하루에도 수많은 유저가 게임에 접속한다. 각 유저는 게임 내에서 광고 시청, 게임 플레이, 결제 등 다양한 행동 패턴을 보이고, 이 패턴은 유저마다 다르다. 다양한 행동 패턴을 보이는 유저들에게 획일화된 마케팅 활동을 전개하는 것은 게임 운영 측면에서 비효율적일 수 있다. 따라서 유저의 행동 패턴을 기반으로 게임 유저를 분류하고, 분류된 유저별 개인화된 마케팅 활동을 전개하는 것이 중요하다. Hive 애널리틱스는 이러한 합리적인 마케팅 의사결정 과정에 기여하고자 유저를 6개의 유형으로 분류하고 이를 지표화하여 제공하는데, 본 글에서는 Hive 애널리틱스의 유저 분류 지표는 어떻게 만들어졌고, 운영되고 있는지 소개한다.
같지만 다른, 다르지만 같은 게임 유저
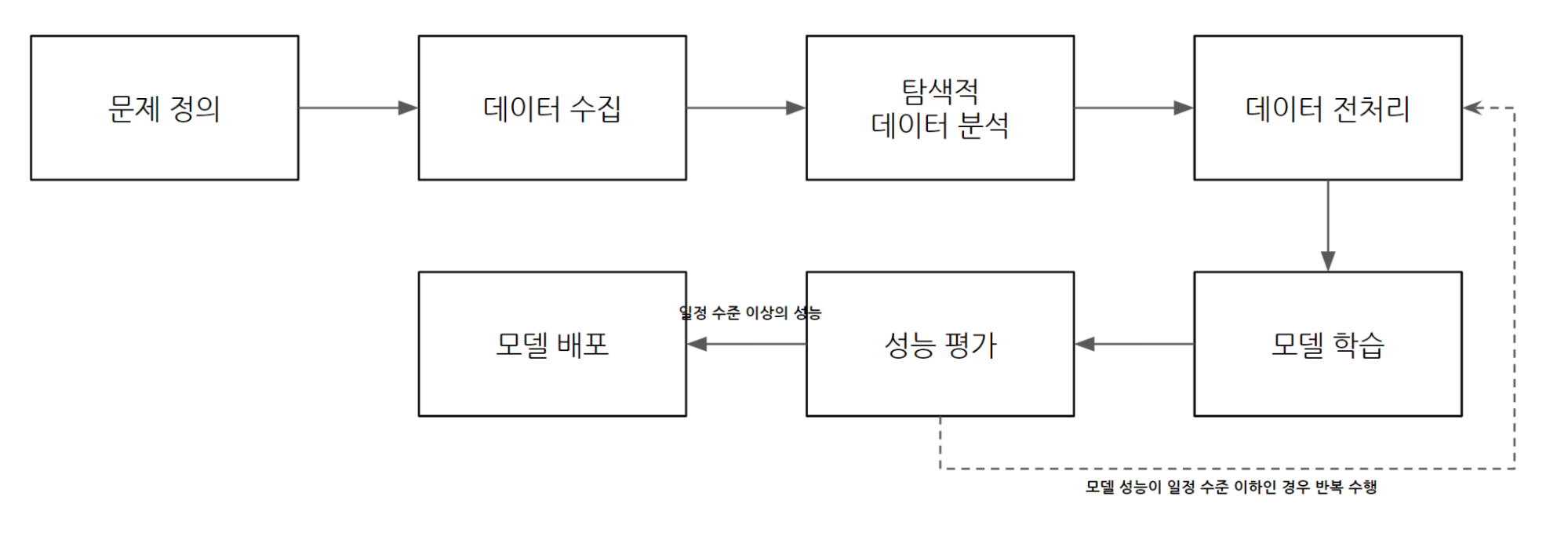
일반적으로 머신러닝 모델을 개발하여 게임 운영에 활용하기 위해 양질의 데이터를 수집하고, 각 모델 특성에 맞는 데이터로 가공하여 모델을 학습시킨 후 학습 모델에 대한 성능을 평가하는 과정을 거친다. 이때, 모델의 성능이 특정 수준 이하인 경우 데이터 전처리, 모델 학습, 성능 평가 단계를 반복하고, 모델의 성능이 특정 수준 이상인 경우에만 최종 모델을 배포하게 된다. 각 게임에서 이러한 과정을 거치며 별도로 머신러닝 모델을 구현하고, 서비스하는 데 많은 리소스가 투입될 것이므로 고객의 입장에서 큰 노력을 들이지 않고도 머신러닝 모델의 결과를 가시화하여 볼 수 있는 지표를 제공하는 것을 목표로 선정했다. 다행히 Hive에서 제공하는 게임 SDK를 연동하는 경우 로그인, 구매 등과 같은 게임 운영에 있어 기본적이지만 가장 중요한 로그를 자동으로 수집하기 때문에 데이터 수집에 대한 단계는 원활하게 진행되었고, 이 데이터를 활용하여 Hive를 연동한 전체 게임 대상 유저 분류 모델 생성을 위한 실험을 진행하였다.
머신러닝 모델 개발 워크플로
게임 유저의 게임 내 활동과 구매 패턴은 각 유저마다, 또 각 게임마다 상이하기에 어떤 유저가 진성 유저인지 특정할 수 있는 명확한 기준을 정하기 어려웠다. 지도 학습은 모델 학습 시 학습 데이터에 라벨 값을 함께 제공해야하므로 지도 학습보다는 비지도 학습을 사용하는 것으로 결정했다. 비지도 학습 중 클러스터링 알고리즘에는 K-means 클러스터링, K-medoids 클러스터링, 계층적 클러스터링 등 많은 클러스터링 알고리즘이 있지만 Hive 기본 수집 데이터는 모두 Google Bigquery에 저장되어 있었기 때문에 Google BigqueryML 솔루션의 K-means 클러스터링 알고리즘을 검토했다. BigqueryML 솔루션을 사용하는 경우 데이터 저장소에서 대용량 데이터를 내보낼 필요가 없으며, 하이퍼 파라미터 튜닝, 데이터 전처리를 자동으로 수행하여 최적의 머신러닝 모델을 생성해주어 개발 속도가 향상된다는 장점이 있었기에 BigqueryML 솔루션을 활용하여 실험을 진행했다.
데이터 선정
Hive를 연동한 전체 게임을 대상으로 모델을 생성하기 위해 재화 변동, 콘텐츠 플레이 이력 등 게임별 커스텀한 데이터를 사용하기보다 로그인, 구매 등 모든 게임에 공통으로 발생하는 이벤트에 대한 데이터를 검토했고, 로그인, 게임 플레이타임, 광고 시청, 푸시, 구매 데이터를 활용하는 것으로 결정했다.
유저 분류 모델 학습 개요
게임 유저의 게임 내 행동을 활동과 구매로 나누어 유저의 게임 내 활동력은 로그인, 게임 플레이타임, 광고 시청, 푸시 데이터를 기반으로, 구매력은 구매 데이터를 기반으로 정의하여 활동력과 구매력에 대한 K-means 클러스터링 모델을 각각 학습했다. K-means 클러스터링에서 K의 개수를 정하는 방법은 elbow method 또는 실루엣 계수를 이용하는 방법 등이 있지만, K의 개수가 너무 커지는 경우 유저 집단을 과도하게 세분화하여 클러스터링 결과 해석과 사용자군에 대한 특징을 파악하기 어렵다는 단점이 있어 K의 개수를 3으로 결정했다.
활동력 모델
게임 유저의 활동은 최근 정보를 기준으로 학습하기 위해 유저 접속일 기준 이전 3일 간 활동 데이터를 활용하여 클러스터링 모델을 학습한다.
