“캐릭터 직업 변경 이벤트 전/후 매출 변화는 얼마인가요?”, “이번 시즌 출석 이벤트가 이탈 유저 복귀에 효과가 있었나요?”, “이번 프로모션 이후 유저가 늘긴 했는데, 어떤 채널에서 유입된 신규 유저의 리텐션이 가장 높은가요?”
오랫동안 사랑받는 게임을 만들고 싶다면 한 번쯤 마주치는 질문들이다. 한정된 리소스 안에서 마케팅 예산을 배분하고, 차기 프로모션을 기획하고, 운영 방향을 결정하기 위해 데이터 분석은 선택이 아닌 필수다. Hive에서는 이러한 마케팅 의사결정을 돕기 위해 애널리틱스 제품을 제공하고 있다.
기존 애널리틱스는 게임별 지표, 종합 지표, 세그먼트, 지표 생성, 대시보드, 로그 정의 등 다양한 기능으로 데이터 분석 환경을 지원해왔다. 수 년간 서비스를 운영하면서 실제 사용자들이 겪는 어려움을 분석했고, 공통된 불편 사항을 바탕으로 새로운 버전의 애널리틱스를 구축했다. 이 글에서는 새로운 버전의 애널리틱스가 어떤 문제를 해결하고자 했는지 살펴본다.
SQL 없이 데이터를 분석해보세요.
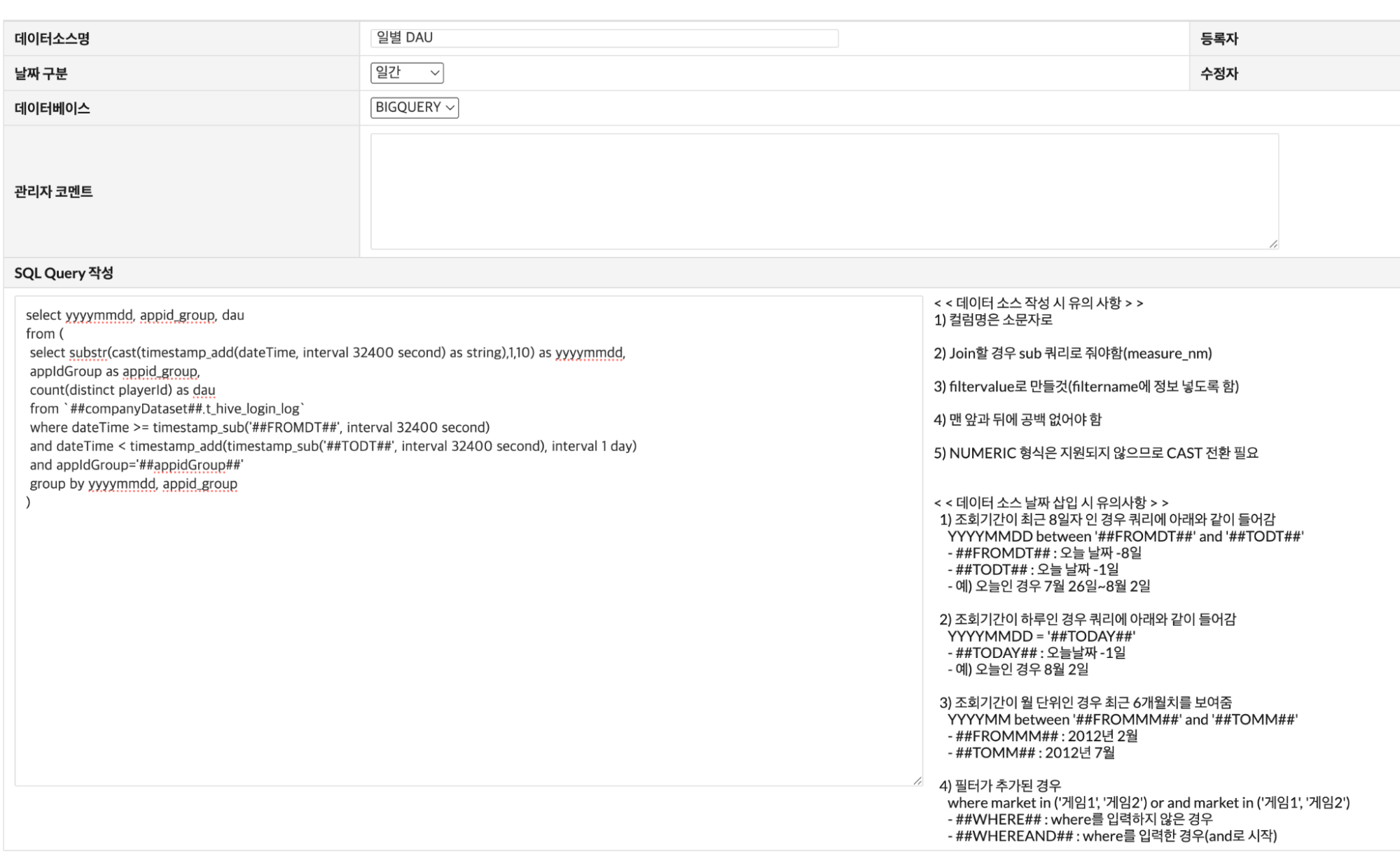
기존 애널리틱스는 게임별 지표, 종합 지표 메뉴를 통해 100가지 이상의 지표 페이지를 기본으로 제공했고, 현업에서 직접 원하는 지표를 만들 수 있는 커스텀 지표 기능도 지원했다. 다만 이 기능을 쓰려면 BigQuery 기준의 SQL 작성이 반드시 필요했고, 사전에 정의된 규격에 맞는 형식으로 쿼리를 짜야 했다. SQL에 익숙한 개발·BI(Business Intelligence) 직군에게는 유연한 분석이 가능한 강력한 도구였지만, SQL을 잘 모르는 사업·마케팅 직군에게는 분석이 필요할 때마다 개발팀의 개입을 기다려야 하는 구조였다. 빠른 의사결정이 필요한 순간에도 데이터를 보려면 개발팀의 일정을 기다려야 하는 상황이 반복됐다.
커스텀 지표 기능을 통한 DAU 지표 생성
새로운 버전의 애널리틱스는 분석 리드 타임을 줄이기 위해 UI 기반 지표 생성을 지원한다. 핵심은 메트릭과 차트의 개념 분리다. 메트릭은 “무엇을 셀지”를 정의하는 공통 지표 저장소이고, 차트는 “어떤 단위로 볼지”를 결정하는 시각화 도구다. 메트릭을 한 번 정의해두면 여러 차트에서 반복 설정 없이 재사용할 수 있고, 기준이 바뀌어도 메트릭 하나만 수정하면 연결된 모든 차트에 일괄 반영된다.
