 I/O 활동 여부를 확인하고 필요하다면 대기할 때 호출된다. select, epoll 등의 syscall이 대표적인 호출 주체이다. VFS에 대한 자세한 내용은 공식 커널 문서(https://docs.kernel.org/filesystems/vfs.html)를 참고하기를 권장한다.
여기까지 정리하면, epoll_create는 struct eventpoll 구조체 하나를 할당하고 이를 파일로 관리한다는 것이 핵심이다.
struct eventpoll의 각 필드를 아래에 정리한다.
structeventpoll {/* Wait queue used by sys_epoll_wait() */wait_queue_head_twq;/* Wait queue used by file->poll() */wait_queue_head_tpoll_wait;/* List of ready file descriptors */structlist_headrdllist;/* RB tree root used to store monitored fd structs */structrb_root_cachedrbr;/* * This is a single linked list that chains all the "struct epitem" that * happened while transferring ready events to userspace w/out * holding ->lock. */structepitem *ovflist;structfile *file;};
wq: epoll_wait를 호출한 프로세스의 wait 엔트리를 담는 연결 리스트이다. 관리 중인 FD에 이벤트가 발생하면 ep_poll_callback 함수가 호출되어 해당 프로세스를 깨운다.
poll_wait: 모니터링 대상이 다른 epoll 인스턴스일 경우 그 인스턴스의 wait queue로 동작한다.
rdllist: 이벤트가 발생하여 처리 대기 중인 FD 목록이다.
rbr: 전체 감시 대상 FD 집합을 레드블랙 트리로 관리한다.
ovflist: epoll이 감시 대상 FD 집합을 스캔 중일 때 rdllist에 직접 추가하지 못하는 이벤트를 임시로 연결해두는 리스트이다.
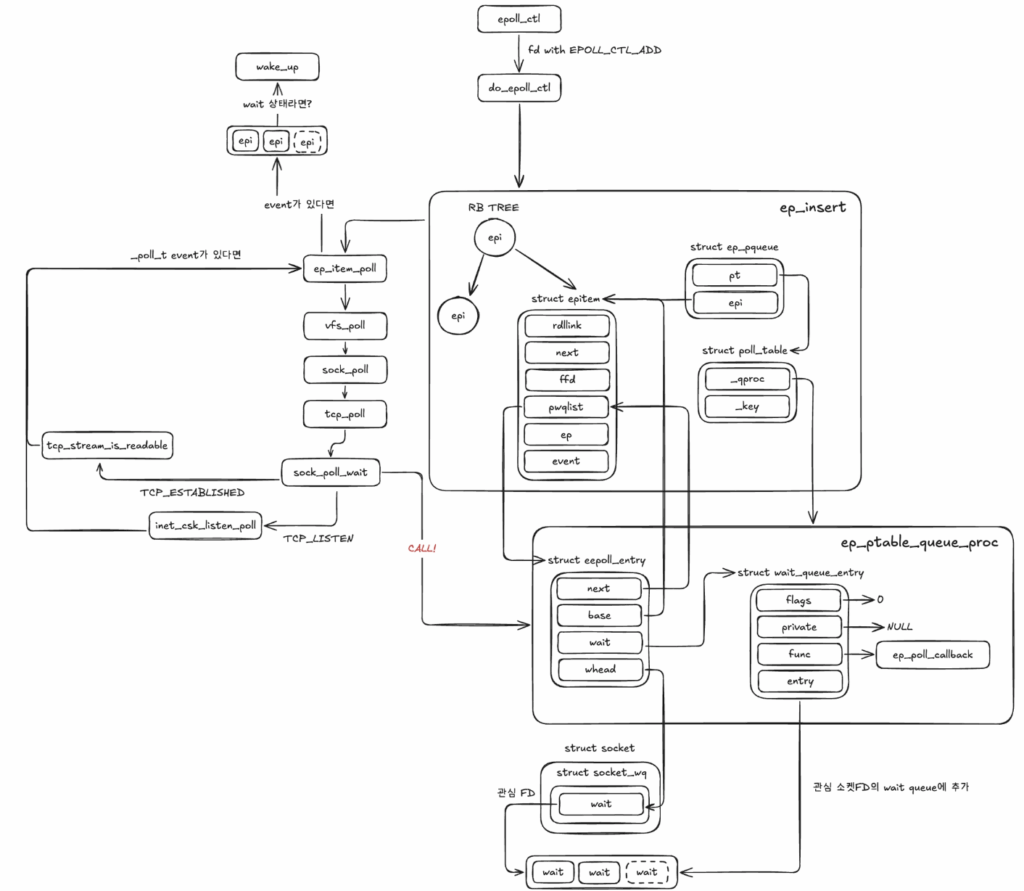
사용자 공간에서 특정 파일 디스크립터를 감시 목록에 추가·수정·제거하려면 epoll_ctl syscall을 이벤트 정보와 함께 호출한다. 커널 내부에서는 do_epoll_ctl 함수가 실행된다. 인자로 전달된 epfd는 파일 디스크립터이며 내부적으로 struct file로 관리된다. 앞서 epoll_create에서 private_data에 epoll 인스턴스를 주입했음을 떠올리면 이해가 쉽다. ep_find 함수는 등록하려는 FD가 이미 관심 목록에 있는지 검색하고, 없으면 NULL을 반환한다. 이후 op 값에 따라 EPOLL_CTL_ADD(추가), EPOLL_CTL_MOD(수정), EPOLL_CTL_DEL(삭제) 연산이 분기된다. 추가의 경우 ep_insert 함수를 통해 레드블랙 트리에 struct epitem을 삽입한다.