[모델 피쳐(총 31개)]
기준일 포함 이전 3일 간 로그인 횟수
기준일 포함 이전 3일 간 로그인 일수
기준일 포함 이전 3일 간 일 평균 로그인 횟수(로그인 횟수 / 로그인 일수)
기준일 포함 이전 3일 간 게임 플레이타임 합(초)
기준일 포함 이전 3일 간 일 평균 게임 플레이타임
기준일 포함 이전 3일 간 00시~23시 시간대별 게임 플레이타임 평균(초)
기준일 포함 이전 3일 간 보상형 광고 시청 횟수
기준일 포함 이전 3일 간 푸시 오픈 여부
구매력 모델
게임 유저의 구매는 게임에 대한 긍정적인 반응이므로 최근 정보보다는 유저 생애 기간(최초 접속일 ~ 접속 기준일)동안의 정보를 기준으로 학습하는 것이 게임에 대한 지속적인 반응을 확인할 수 있을 것으로 생각되어 유저 최초 접속 ~ 접속 기준일까지의 구매 데이터를 활용하여 클러스터링 모델을 학습한다.
[모델 피쳐(총 3개)]
유저 최초 접속 ~ 첫 구매까지 소요시간(단위 : 일)
유저 최초 접속 ~ 기준일까지 유저 총 과금 건 수
유저 최초 접속 ~ 기준일까지 과금 1회 당 평균 과금액(유저 총 과금액 / 유저 총 과금 건 수)
유저 분류 모델 학습 & 분류 수행
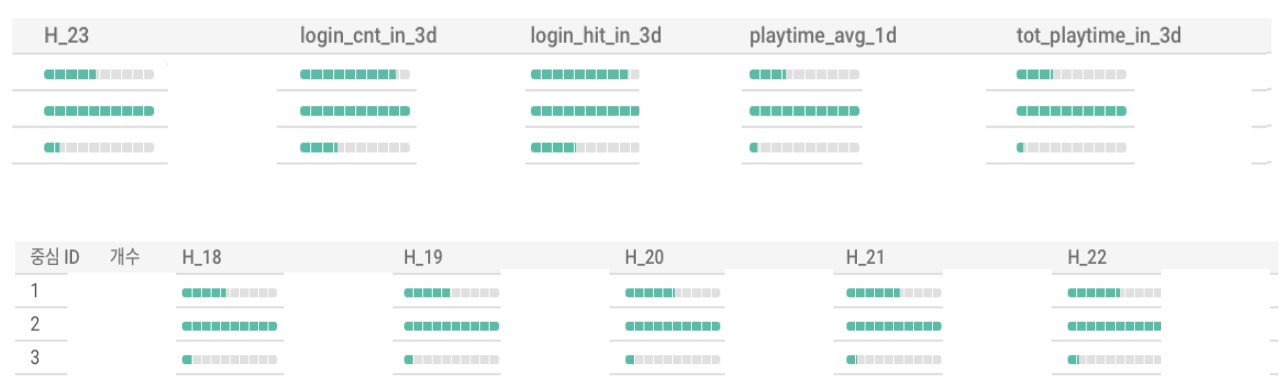
Hive를 연동한 게임의 유저를 대상으로 활동력, 구매력 클러스터링 모델을 생성하였고, 각 클러스터별 중심점 정보를 통해 클러스터링 결과를 아래와 같이 해석할 수 있었다.
활동력 모델
중심 ID=1: 게임 활동 활성도 중간, 3일 기준 접속 일 수, 접속 횟수가 ‘중심ID=2’와 비슷하지만 평균 플레이타임에서 큰 차이를 보임
중심 ID=2: 게임 활동 활성도가 가장 좋음
중심 ID=3: 게임 활동 활성도가 낮음
구매력 모델
중심 ID=1: 게임 유입 후 첫 구매 시간이 가장 느림, 과금액 및 과금 건수가 가장 작음
중심 ID=2: 게임 유입 후 첫 구매 시간이 가장 빠름, 과금액 및 과금 건 수가 가장 많음
중심 ID=3: 게임 유입 후 첫구매 시간이 두 번째로 빠르며, 과금액 및 과금 건 수가 중간
비구매: 비구매 유저 따로 그룹 할당
생성된 활동력, 구매력 모델을 기반으로 6월 2일 일 활성 유저를 분류한 후 분류 결과를 비율 분포(단위: %)로 확인했다.
모델
구매력 ID=1
구매력 ID=2
구매력 ID=3
비구매
활동력 ID=1
1.6
2.3
12.3
13.3
활동력 ID=2
0.4
0.6
2.1
2.2
활동력 ID=3
2.7
2.4
20.9
39.2
활동력 모델과 구매력 모델에서 가장 좋은 수치를 보인 게임 활동 중심 ID = 2와 구매 중심 ID = 2 유저(이하 활동력/구매력 높은 유저)의 비율은 일 활성 유저 중 0.6%를 차지했고, 활동력 모델에서 가장 활성도가 낮았던 중심 ID = 3과 비구매 유저의 비율(이하 활동력 낮음/비구매 유저)은 DAU 중 39.2%로 가장 많았다. 게임 내 활동력과 구매력이 모두 높아 진성 유저라고 할 수 있는 유저 비율이 소수라는 점과 비교적 활동력이 낮은 유저 중 비구매 유저가 다수라는 점이 실제 모바일 게임 산업의 현실을 반영하는 것 같아 인상 깊었다. 이후 진성 유저 유형과 일반 유저 유형으로 분류된 유저들은 향후 게임 내에서 어떤 행동 패턴을 보일지에 대한 궁금증이 생겼고, 해당 유저 군을 트래킹하기 위한 사후 데이터 분석을 진행했다.
사후 데이터 분석
6/2 일 활성 유저 중 활동력/구매력 높은 유저 유형과 활동력 낮음/비구매 유저 유형으로 분류된 유저를 대상으로 6/3 ~ 7/2까지 30일간 게임 활동 및 구매 관련 지표를 분석했으며, 그 내용은 다음과 같다.