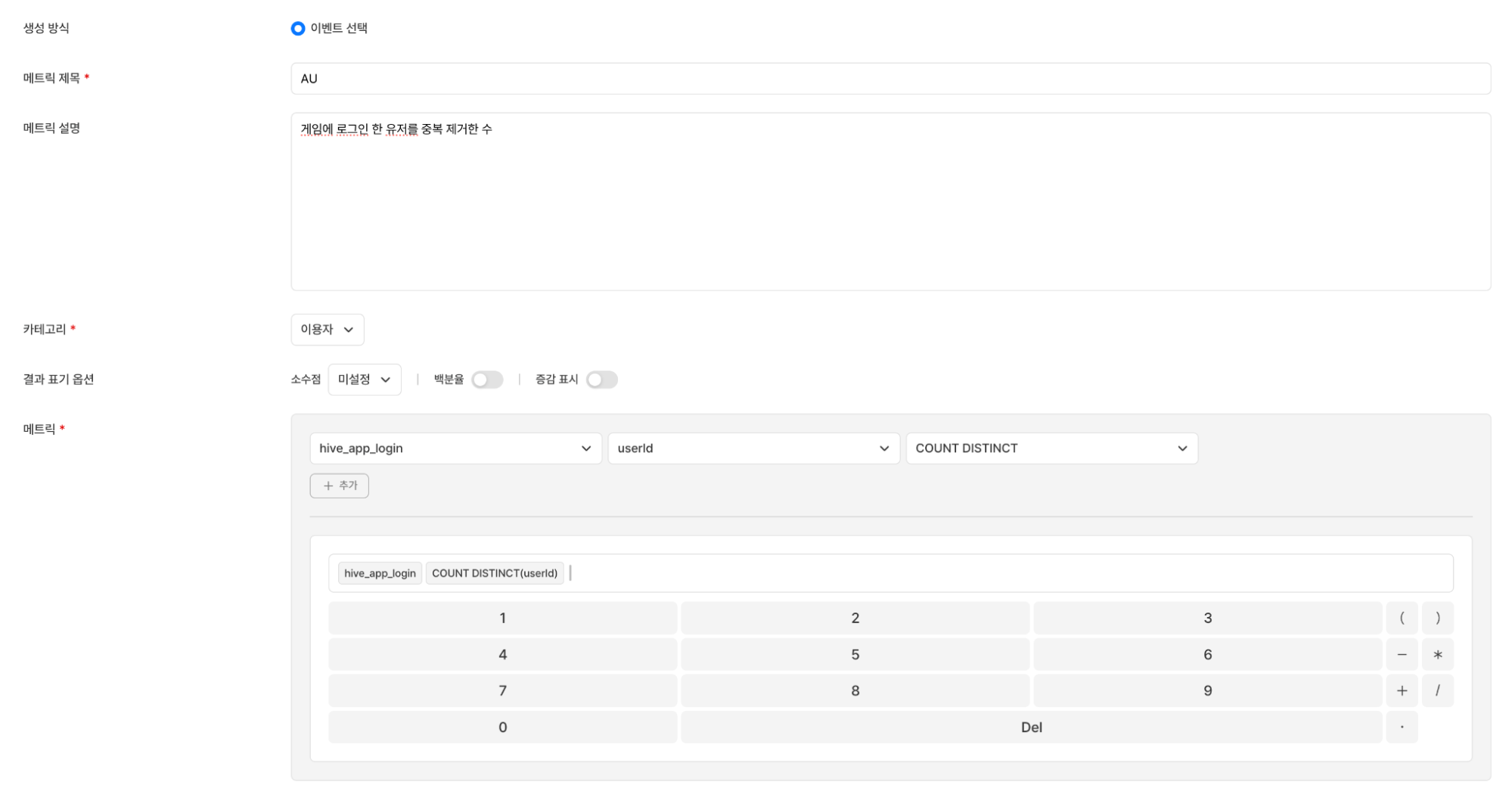
메트릭 생성은 세 가지 선택으로 완성된다. 분석하고 싶은 이벤트를 고르고, 집계에 사용할 속성을 선택하고, 집계 방식(합계, 평균, 최대 등)을 지정하면 된다. 예를 들어 AU를 메트릭으로 정의하고 싶다면 hive_app_login 이벤트 → userId 속성 → COUNT DISTINCT 집계 방식을 선택하면 된다. 두 이벤트의 집계 결과를 조합한 복합 수식도 지원한다. PU RATE(%)처럼 “결제 유저 수 / 로그인 유저 수 * 100” 같은 연산이 필요한 지표도 메트릭 하나에 저장할 수 있다.
이벤트, 속성, 집계 방식 선택으로 AU 메트릭 정의
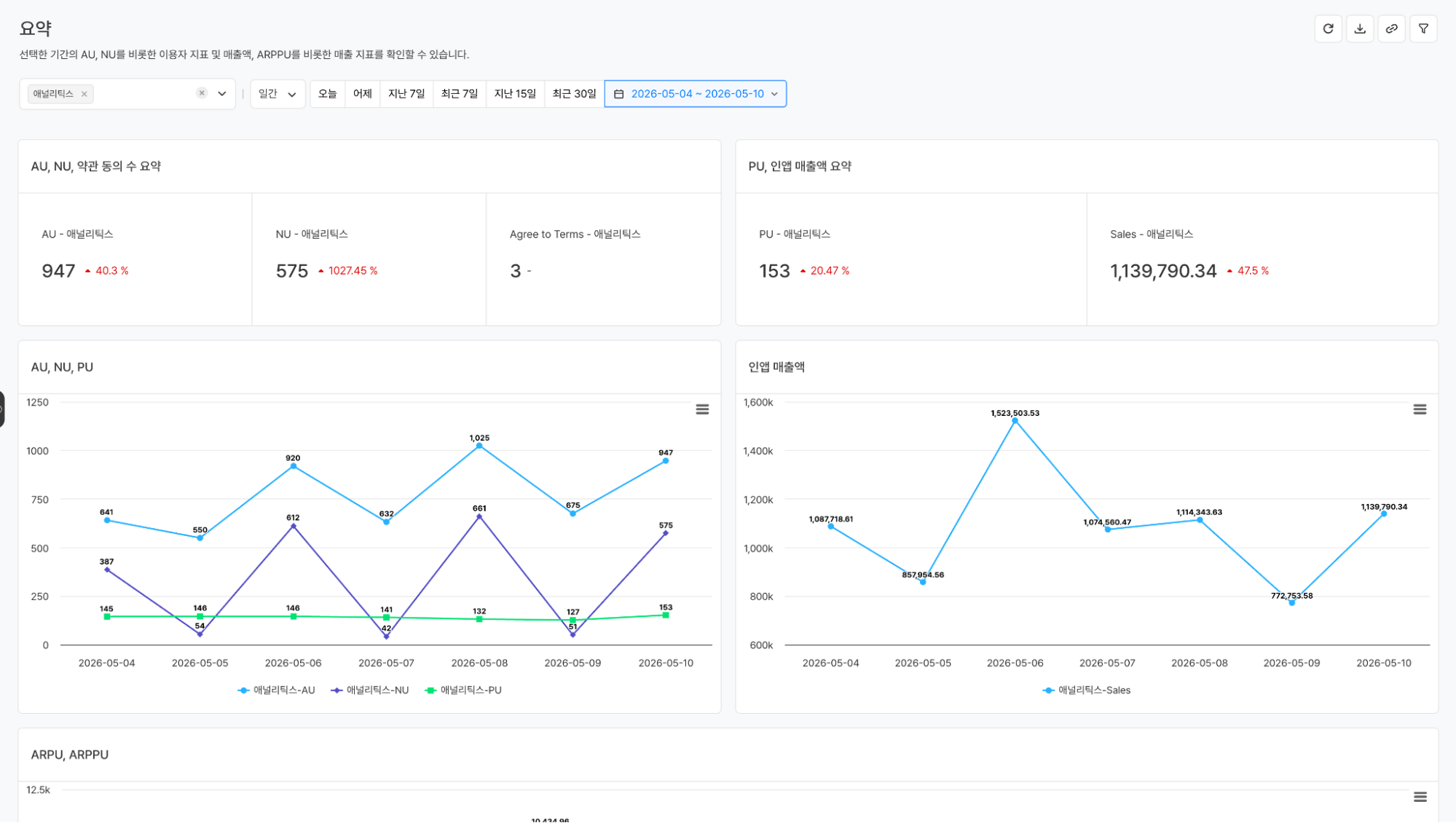
자주 쓰는 지표는 시스템이 기본으로 제공한다. AU, ARPU, ARPPU, PU, PU RATE(%), 인앱 매출액 등 게임 운영에 필수적인 지표들을 플랫폼 메트릭으로 내장해두었다. 접속하는 순간부터 SQL 한 줄 없이 핵심 KPI를 바로 조회할 수 있다.