staticintep_insert(structeventpoll *ep, conststructepoll_event *event,structfile *tfile, intfd, intfull_check){__poll_trevents;structepitem *epi;structep_pqueueepq;[...]epi = kmem_cache_zalloc(epi_cache, GFP_KERNEL)[...]ep_rbtree_insert(ep, epi);/* Initialize the poll table using the queue callback */epq.epi = epi;init_poll_funcptr(&epq.pt, ep_ptable_queue_proc);revents = ep_item_poll(epi, &epq.pt, 1);/* If the file is already "ready" we drop it inside the ready list */if (revents && !ep_is_linked(epi)) {list_add_tail(&epi->rdllink, &ep->rdllist);ep_pm_stay_awake(epi);/* Notify waiting tasks that events are available */if (waitqueue_active(&ep->wq))wake_up(&ep->wq); }return0;}static__poll_tep_item_poll(conststructepitem *epi, poll_table *pt,intdepth){structfile *file = epi_fget(epi);__poll_tres;/* * We could return EPOLLERR | EPOLLHUP or something, but let's * treat this more as "file doesn't exist, poll didn't happen". */if (!file)return0;pt->_key = epi->event.events;if (!is_file_epoll(file))res = vfs_poll(file, pt);elseres = __ep_eventpoll_poll(file, pt, depth);fput(file);returnres & epi->event.events;}
ep_insert는 struct epitem 하나를 할당한 뒤 ep_rbtree_insert로 레드블랙 트리에 삽입한다. 이어서 ep_pqueue의 pt 필드에 ep_ptable_queue_proc 함수를 등록하고, ep_item_poll을 호출하여 epoll_wait 진입 이전에 이미 발생한 이벤트가 있는지 확인한다. 내부적으로는 vfs_poll 함수 포인터, 즉 file->f_op->poll(file, pt) 구조로 호출이 이어진다.
여기서 대상 파일은 epoll 인스턴스가 아니라 등록하려는 소켓의 FD다. 소켓이라면 sock_poll로, TCP 소켓이라면 tcp_poll로 확장된다.
tcp_poll에서 등록 대상 소켓은 크게 두 가지 상태일 수 있다. 서버 소켓이라면 TCP_LISTEN 상태이고, 클라이언트 소켓이라면 3-way handshake가 완료된 TCP_ESTABLISHED 상태이다. TCP_LISTEN 상태에서는 inet_csk_listen_poll 함수를 호출하여 accept queue에 대기 중인 연결 요청이 있는지 확인한다. TCP_ESTABLISHED 상태에서는 tcp_stream_is_readable 함수로 읽을 수 있는 데이터가 수신 버퍼에 존재하는지 확인하고, 있으면 EPOLLIN 마스크를 설정한다.