접속 일 수별 유저 비율 분석
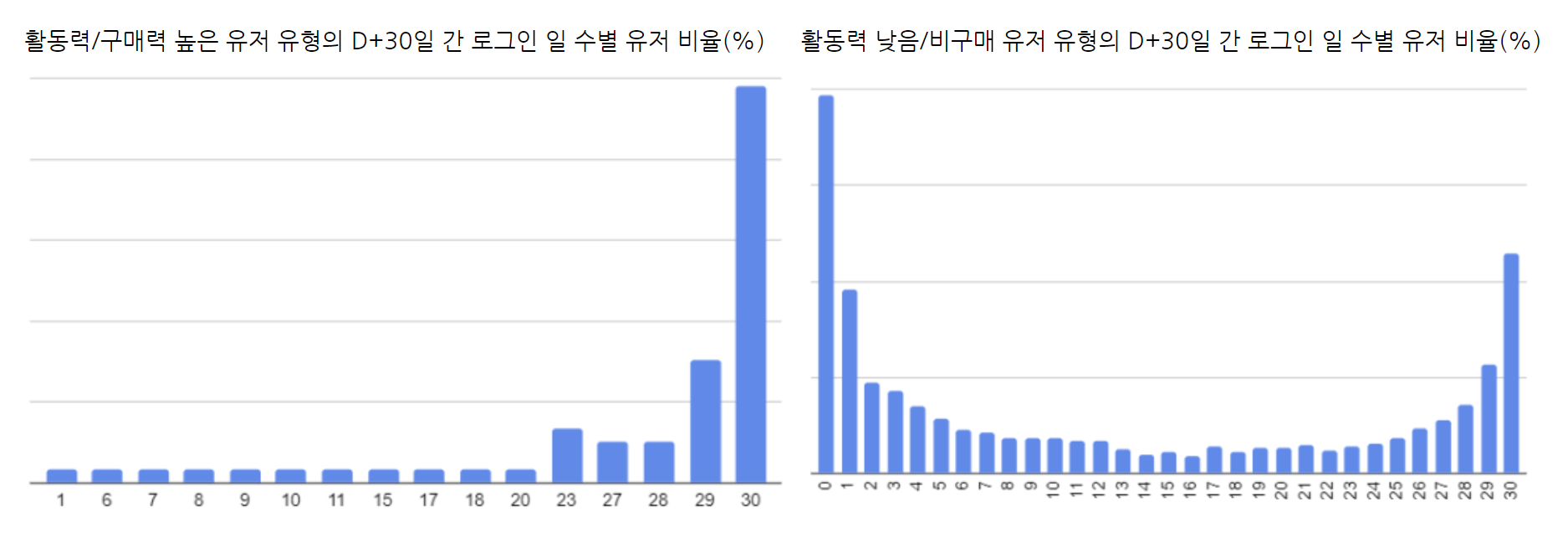
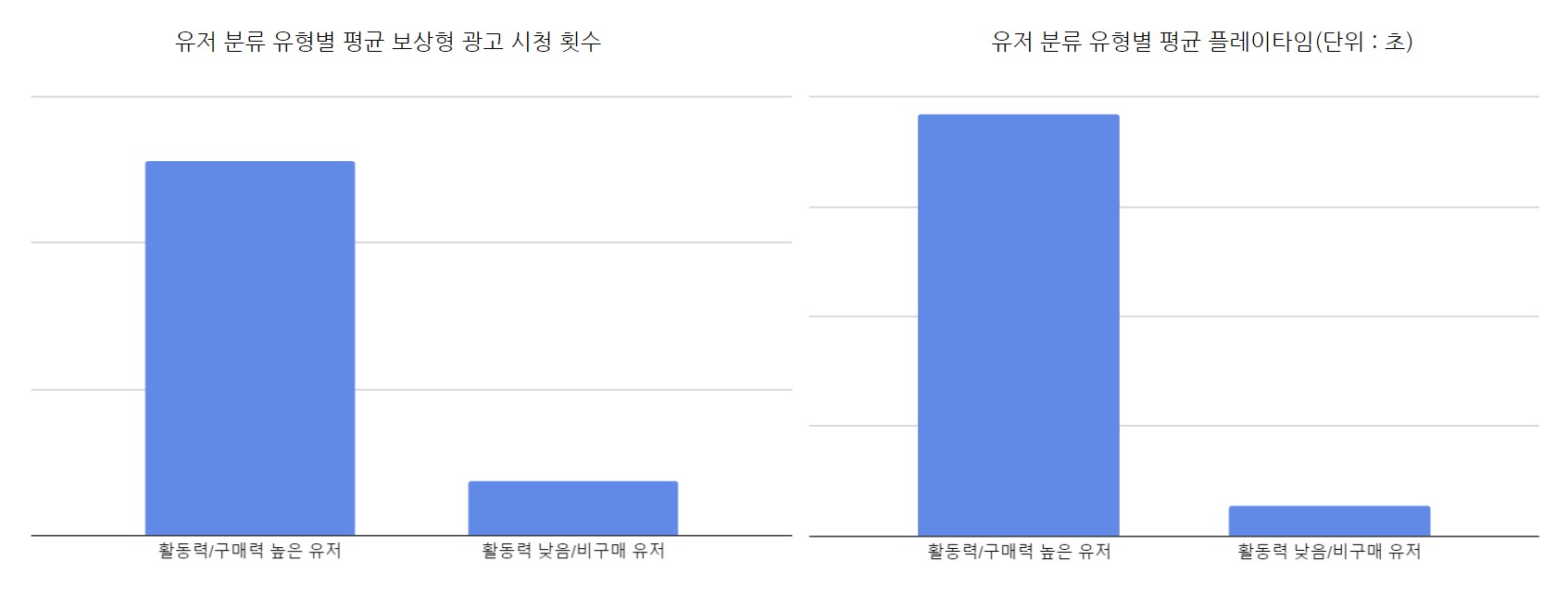
아래 그래프를 통해 활동력/구매력 높은 유저로 분류된 유저 중 대다수의 유저가 28일 이상 접속한 것을 확인할 수 있다. 반면, 오른쪽 그래프를 통해 활동력 낮음/비구매 유저 유형으로 분류된 유저 중 대다수의 유저가 이후 하루도 접속하지 않고 이탈한 것을 확인할 수 있다.
접속 일 수별 유저 비율(x축 접속 일 수, y축 비율(%))
평균 플레이타임, 평균 보상형 광고 시청 횟수 분석
활동력/구매력 높은 유저가 활동력 낮음/비구매 유저에 비해 평균 보상형 시청 횟수, 평균 플레이타임이 높았다.
평균 플레이타임, 평균 보상형 광고 시청 횟수 분석
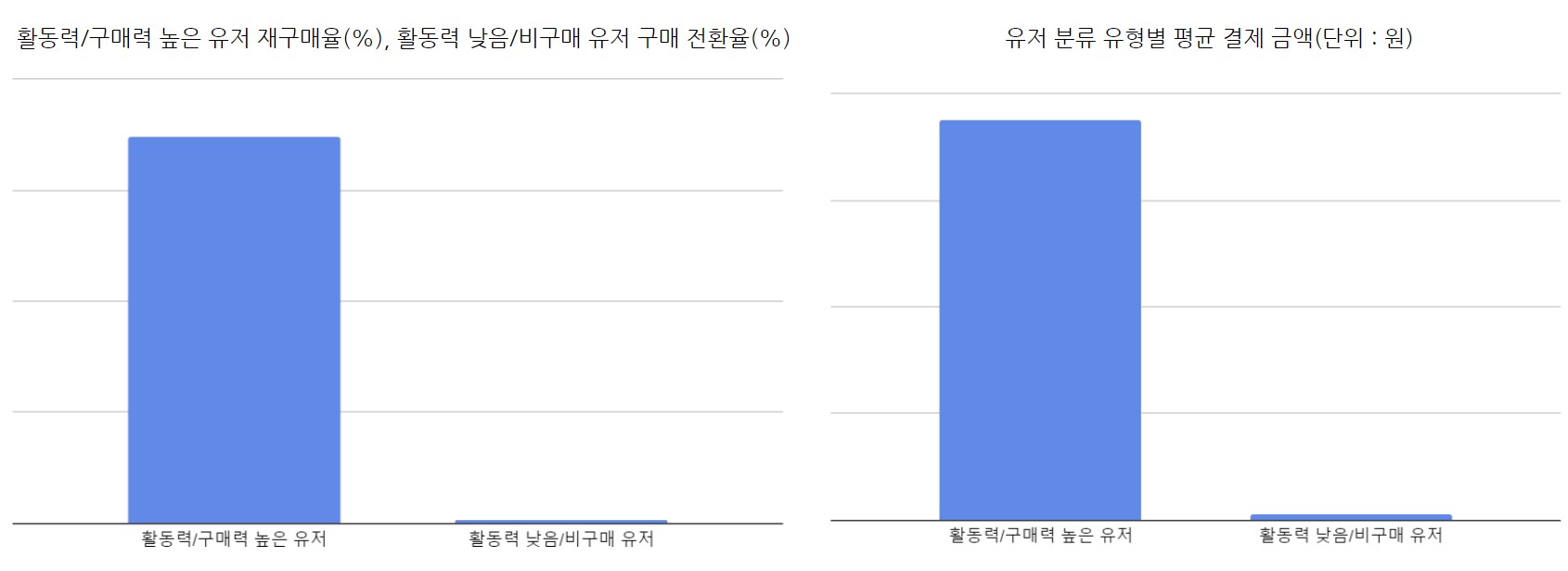
재구매율(%) / 구매 전환율(%) 및 평균 결제 금액(단위 : 원) 분석
아래 그래프를 보면 활동력/구매력 높은 유저 중 대다수가 이후 30일간 재구매한 반면, 활동력 낮음/비구매 유저 중 대다수는 구매 유저로 전환되지 않았다. 각 분류 유형별 구매 유저를 대상으로 1인 당 평균 결제 금액(ARPPU, Average Revenue Per Paying User) 지표를 살펴본 결과, 활동력/구매력 높은 유저 유형이 활동력 낮음/비구매 유저 유형에 비해 높은 지표 수치를 보였다.