플랫폼 메트릭을 활용한 기본 제공 대시보드
차트를 만들 때 반드시 메트릭을 먼저 정의할 필요는 없다. 차트 생성 화면에서 이벤트를 직접 선택하고 속성과 집계 방식을 그 자리에서 바로 설정할 수도 있다. “오늘 구매 유저가 몇 명인지” 한 번만 빠르게 확인하고 싶다면, 메트릭 등록 과정 없이 차트 화면에서 hive_product_purchase 이벤트 → userId → COUNT DISTINCT를 선택하면 된다. 메트릭의 진가는 같은 지표를 조직에서 반복해서 쓸 때 드러난다. AU 기준을 메트릭으로 한 번 정의해두면 이후 누가 차트를 만들든 동일한 계산 방식이 자동으로 적용된다. 정리하면, 이벤트 직접 선택은 빠른 임시 분석에, 메트릭은 팀 공통 KPI의 일관된 관리에 각각 최적화된 방식이다.
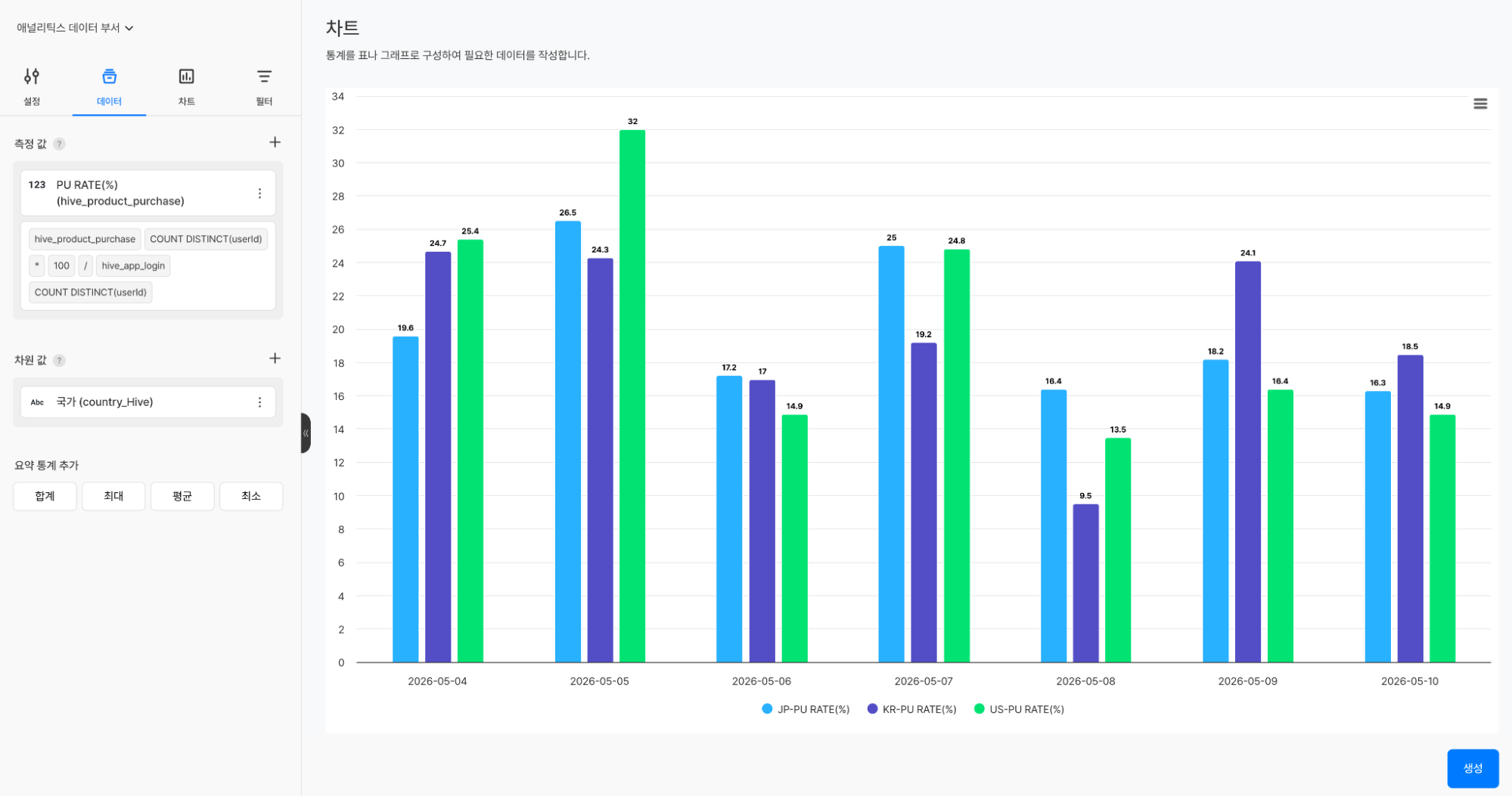
이벤트와 메트릭 중 어느 것을 선택하든 차트 구성 방식은 동일하다. 분석 대상 프로젝트와 기간 단위(일간/주간/월간 등)를 설정하고, 측정값을 추가한 뒤 국가·OS·마켓 같은 차원값을 더하면 “국가별 구매 전환율(%) 비교”나 “iOS vs Android AU 비교”처럼 조건별 분석이 즉시 완성된다. 완성된 차트는 라인, 바, 파이, 테이블, 스코어카드 등 목적에 맞는 시각화 유형으로 바로 전환할 수 있다.
국가별 구매 전환율(%) 비교 차트 구성
이로써 기존 애널리틱스에서 개발팀에 SQL 작성을 요청하고 며칠을 기다려야 했던 분석이, 새로운 버전의 애널리틱스에서는 사업·마케팅 담당자가 직접 수 분 안에 완료할 수 있게 됐다. “캐릭터 직업 변경 이벤트 전/후 매출 변화”가 궁금하다면 차트 화면에서 구매 이벤트를 선택하고 날짜 범위를 이벤트 전후로 맞추기만 하면 된다.
로그 정의 없이 커스텀 이벤트 데이터를 수집하세요.