두 번째 인자 &sock->wq.wait는 감시 대상 소켓의 wait queue이다. init_waitqueue_func_entry를 통해 이벤트 발생 시 호출할 콜백 함수로 ep_poll_callback을 등록한다. 사용자가 EPOLLEXCLUSIVE 이벤트를 포함하여 등록했다면 add_wait_queue_exclusive를 호출하고, 그렇지 않다면 add_wait_queue를 호출하여 소켓의 wait queue에 현재 프로세스의 wait 엔트리를 FIFO 또는 LIFO 방식으로 삽입한다.
ep_insert로 돌아오면, revents 값이 1 이상이라는 것은 epoll_wait 진입 전에 이미 이벤트가 발생했음을 의미한다. 이 경우 해당 epitem을 ep->rdllist에 즉시 추가한다. 그리고 대기 중인 프로세스가 있다면(waitqueue_active) wake_up 매크로를 호출하여 콜백을 트리거한다. 이때 호출되는 콜백의 핵심은 아래와 같다.
curr->func 함수 포인터가 앞서 등록한 ep_poll_callback이다. 해당 함수의 상세 내용은 이후 epoll_wait 절에서 설명한다.
epoll_ctl의 전체 흐름은 아래 다이어그램으로 정리한다.
요약하면 EPOLL_CTL_ADD 연산은 감시 대상 FD에 해당하는 struct epitem을 하나 생성하고, 해당 소켓의 wait queue에 ep_poll_callback을 콜백으로 가진 wait 엔트리를 등록하는 과정이다. 이후 해당 소켓에 읽기·쓰기 이벤트가 발생하면 이 콜백이 자동으로 트리거된다. 아울러 epoll_wait 호출 이전에 이미 발생한 이벤트가 있는지도 이 단계에서 함께 확인한다.
관련 구조체를 참고용으로 정리한다.
/* epoll이 관심 대상 파일의 wait queue에 등록하는 엔트리.*/structeppoll_entry {structeppoll_entry *next;structepitem *base;wait_queue_entry_twait;wait_queue_head_t *whead;};/* wait queue에 엔트리 등록 과정에서 사용하기 위함. (poll 시스템과 epoll 시스템 연결)*/structep_pqueue {poll_tablept;structepitem *epi;};/* 관심 대상 FD당 하나 epitem 생성 및 할당*/structepitem {union {structrb_noderbn;structrcu_headrcu; };// 활성화된 이벤트가 있을 경우 epoll instance의 rdllist에 연결structlist_headrdllink;structepitem *next;structepoll_filefdffd;// epitem이 등록한 모든 wait queue 엔트리 리스트structeppoll_entry *pwqlist;structeventpoll *ep;structhlist_nodefllink;structwakeup_source__rcu *ws;structepoll_eventevent;};
epoll_wait
epoll_create로 epoll 인스턴스를 생성하고 epoll_ctl로 감시 대상 FD 등록을 마쳤다면, 마지막으로 이벤트가 발생할 때까지 대기하는 epoll_wait syscall을 호출한다.
이벤트가 존재하면 ep_send_events를 호출하여 사용자가 전달한 events 버퍼에 최대 maxevents개만큼 복사한 뒤 반환한다. 이벤트가 없으면 루프를 계속 진행한다.
루프가 반복되는 경우, 현재 프로세스의 wait 엔트리를 하나 생성하고 프로세스 상태를 TASK_INTERRUPTIBLE로 전환한다. 블로킹 진입 직전에 마지막으로 이벤트 여부를 한 번 더 확인하고, 여전히 없으면 epoll 인스턴스의 wait queue에 해당 프로세스의 wait 엔트리를 추가한다. 이후 schedule_hrtimeout_range를 호출하여 지정된 타임아웃 동안 블로킹 상태에 진입한다.
타임아웃이 만료되거나 외부에서 강제로 깨워지면, 프로세스는 epoll 인스턴스의 wait queue에서 자신의 엔트리를 제거하고 상태를 TASK_RUNNING으로 복원한 뒤 루프 처음으로 돌아간다. 이하에서는 타임아웃이 아닌, 외부 이벤트에 의해 깨어나는 경로를 따라가 본다.