재구매율(%) / 구매전환율(%) 및 평균 결제 금액(단위 : 원) 분석
결론
특정 게임 유저를 대상으로 모델을 학습하여 분류하고, 분류된 유저를 대상으로 이후 게임 내 활동 및 구매 관련 지표를 분석한 결과, 분류 결과에 대한 트렌드를 유지하는 것을 확인했다. 이후 유저 분류 모델을 활용하여 서비스화 가능한지에 대한 검증 단계가 필요했기에 여러 차례 실험을 반복한 결과, 본 글에서 소개한 내용과 유사하게 분류 결과에 대한 트렌드를 유지하는 것을 확인하여 서비스화를 결정했다.
실험 단계에서 유저 분류에 대한 가능성을 확인했으니 다음은 모델 학습과 서빙을 자동화하고, 서비스화할 단계다. Hive 애널리틱스는 기존에 머신러닝 제품을 구성할 때 MLOps의 개념을 지향하고 있었기에 유저 분류 모델 역시 MLOps의 개념을 지향하여 설계했다.
MLOps란?
MLOps는 기계 학습(ML, Machine Learning)에 DevOps을 적용한 개념이다. MLOps의 구성 요소는 지속적 통합(CI, Continuous Integration), 지속적 배포(CD, Continuous Delivery), 지속적 학습(CT, Continuous Training)이며, 세부 개념은 다음과 같다.
개념
내용
지속적 통합 (CI, Continuous Integration)
코드 및 구성 요소만을 테스트하고 검증하는 것뿐 아니라 데이터, 데이터 스키마, 모델 또한 테스트하고 검증
지속적 배포 (CD, Continuous Delivery)
소프트웨어 패키지 또는 서비스의 배포 뿐 아니라 예측 서비스를 자동으로 배포하는 파이프라인을 포함
지속적 학습 (CT, Continuous Training)
모델을 주기적으로 자동으로 재학습하여 학습 모델의 품질을 유지하며 서비스를 제공
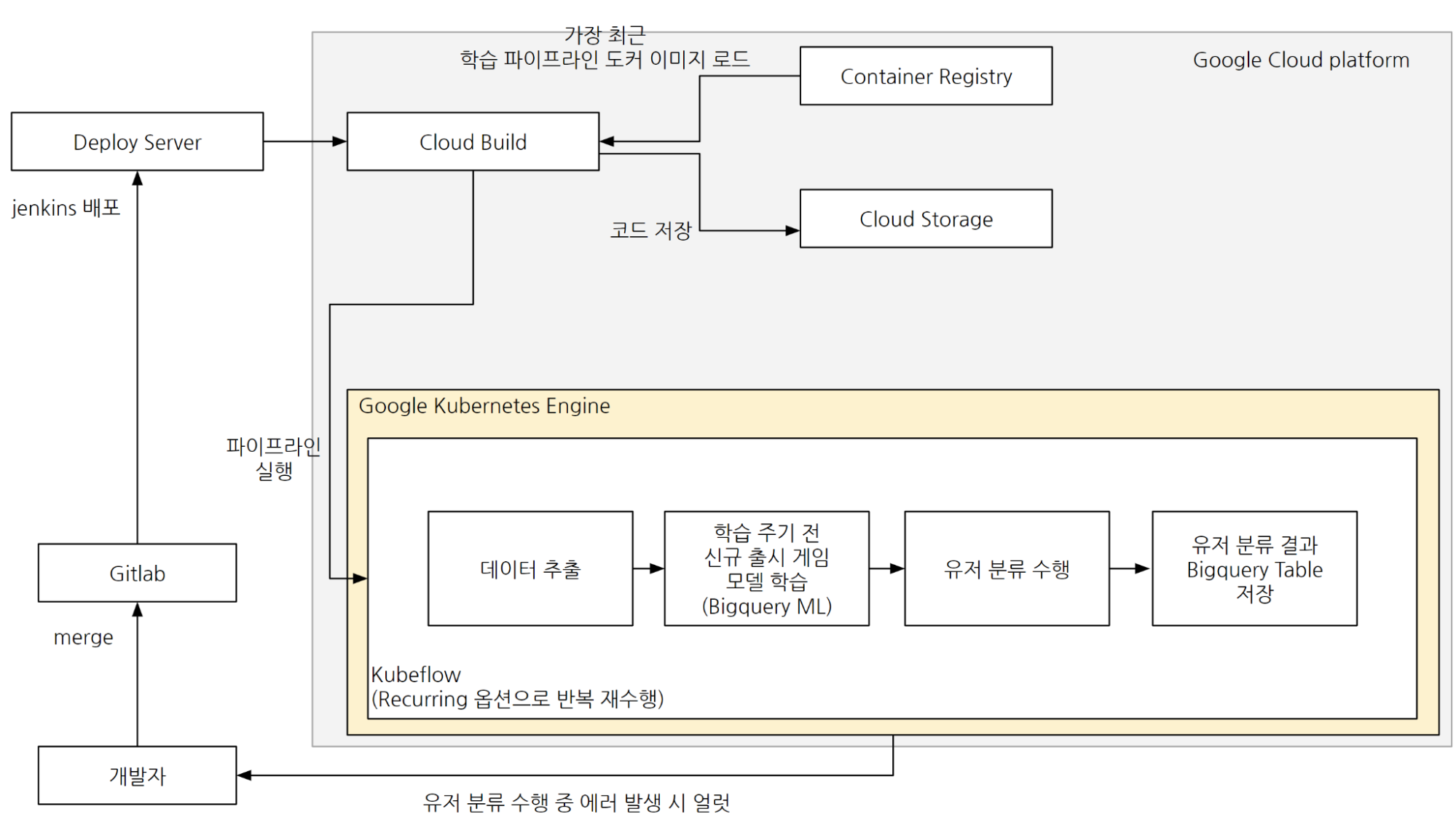
유저 분류 파이프라인 구성 현황
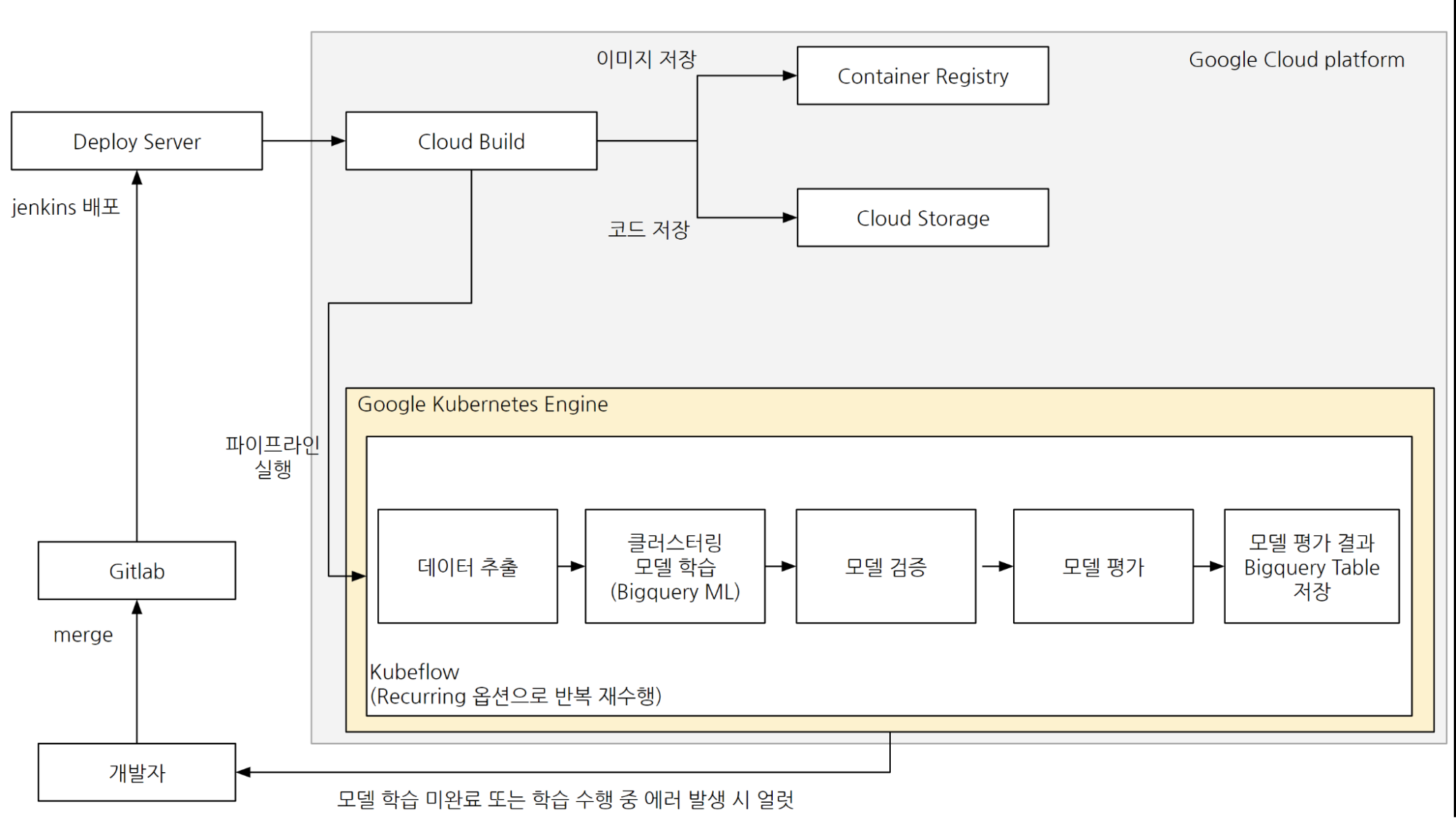