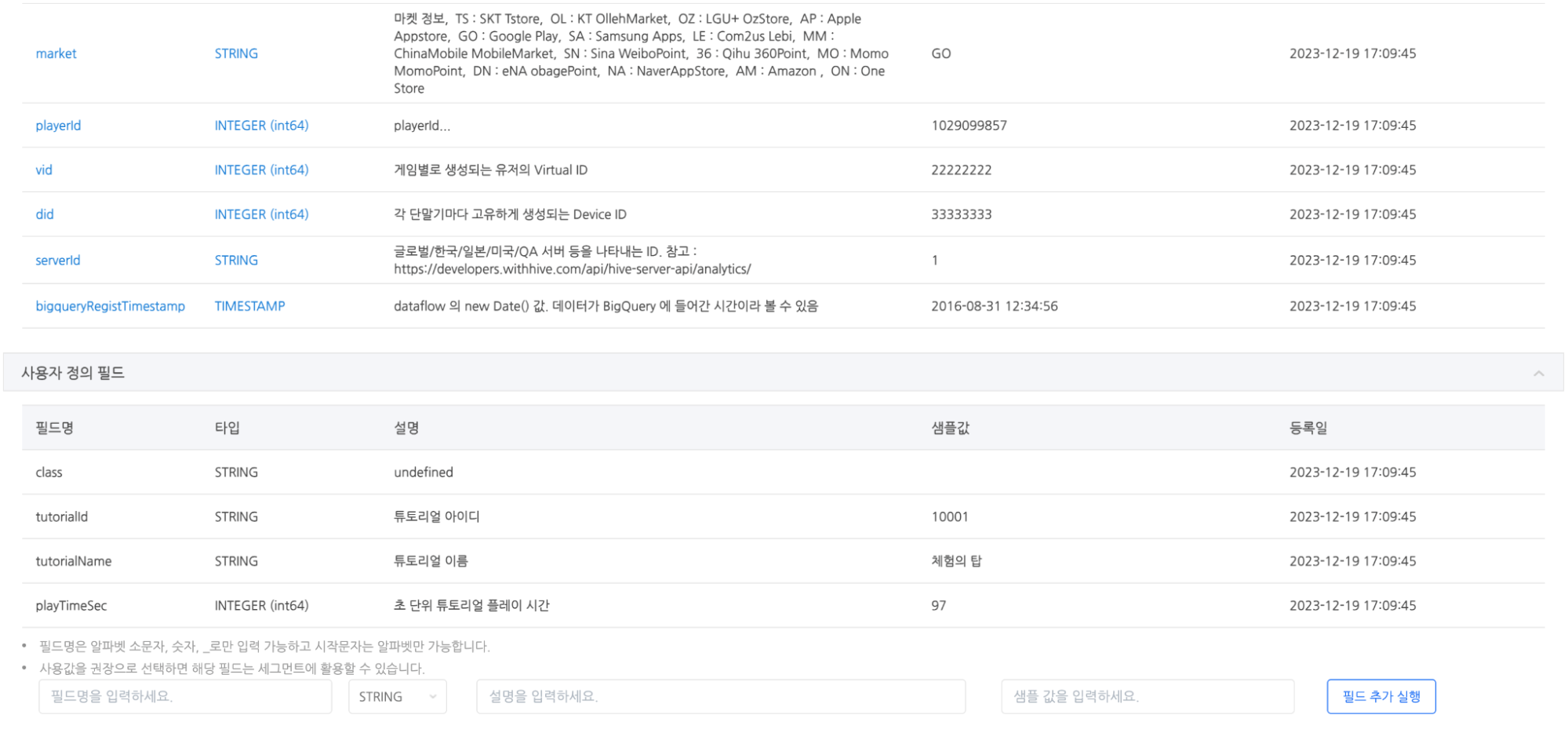
애널리틱스는 게임 SDK 연동만으로 인증, 빌링 등 게임에서 가장 중요한 로그를 기본으로 수집한다. 하지만 특정 던전의 클리어율, 캐릭터별 스킬 사용 패턴, 신규 보스 레이드 참여율처럼 게임마다 고유한 콘텐츠 지표를 수집하려면 반드시 ‘로그 정의’ 과정이 필요했다. 로그 정의란 전송할 데이터의 형태를 코드 배포 이전에 미리 지정하는 것으로, 어떤 필드를 전송할지, 각 필드의 자료형은 무엇인지를 사전에 모두 확정해야 했다. 이 과정이 개발 일정에 포함돼야 했기 때문에, 분석가나 기획자가 “이 필드도 같이 쌓아야겠다”고 판단해도 즉각 반영할 수 없었다. 로그 정의 → 개발 → 배포라는 절차를 모두 거쳐야만 데이터가 쌓이기 시작했고, 개발자와 기획자 간의 소통 오류로 로그가 잘못 전송된 경우에는 코드 수정과 게임 앱 빌드 재배포가 필수적이었다.
로그 정의 기능을 통한 튜토리얼 성공 로그 정의 예시
ELT(Extract-Load-Transform) 전환
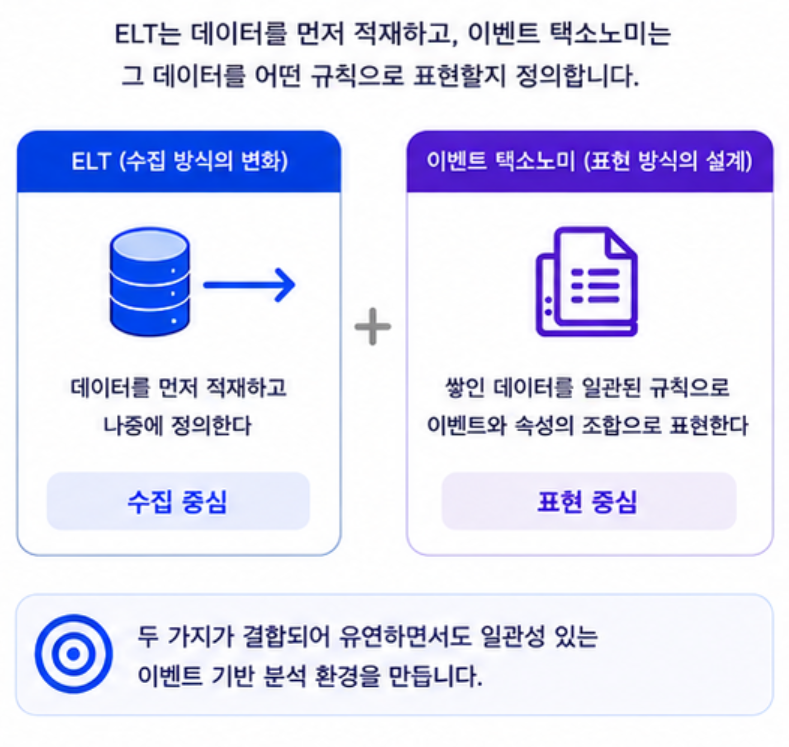
기존 애널리틱스의 로그 수집은 ETL(Extract-Transform-Load) 방식으로 동작했다. 데이터를 수집하기 전에 스키마를 먼저 Transform(변환·정의)해야 했고, 그 정의에 맞는 형태로만 Load(적재)하여 사용할 수 있었다. 수집된 데이터가 깔끔하게 정리된다는 장점이 있었지만, 스키마를 바꾸려면 반드시 코드 수정과 재배포가 따라왔다. 이 한계를 개선하고자 새로운 버전의 애널리틱스는 이벤트 택소노미 구조인 ELT 방식으로 전환했다. 이벤트 데이터를 원본 그대로 먼저 Load(적재)하고, 스키마 정의나 자료형 변환 같은 Transform 작업은 적재 이후 UI에서 처리한다. 데이터를 쌓는 시점과 구조를 정의하는 시점이 분리됐기 때문에, 사전 로그 정의 없이 이벤트를 자유롭게 전송할 수 있고 속성을 나중에 추가하거나 자료형을 변경해도 재배포가 필요 없다.