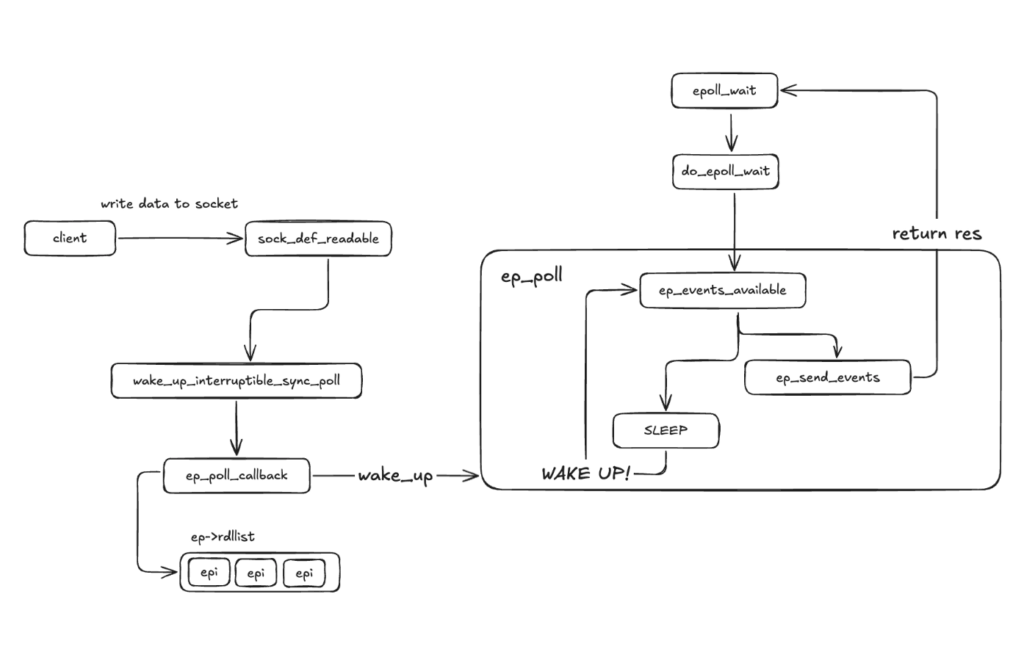
sock_def_readable은 해당 소켓의 wait queue를 가져온 뒤 wake_up_interruptible_sync_poll을 호출한다. 이때 어떤 이벤트가 발생했는지(EPOLLIN 등)를 인자로 함께 전달한다. 해당 함수는 내부적으로 __wake_up_common을 호출한다.
__wake_up_common은 소켓의 wait queue에 연결된 엔트리를 순회하며 각 엔트리의 curr->func을 호출한다. 앞서 epoll_ctl에서 등록한 ep_poll_callback이 바로 이 함수다. WQ_FLAG_EXCLUSIVE 플래그가 설정된 엔트리를 처리한 이후에는 순회를 중단한다. 이 플래그는 EPOLLEXCLUSIVE 이벤트와 함께 활성화되며, 동일 소켓의 wait queue에 여러 프로세스가 대기 중일 때 그중 하나만 깨우는 효과를 낸다.
ep_poll_callback은 먼저 list_add_tail_lockless를 호출하여 이벤트가 발생한 struct epitem을 ep->rdllist에 추가한다. 그런 다음 epoll 인스턴스의 wait queue에 대기 중인 프로세스가 있는지 확인하고, 있으면 wake_up을 호출하여 해당 프로세스를 깨운다.
프로세스가 깨어나면 ep_send_events가 호출된다. 먼저 ep_start_scan으로 스캔을 시작하고, ep->rdllist를 기반으로 각 epitem의 이벤트를 확인한 뒤 epoll_put_uevent를 통해 사용자 공간 메모리에 복사한다. 단, ep_start_scan과 ep_done_scan 사이에 새로 발생한 이벤트는 rdllist에 직접 추가되지 않고 ovflist에 임시 연결된다는 점이 중요하다. 이는 스캔 도중 리스트가 변경되어 발생할 수 있는 race condition을 방지하기 위한 설계이다.
전체 흐름을 아래 다이어그램으로 정리한다.
결론
epoll을 언제 써야 하는지에 대한 정보는 어렵지 않게 찾을 수 있다. 그러나 내부에서 어떤 일이 벌어지는지, 커널이 어떤 구조로 이 모든 것을 조율하는지에 대한 설명은 찾기 어려운 것이 현실이다. 이번 글이 epoll_create부터 ep_poll_callback 호출에 이르는 일련의 흐름을 이해하는 데 실질적인 도움이 되었기를 바란다. 소켓의 wait queue에 콜백을 등록하고, 이벤트 발생 시 커널이 직접 프로세스를 깨우는 이 구조를 이해하고 나면, epoll이 왜 대규모 연결 환경에서 효율적으로 동작하는지 그 이유도 자연스럽게 납득될 것이다.
김수창 기자
epoll을 언제 사용해야 하는지 정보는 쉽게 찾아낼 수 있지만 어떻게 동작하는지는 정보가 많이 부족하다고 생각했습니다. 이 글이 epoll의 내부로직을 이해하는 데 도움이 되었길 바랍니다.