앞서 언급한 부분과 같이 Hive 애널리틱스의 유저 분류 모델은 MLOps의 개념을 지향하여 설계되어 운영되고 있다. 지속적 통합 / 지속적 배포 항목은 Gitlab과 jenkins를 통해, 지속적 학습 항목은 학습 파이프라인의 스케줄링을 통한 주기적 모델 학습을 통해 이루어지고 있으며, 안정적인 모델 서빙을 위해 학습과 서빙 파이프라인을 분리하여 운영하고 있다.
스케줄 주기: 최신 데이터를 기반으로 학습하여 모델의 품질을 유지하기 위해 주 1회 유저 분류 모델을 학습한다.
학습 파이프라인 구조
유저 분류 모델 학습 파이프라인 구조
파이프라인 배포
개발자는 파이프라인 구성을 위한 코드를 개발하고, GitLab에 개발 소스를 통합한다.
통합된 소스는 jenkins를 통하여 배포되고, 배포된 소스는 Google Cloud Build를 통해 Kubernetes 기반 프레임 워크인 Kubeflow 환경에서 실행 가능한 형태로 빌드된다.
유저 분류 모델 학습 단계 요약
데이터 추출: Google Bigquery에 저장된 대용량 데이터를 추출하여 유저 분류 모델 학습을 위한 모수 데이터를 구성한다.
클러스터링 모델 학습: Google의 BigqueryML 기능을 활용하여 K-means 클러스터링 모델을 활동력 모델과 구매력 모델을 각각 학습한다.
모델 검증: 학습된 모델에 대한 검증을 수행한다. 이 과정에서 모델 학습이 정상적으로 이루어지지 않은 경우 자동으로 개발자에게 모니터링 알림이 전송된다.
모델 평가: 학습된 모델에 대한 평가를 데이비스-볼딘 지수, 평균 제곱 거리(Mean Squared Distance) 및 각 클러스터별 반지름 수치를 기반으로 수행한다.
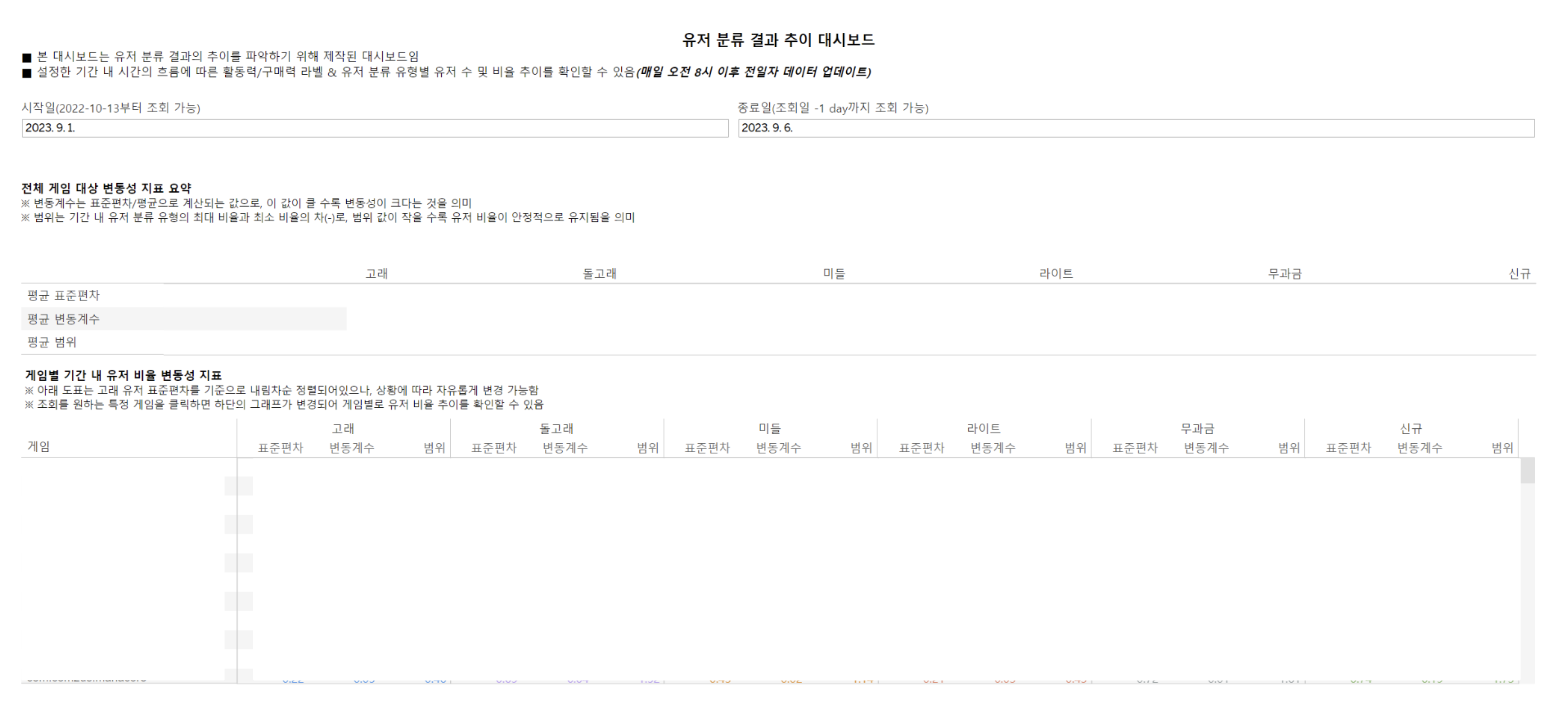
모델 평가 결과 Bigquery Table 저장: 모델 평가 결과를 Bigquery Table에 저장한다. 이 단계에서 저장되는 데이터를 기반으로 태블로 대시보드를 구축하여 모델 학습에 대한 추이 모니터링을 진행하고 있다.