이벤트 택소노미
ELT 전환이 “데이터를 먼저 적재하고 나중에 정의한다”는 수집 방식의 변화라면, 이벤트 택소노미는 그렇게 쌓인 데이터를 어떤 규칙으로 표현할지에 대한 설계 체계다. 앱이나 게임에서 발생하는 유저 행동을 이벤트 단위로 정의하고 분류하는 방식으로, GA4 같은 대표적인 분석 도구에서도 널리 사용된다. 새로운 버전의 애널리틱스 역시 이 개념을 기반으로 데이터 수집 구조를 설계했다.
기존에는 게임마다 로그 테이블과 컬럼을 개별적으로 정의해야 했다. 새 게임이 추가될 때마다 스키마를 다시 설계하고 수집 파이프라인도 별도로 구성해야 했기 때문에 온보딩 비용이 크고, 게임 간 분석 기준을 맞추기도 쉽지 않았다. 이벤트 택소노미를 도입하면 로그를 이벤트 이름과 속성(Attribute)의 조합으로 일관되게 표현할 수 있어, 게임 스튜디오가 필요한 이벤트를 직접 설계하면서도 분석 체계는 공통으로 유지할 수 있다. 새로운 게임을 붙이는 비용은 줄고, 여러 게임을 아우르는 분석의 일관성도 확보된다.
ELT 전환과 이벤트 택소노미의 관계
이벤트와 속성
이벤트 택소노미에서 모든 로그는 이벤트 이름(event_name)과 속성(Attribute)의 조합으로 표현된다. 예를 들어 튜토리얼 완료 이벤트라면 event_name을 tutorial_success로 두고, 캐릭터 직업(class), 튜토리얼 ID(tutorialId), 튜토리얼 이름(tutorialName), 플레이 시간(playTimeSec) 같은 속성을 함께 전송한다. 어떤 게임이든 같은 틀로 이벤트를 기록하기 때문에, 게임마다 콘텐츠가 달라도 분석 시스템에서는 동일한 방식으로 수집하고 조회할 수 있다.
Hive Attribute와 Event Attribute
새로운 버전의 애널리틱스에서는 속성을 공통 속성과 게임별 속성으로 나눠 관리한다.
Hive Attribute는 Hive 플랫폼 차원에서 공통으로 관리하는 속성이다. 마켓, OS, 디바이스 정보처럼 게임 스튜디오가 별도로 정의하지 않아도 SDK 연동만으로 자동 수집된다. 게임 구분 없이 동일한 기준으로 활용할 수 있어, 국가별·OS별·마켓별 비교 같은 공통 분석을 어느 게임에서나 일관되게 수행할 수 있다.
Event Attribute는 게임 스튜디오가 자유롭게 정의하는 커스텀 속성이다. 특정 던전의 클리어 여부, 캐릭터 직업, 사용한 스킬 종류처럼 게임 고유의 콘텐츠 지표를 담는 영역으로, 게임 스튜디오가 필요한 파라미터를 직접 설계해 전송할 수 있다.
두 속성을 분리한 이유는 플랫폼 공통 정보와 게임별 커스텀 정보의 관리 경계를 명확히 하기 위해서다. 하나로 합치면 구조는 단순해 보일 수 있지만 역할이 뒤섞이기 쉽다. 분리하면 관리 포인트는 늘어나더라도, 플랫폼 차원의 일관성과 게임 스튜디오의 자유도를 동시에 확보할 수 있다.
데이터 파이프라인
게임 클라이언트에서 발생한 이벤트는 Hive SDK를 통해 전송되고, Fluentd를 거쳐 Google Cloud Pub/Sub으로 전달된다. Pub/Sub은 메시지 큐 역할을 하며, 대량의 로그가 동시에 유입되더라도 안정적으로 버퍼링한다. 이후 Google Cloud Dataflow가 Pub/Sub에 쌓인 데이터를 실시간으로 읽어와 BigQuery에 적재한다.
BigQuery 최적화
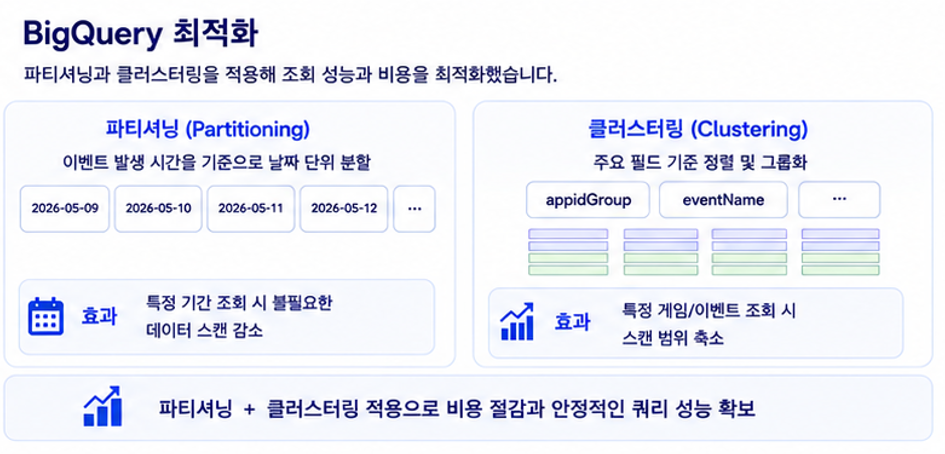
원본 이벤트 테이블은 여러 게임에서 발생하는 대량의 이벤트를 하나의 통합 테이블에 저장하는 구조다. 그만큼 조회 성능과 비용을 함께 최적화하는 것이 중요했고, 이를 위해 파티셔닝과 클러스터링 두 가지를 적용했다.
파티셔닝은 이벤트 발생 시간을 기준으로 적용했다. BigQuery의 Partition Time을 활용해 데이터를 날짜 단위로 분할함으로써, 특정 기간을 조회할 때 불필요한 데이터 스캔을 줄였다. 클러스터링 인덱스는 앱 정보와 이벤트 이름 등 주요 필드를 기준으로 설정했다. 대부분의 분석 쿼리가 특정 게임 스튜디오의 특정 게임을 대상으로 수행되기 때문에, 클러스터링만으로도 스캔 범위를 크게 줄일 수 있었다. 이 두 가지 최적화를 통해 전체 테이블 풀 스캔에 따른 비용과 지연을 방지하고, 실서비스에서 안정적인 쿼리 성능을 확보할 수 있었다.
BigQuery 파티셔닝·클러스터링 최적화 구조
흩어진 마케팅 데이터를 한 곳에서 분석하세요.
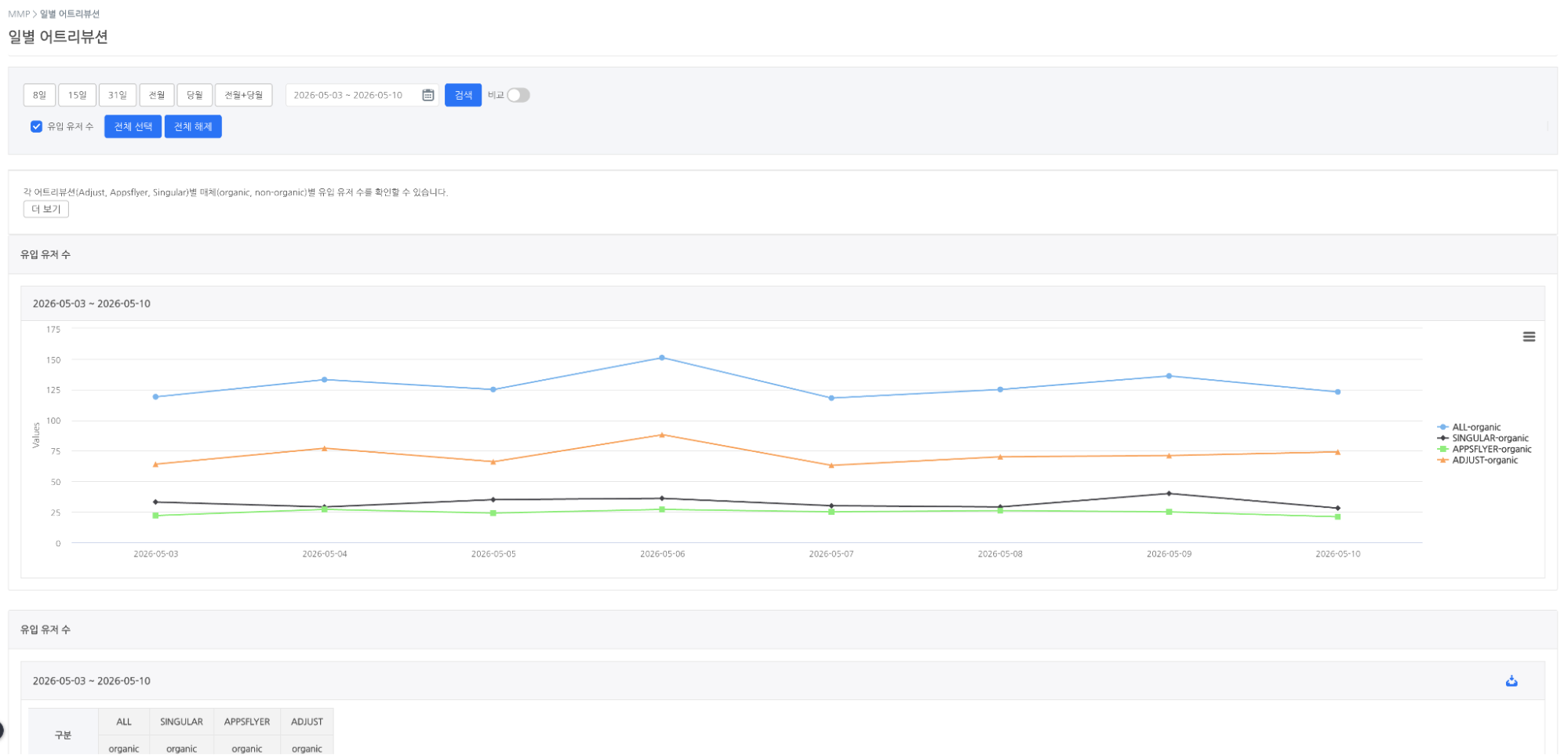
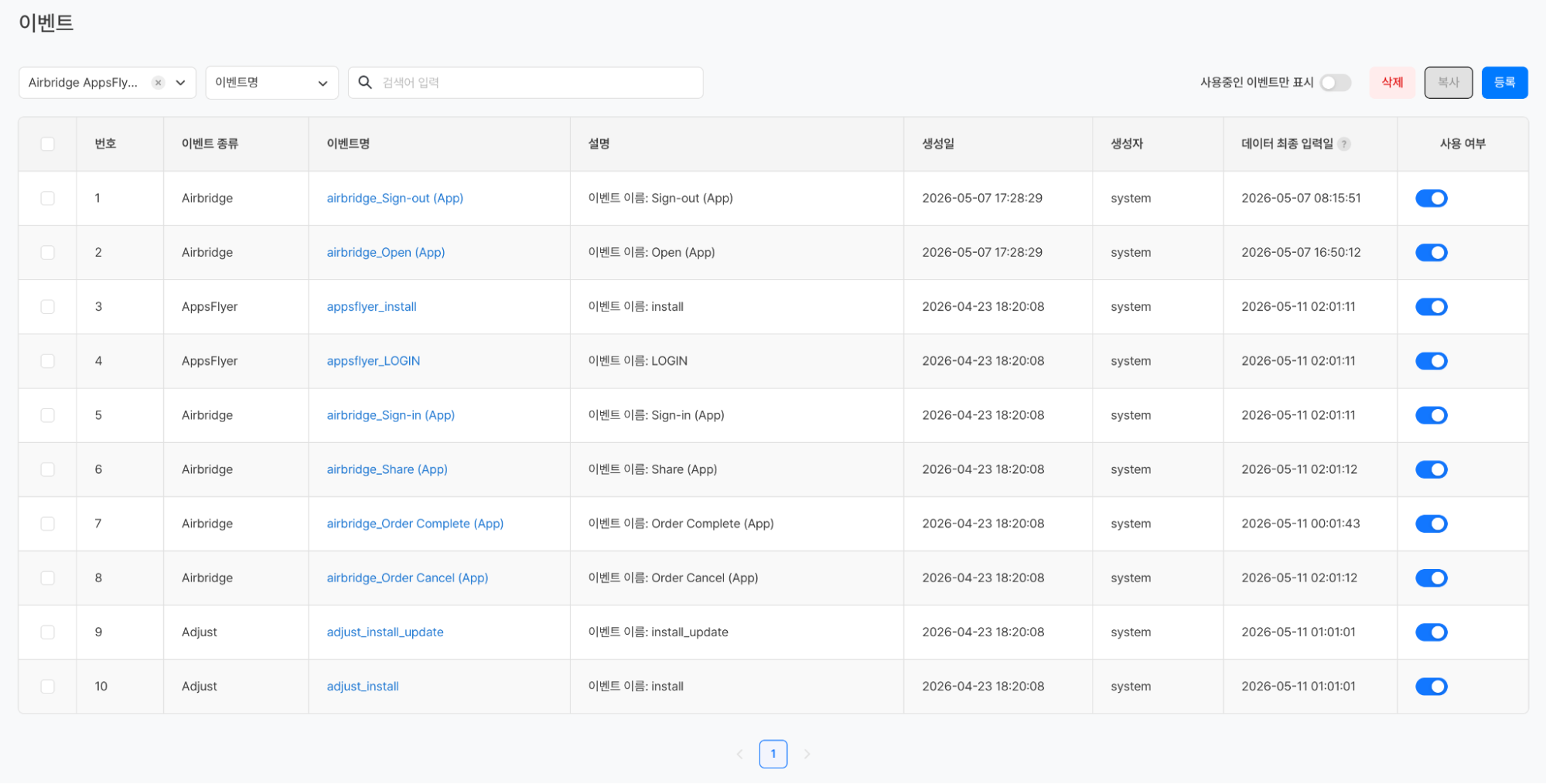
기존 애널리틱스도 MMP 데이터를 전혀 다루지 못했던 것은 아니다. Airbridge, AppsFlyer, Adjust 같은 MMP(Mobile Measurement Partner)와의 연동을 통해 채널별 설치 수 지표를 확인할 수 있었다. 다만 이 데이터는 사전에 정해진 지표 페이지 안에서만 볼 수 있었고, 게임 내 이벤트 데이터와 자유롭게 조합하는 것은 불가능했다. 유저의 유입 채널을 리텐션 차트의 차원으로 활용하거나, MMP와 인게임 데이터를 결합한 퍼널 구성은 지원하지 않았다.