모델 학습 추이 모니터링 대시보드 중 일부
스케줄 주기: 어제 자 DAU 대상으로 일 1회 분류를 수행한다. 분류 결과는 오전 시간대에 확인할 수 있다.
서빙 파이프라인 구조
유저 분류 서빙 파이프라인 구조
파이프라인 배포: 학습 파이프라인 배포와 동일한 방법으로 GitLab과 jenkins를 활용하여 배포된다.
유저 분류 모델 서빙 단계 요약
데이터 추출: Google Bigquery에 저장된 데이터를 기반으로 유저 분류를 위한 모수 데이터를 추출한다.
학습 주기 전 신규 출시 게임 모델 학습: 매주 1회 학습 주기가 도래하기 전 출시된 새로운 게임은 학습 모델이 없기 때문에 신규 게임에 대한 학습을 수행한다.
유저 분류 수행: 데이터 추출 단계에서 추출된 유저 대상 학습된 활동력, 구매력 모델을 활용하여 분류를 진행한다. 유저의 최종 분류 유형은 활동력 분류 결과와 구매력 분류 결과를 기반으로 결정된다.
유저 분류 결과 Bigquery Table 저장: 유저 분류 결과를 지표로 가시화하기 위해 Bigquery Table로 저장한다. 이 단계에서 저장되는 데이터를 기반으로 태블로 대시보드를 구축하여 유저 분류에 대한 추이 모니터링을 진행하고 있다.
유저 분류 추이 모니터링 대시보드 중 일부
이렇게 만들어진 유저 분류 현황에 대한 데이터는 Hive 애널리틱스의 게임별 지표, 세그먼트 메뉴를 통해 활용할 수 있다. 게임별 지표의 유저 분류 지표(애널리틱스 – 게임별 지표 – 이용자 – 유저 분류)를 통하여 유저 분류 유형별 유저의 특성을, 유저 분류 이동 지표(애널리틱스 – 게임별 지표 – 이용자 – 유저 분류 이동)를 통하여 시간의 흐름에 따른 유저 분류 유형의 이동을 확인할 수 있다. 또, 원하는 경우 특정 분류 유형의 유저들을 세그먼트로 생성하여 유저 목록을 추출하고, 해당 유저 군을 대상으로 타겟팅 할 수 있다.
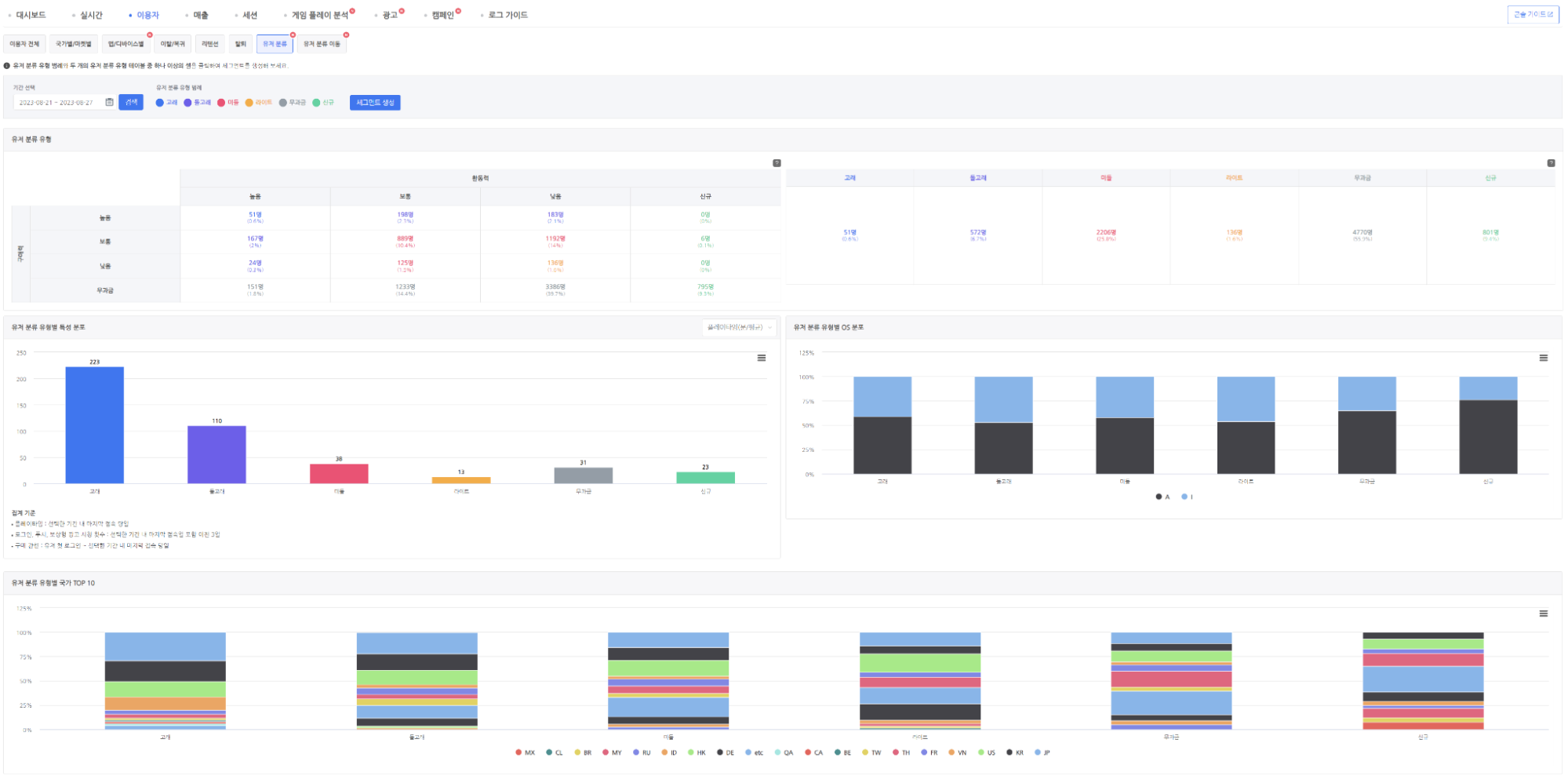
유저 분류 지표
지표 조회를 위해 선택한 기간 내 1회 이상 접속한 유저의 가장 마지막 분류 유형을 기준으로 다음과 같은 지표를 확인할 수 있다. 지표 내 표의 셀을 선택하면 선택한 유저 군에 대한 타겟팅도 가능하니, 원하는 분류 유형의 유저들을 타겟팅하여 세분화된 마케팅 활동을 전개해 보자. (유저 분류 지표에 대한 자세한 내용은 유저 분류 지표 가이드 문서에서 확인할 수 있다.)
활동력/구매력 라벨별 유저 현황: 활동력, 구매력별 유저 수와 비율을 확인할 수 있다.
유저 분류 유형별 유저 현황: 활동력, 구매력 조합으로 아래와 같이 정의된 유저 분류 유형별 유저 수와 비율을 확인할 수 있다.
고래 : 활동력, 구매력 모두 높음인 경우
돌고래 : 활동력, 구매력 중 하나라도 높음인 경우
미들 : 활동력, 구매력 중 하나라도 보통인 경우
라이트 : 활동력, 구매력 중 하나라도 낮음인 경우
무과금 : 활동력에 관계 없이 무과금 유저인 경우
신규 : 구매력에 관계 없이 신규 유저인 경우
유저 분류 유형별 특성 분포: 각 유저 분류 유형별 다음 특성 데이터를 확인할 수 있다.
플레이 타임(분/평균)
로그인 일수(평균)
로그인 횟수(평균)
일 평균 로그인 횟수
푸시 반응률(평균)
보상형 광고 시청 수(평균)
첫 구매까지 소요일(평균)
누적 과금액
유저 1인당 과금액
유저 분류 유형별 OS 분포: 각 유저 분류 유형별 OS 분포를 확인할 수 있다.
유저 분류 유형별 국가 TOP 10: 각 유저 분류 유형별 상위 10개국을 대상으로 국가 분포를 확인할 수 있다.
유저 분류 지표
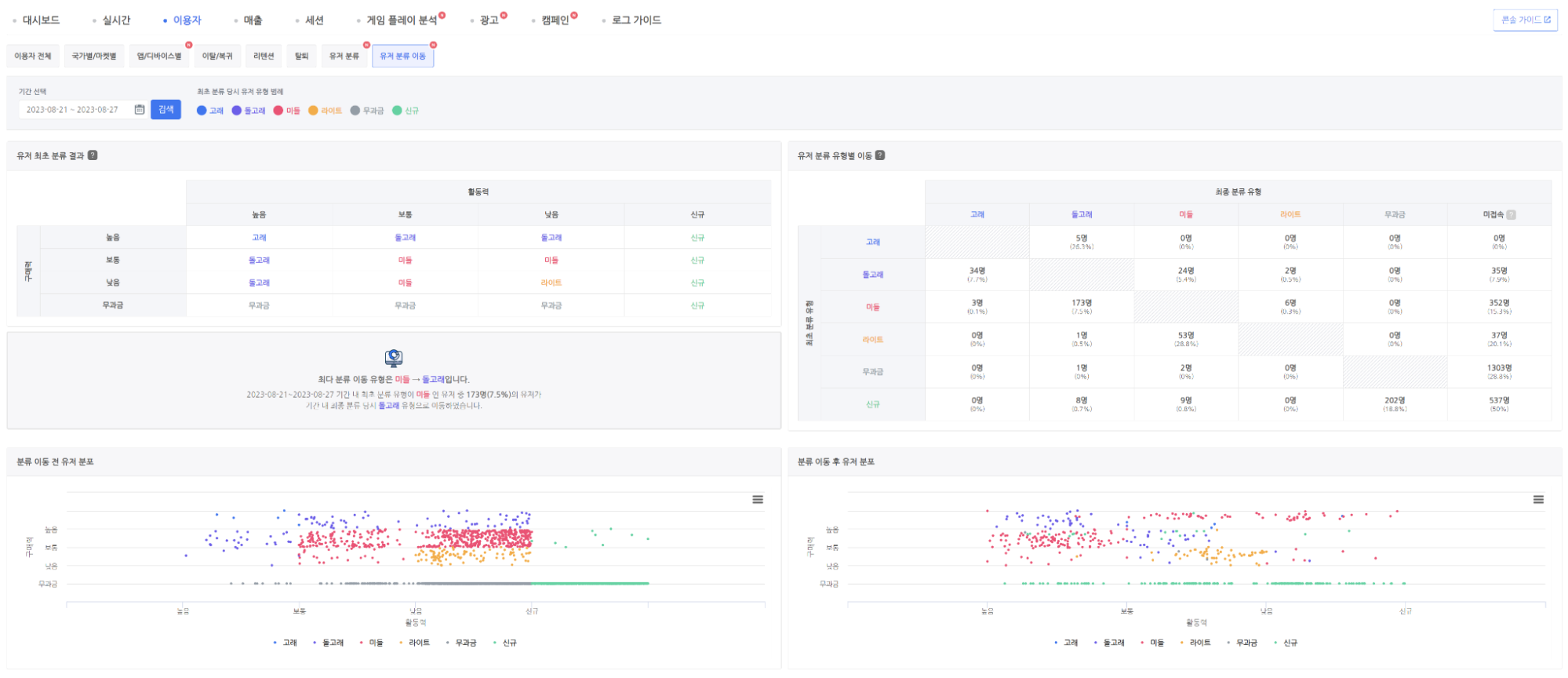
유저 분류 이동 지표
지표 조회를 위해 선택한 기간 내 1회 이상 접속한 유저의 첫 번째 분류 유형과 마지막 분류 유형을 비교하여 두 유형 간 변동이 발생한 유저를 대상으로 지표를 확인할 수 있다. 유저 분류 이동 현황을 표와 그래프의 형태로 확인할 수 있으니, 게임 내 이벤트, 업데이트, 프로모션 등의 효과를 측정하는 데 활용해보자. (유저 분류 이동 지표에 대한 자세한 내용은 유저 분류 이동 지표 가이드 문서에서 확인할 수 있다.)
유저 최초 분류 결과: 활동력, 구매력의 조합으로 아래와 같이 정의된 유저 분류 유형의 정의를 확인할 수 있다.
고래: 활동력, 구매력 모두 높음인 경우
돌고래: 활동력, 구매력 중 하나라도 높음인 경우
미들: 활동력, 구매력 중 하나라도 보통인 경우
라이트: 활동력, 구매력 중 하나라도 낮음인 경우
무과금: 활동력에 관계 없이 무과금 유저인 경우
신규: 구매력에 관계 없이 신규 유저인 경우
유저 분류 유형별 이동: 기간 내 첫 접속일과 마지막 접속일의 분류 유형이 다른 유저를 대상으로 최초 분류 유형에서 최종 분류 유형으로의 이동한 유저 수와 비율 현황을 확인할 수 있다.
최다 분류 유형 이동 현황: 유저 분류 유형별 이동 테이블에서 유저 수를 기준으로 분류 이동이 가장 많이 일어난 현황을 한 눈에 확인할 수 있다.
분류 이동 전 유저 분포 & 분류 이동 후 유저 분포: 색상으로 구분된 점 이동 맵을 통해 각 유저 기준 최초 분류 결과에서 최종 분류 유형으로의 이동 현황을 확인할 수 있다.