게임별 지표 – MMP – 일별 어트리뷰션 지표 화면
결국 “이번 프로모션 이후 유저가 늘긴 했는데, 어떤 채널에서 유입된 신규 유저의 리텐션이 가장 높은가요?” 같은 질문에 답하려면 애널리틱스만으로는 부족했다. MMP 콘솔에서 채널별 유입 데이터를 내려받고, 애널리틱스에서 리텐션 데이터를 따로 추출한 뒤 두 데이터를 수동으로 조합하거나 데이터 팀에 별도 분석을 요청해야 했다. 데이터는 있었지만 흩어져 있었고, 연결하는 데 시간과 사람이 필요했다.
새로운 버전의 애널리틱스에서는 MMP를 연동하면 광고 채널별 설치·전환 이벤트가 애널리틱스로 바로 유입된다. Airbridge는 Hive 콘솔 내 마케팅 어트리뷰션 설정만으로 연동되고, AppsFlyer와 Adjust는 포스트백 설정을 완료하면 이벤트 데이터를 수신하기 시작한다. 연동이 완료되면 MMP 이벤트는 게임 내 이벤트와 동등한 데이터 소스로 취급된다. MMP 콘솔로 이동하지 않고도 애널리틱스에서 차트·퍼널·리텐션 어디서든 MMP 이벤트를 바로 활용할 수 있다.
연동 화면 – MMP 연동 현황 확인새로운 버전의 애널리틱스에 수집된 MMP 이벤트 예시
데이터가 합쳐지면 분석할 수 있는 질문의 폭이 달라진다. 퍼널 분석에서 MMP의 앱 설치 이벤트를 첫 번째 단계로 놓고, 이후 게임 내 첫 로그인, 튜토리얼 완료, 첫 결제 이벤트를 순서대로 연결하면 광고 노출부터 첫 결제까지의 전체 전환 흐름을 하나의 퍼널로 확인할 수 있다. 어느 단계에서 이탈이 가장 많이 발생하는지도 한눈에 보인다.
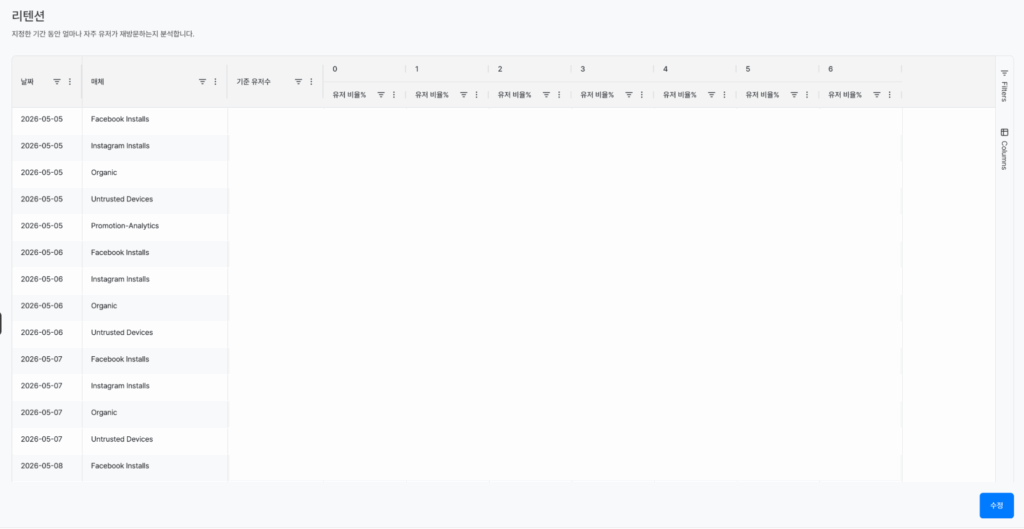
리텐션 분석에서는 MMP 속성을 차원값으로 설정하면 채널별 유저 품질을 정밀하게 비교할 수 있다. “Google Ads에서 유입된 유저와 Meta Ads에서 유입된 유저 중 30일 후에도 게임을 하고 있는 비율”을 단일 차트에서 나란히 볼 수 있다. CPI(설치당 비용)가 낮은 채널이 반드시 좋은 채널은 아니라는 사실을 리텐션 데이터로 직접 증명할 수 있게 된 것이다.