유저 분류 이동 지표
세그먼트
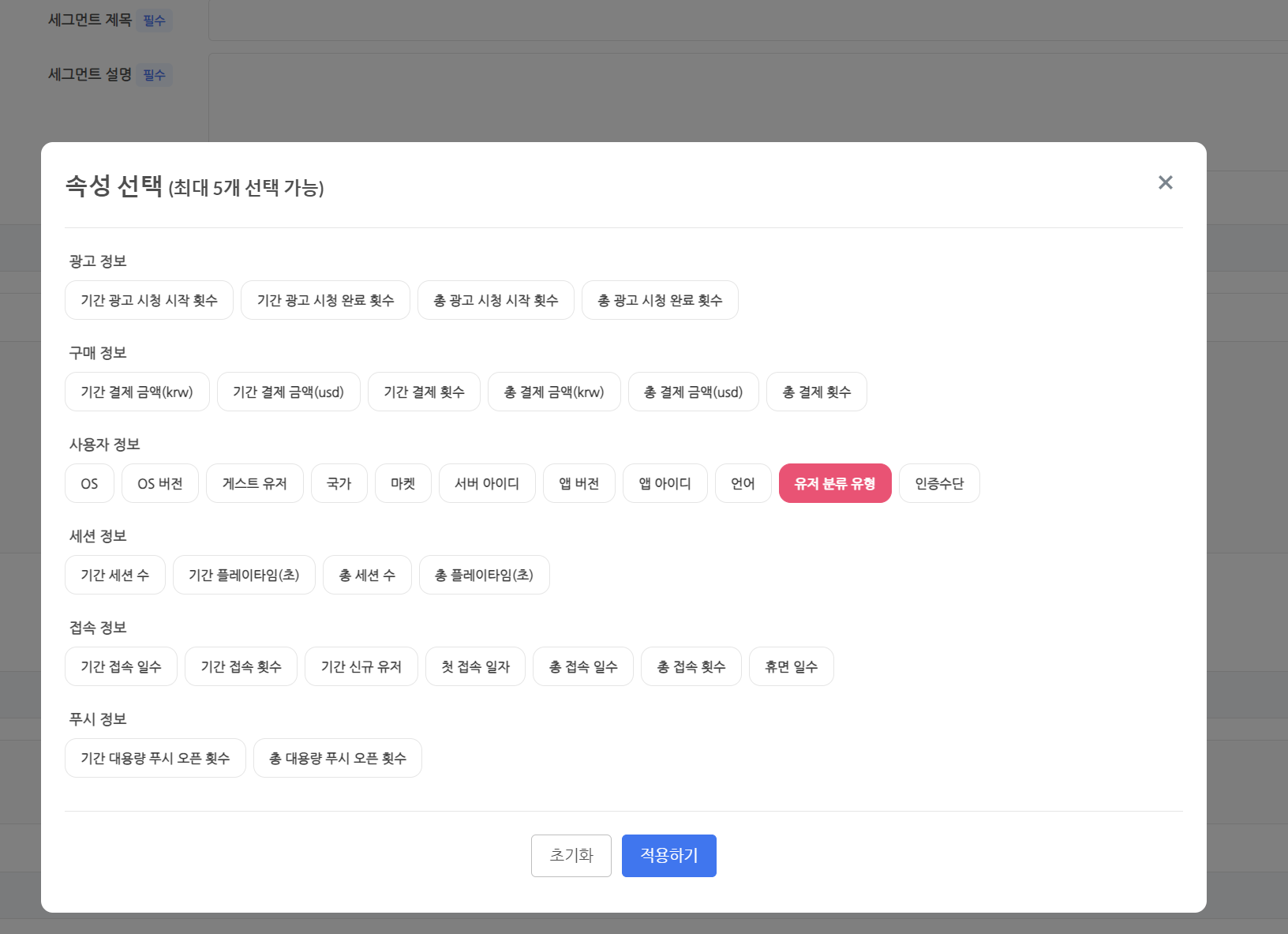
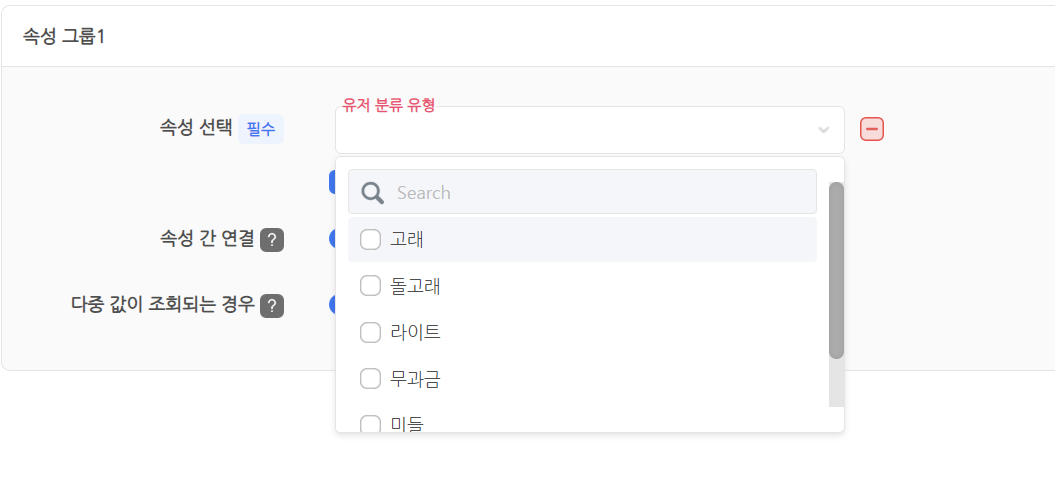
세그먼트는 특정 조건에 따라 유저를 세분화하여 그룹화하는 기능이다. Hive 애널리틱스 세그먼트는 유저 분류 유형 속성을 포함하여 최대 38가지 이상의 속성을 기본으로 제공하고 있으며, 원하는 경우 게임에서 직접 커스텀한 속성을 전송하면 세그먼트 생성에 활용할 수 있다. (세그먼트에 대한 자세한 내용은 세그먼트 가이드 문서에서 확인할 수 있다.)
세그먼트 생성 시 유저 분류 유형 속성 이름 선택 화면세그먼트 생성 시 유저 분류 유형 속성 값 목록 선택 화면
지금까지 Hive 애널리틱스에서 유저 분류 지표를 어떻게 연구했고, 운영되고 있는지 알아봤다. Hive 애널리틱스의 유저 분류 기능은 게임별 커스텀한 데이터를 반영하지 않는다는 한계가 있을 수 있지만, 게임에서 많은 리소스를 투입하지 않고도 머신러닝 결과를 바로 확인할 수 있다는 점에서 큰 의의가 있다고 생각한다. 유저 분류 기능이 게임 마케팅에 대한 합리적 의사결정에 기여할 수 있기를 바라며 이 글을 마친다.
Hive 애널리틱스는 유저 분류 지표 이외에도 게임 운영에 필요한 주요 데이터를 지표로 제공하고 있다. 또, 원본 데이터를 애널리틱스 빅쿼리 기능을 통해 조회하고 다운로드할 수 있으며, 세그먼트를 통해 다양한 조건을 조합하여 유저를 세분화할 수 있고, 리텐션 분석을 통해 국가별, 서버별, 마켓별 다양한 조건의 리텐션 수치를 확인할 수 있다. Hive 애널리틱스에 대한 자세한 소개와 사용 방법은Hive 개발자 사이트에서 확인 바란다.
Tip! Hive 콘솔 가입 후 데모 기능을 활용하여 Hive 애널리틱스의 기본 제공 지표를 자세히 확인할 수 있으니 참고해보자.
Tip! Hive 애널리틱스 사용에 대한 문의 사항이 있는 경우 아래 메일로 문의해보자. ◆ 컴투스플랫폼 데이터기술팀: DT@com2us.com
엄영민 데이터 분석가
애널리틱스의 유저 분류 기능을 소개할 수 있게 되어 영광입니다. 유저 분류 기능 연구 과정을 함께 고민해주신 모두에게 감사드린다는 말씀을 전하고 싶습니다. 데이터기술팀에서는 유저 분류 기능을 비롯한 게임 운영에 필요한 다양한 지표와 기능을 연구하여 제공하고 있습니다. 애널리틱스는 Hive 콘솔 가입을 통해 만나볼 수 있으니, 앞으로도 많은 관심 부탁드립니다.