MMP 유입 채널을 차원으로 설정한 채널별 리텐션 비교
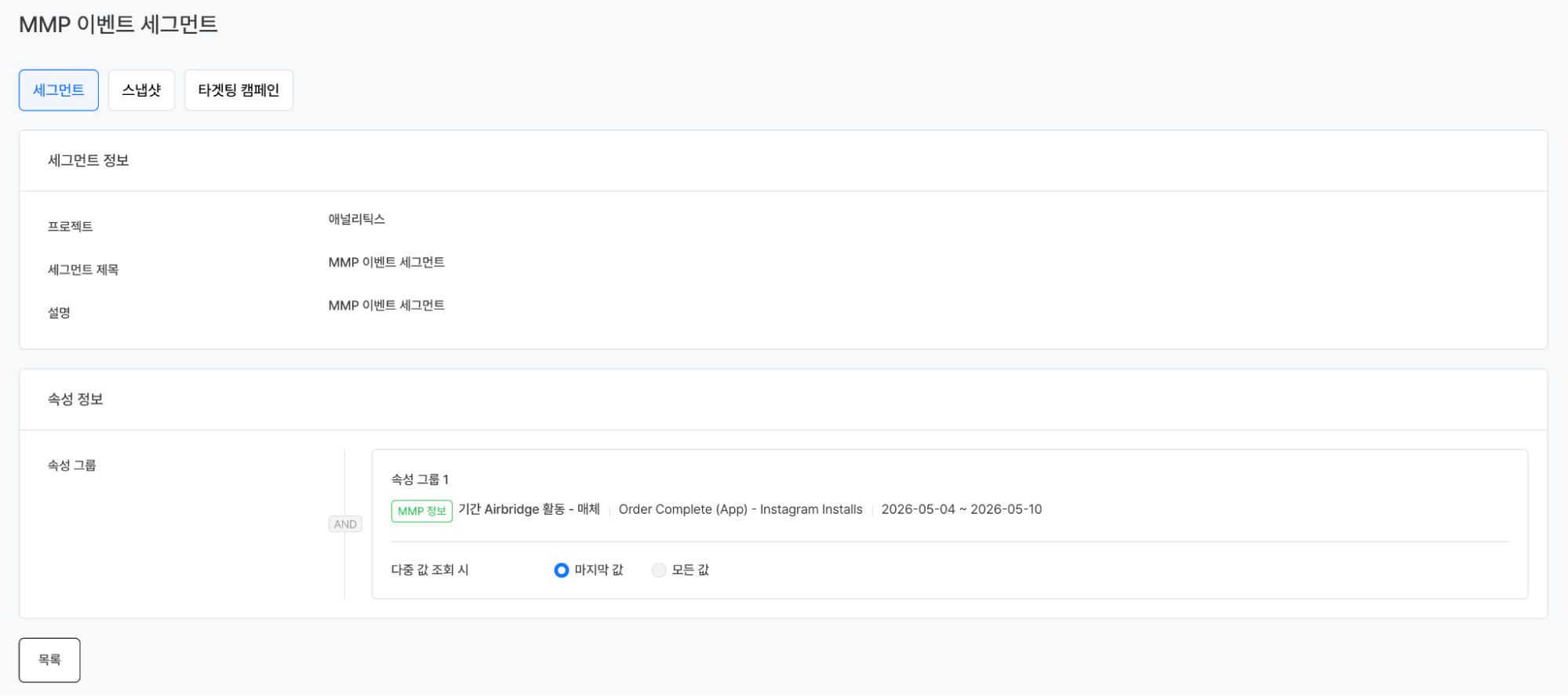
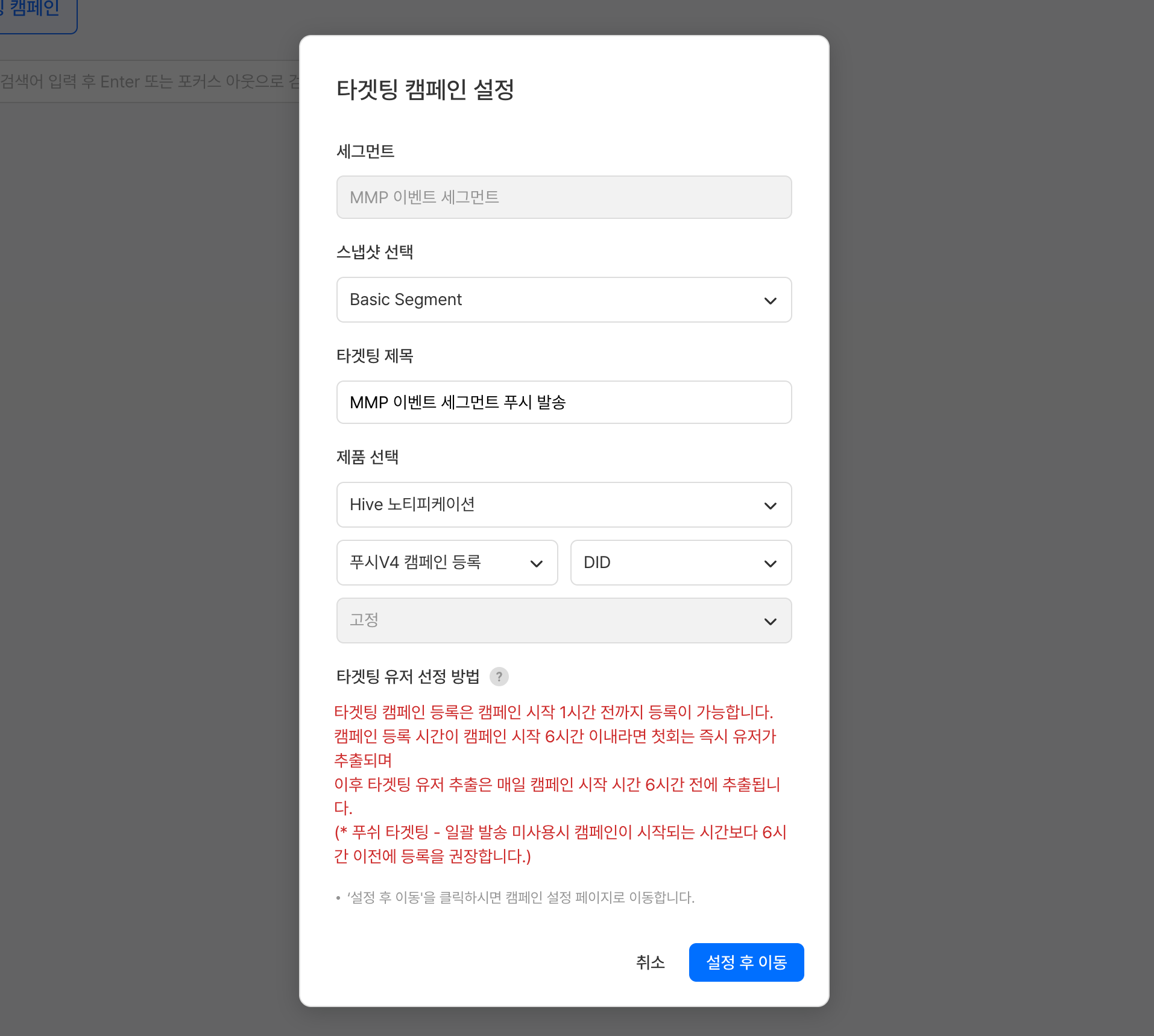
분석에서 그치지 않고 마케팅 액션으로 바로 이어질 수도 있다. 리텐션이 낮은 채널로 유입된 유저를 세그먼트로 정의하고 해당 세그먼트의 스냅샷을 생성하면, Hive 프로모션·노티피케이션 제품과 연계해 타겟팅 캠페인을 즉시 진행할 수 있다. 데이터를 보는 것과 마케팅 액션을 취하는 것 사이의 간격이 사라지게 된다.
MMP 이벤트 활용 세그먼트 생성세그먼트 활용 타겟팅 캠페인 등록
CLOSING
맺음말
새로운 버전의 애널리틱스는 SQL 없이, 로그 정의 없이, 여러 분석 툴을 오가지 않고도 데이터 기반 의사결정을 내릴 수 있는 분석 환경을 목표로 출시됐다. UI 기반 분석의 ‘접근성’, ELT 기반 이벤트 수집의 ‘유연성’, MMP 통합을 통한 데이터의 ‘연결성’. 이 세 가지를 모두 확보하여 사업·마케팅 담당자부터 데이터 분석가, 개발자까지 각자의 역할에 맞게 활용할 수 있도록 설계했다. 새로운 버전의 애널리틱스는 지속적으로 기능을 고도화하고 있다. 더 많은 사용자의 데이터 기반 의사결정에 실질적인 도움이 되길 바란다.
참고
새로운 버전의 애널리틱스는 Hive 콘솔 가입 후 직접 만나볼 수 있다. 자세한 소개 및 사용 방법은 Hive 애널리틱스 가이드를 통해 확인바란다.
📌 더 알고 싶다면?
Hive 애널리틱스에 대해 궁금한 점이 있는 경우 아래로 문의해 보자.
👉🏻 컴투스플랫폼 AI개발2실: P-AI2@com2us.com
엄영민, 주성호 기자
애널리틱스의 신규 기능을 소개하게 되어 기쁩니다. 좋은 제품을 만들기 위해 함께 고민하고 구현해주신 모든 분들께 감사드립니다. AI개발2실에서는 게임 운영 의사결정에 도움이 되고자 열과 성을 다해 여러 기능을 개발하고 연구하고 있으니 앞으로도 애널리틱스 제품에 많은 관심 부탁드립니다.