






관련글

모니터링 시스템 안정성을 높인 InnoDB Cluster 기반 DB 고가용성 구축 사례
서비스 운영에서 모니터링은 단순한 보조 시스템이 아니다. 24시간 운영되는 서비스의 상태를 가장 먼저 확인하고 이상 징후를 알려주는 핵심 운영 시스템이다. 서버 리소스와 애플리케이션 상태, DB 상태, 로그, 알람 등 다양한 운영 데이터는 모니터링 시스템을 통해 수집·집계된다. 운영자는 이를 바탕으로 이상 징후를 사전에 파악하고, 문제가 발생하면 신속하게 대응한다. 또한 장애 이후에는 축적된 지표와 로그, 알람 이력을 […]

비개발자 디자이너가 AI로 사내 업무 툴을 만들기까지. SD Archive 개발기
AI MeetUP이 만든 첫 번째 도전 나는 코딩의 ‘코’ 자도 모르는 비개발자 디자이너다. 하지만 바이브 코딩이 새로운 개발 방식으로 자리 잡고, AI 활용 능력이 점점 중요해지고 있다는 것은 실감하고 있다. 그래서 AI를 배울 수 있는 팀 스터디와 AI ART CAMP 등에 꾸준히 참여했고, 이번에는 조직문화팀이 주최한 AI MeetUP에도 참가하게 됐다. AI MeetUP에서는 마스터인 조지훈 차석님의 […]

SQL도, 로그 정의도 없이: Hive 애널리틱스 신규 버전 구축기 1편
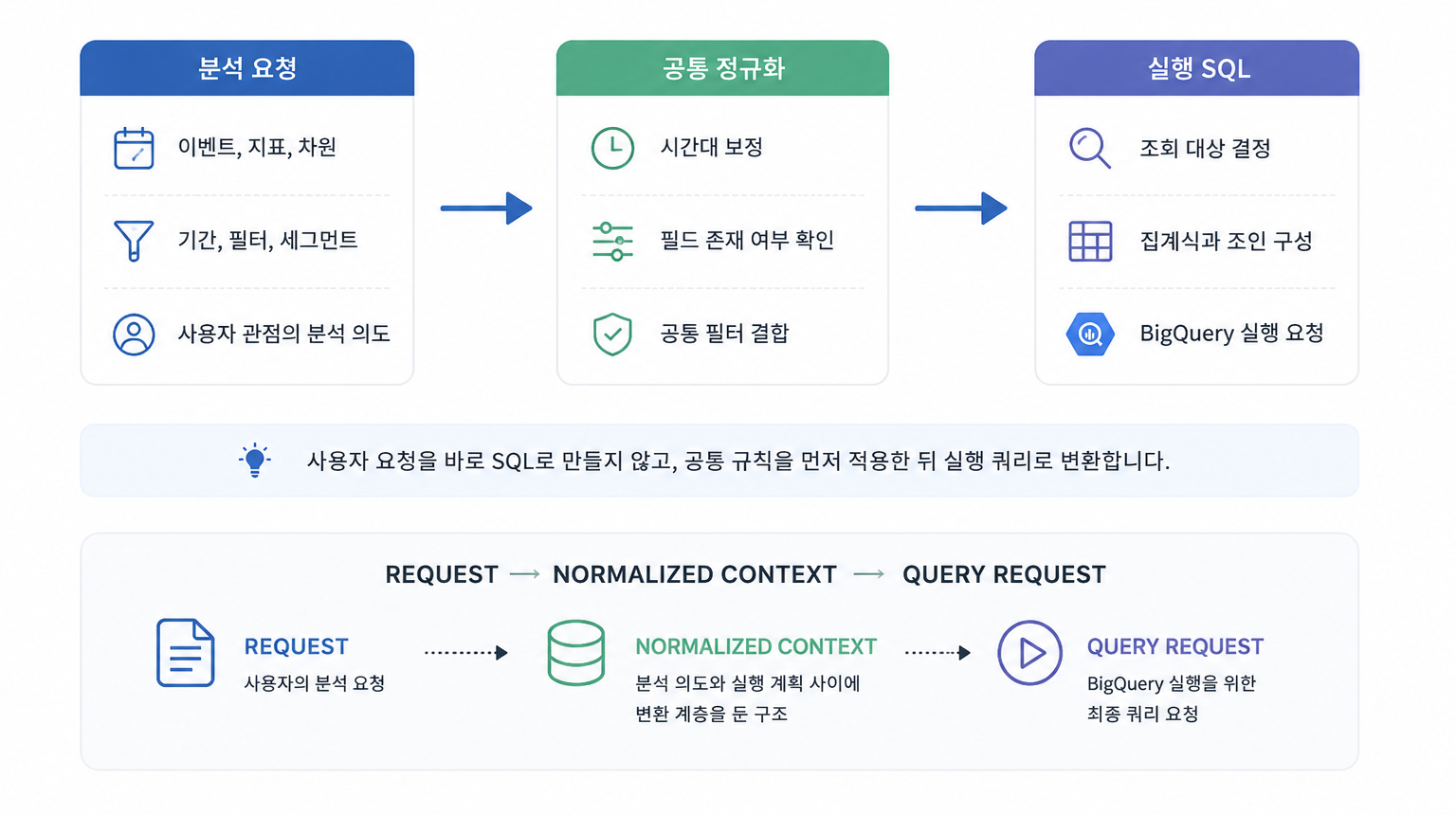
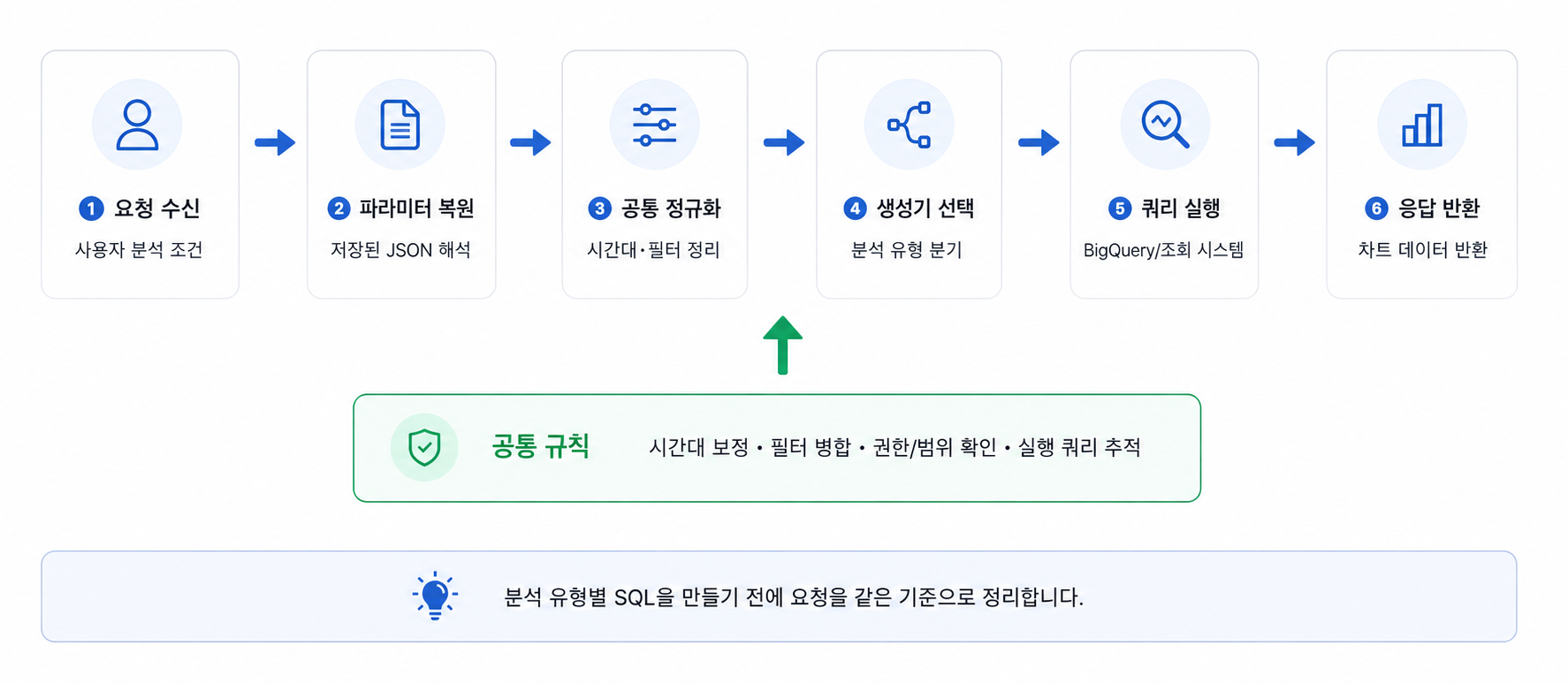
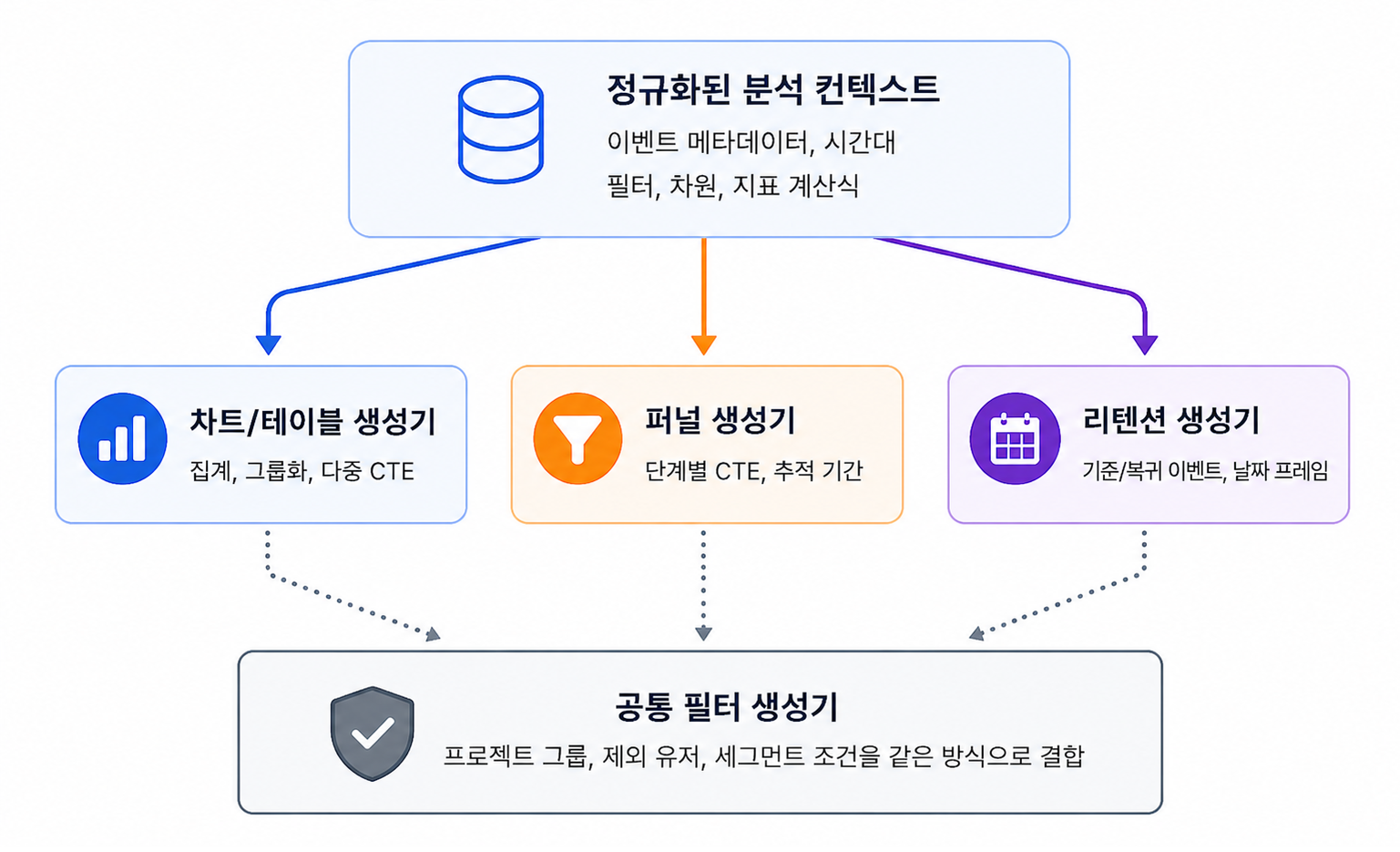
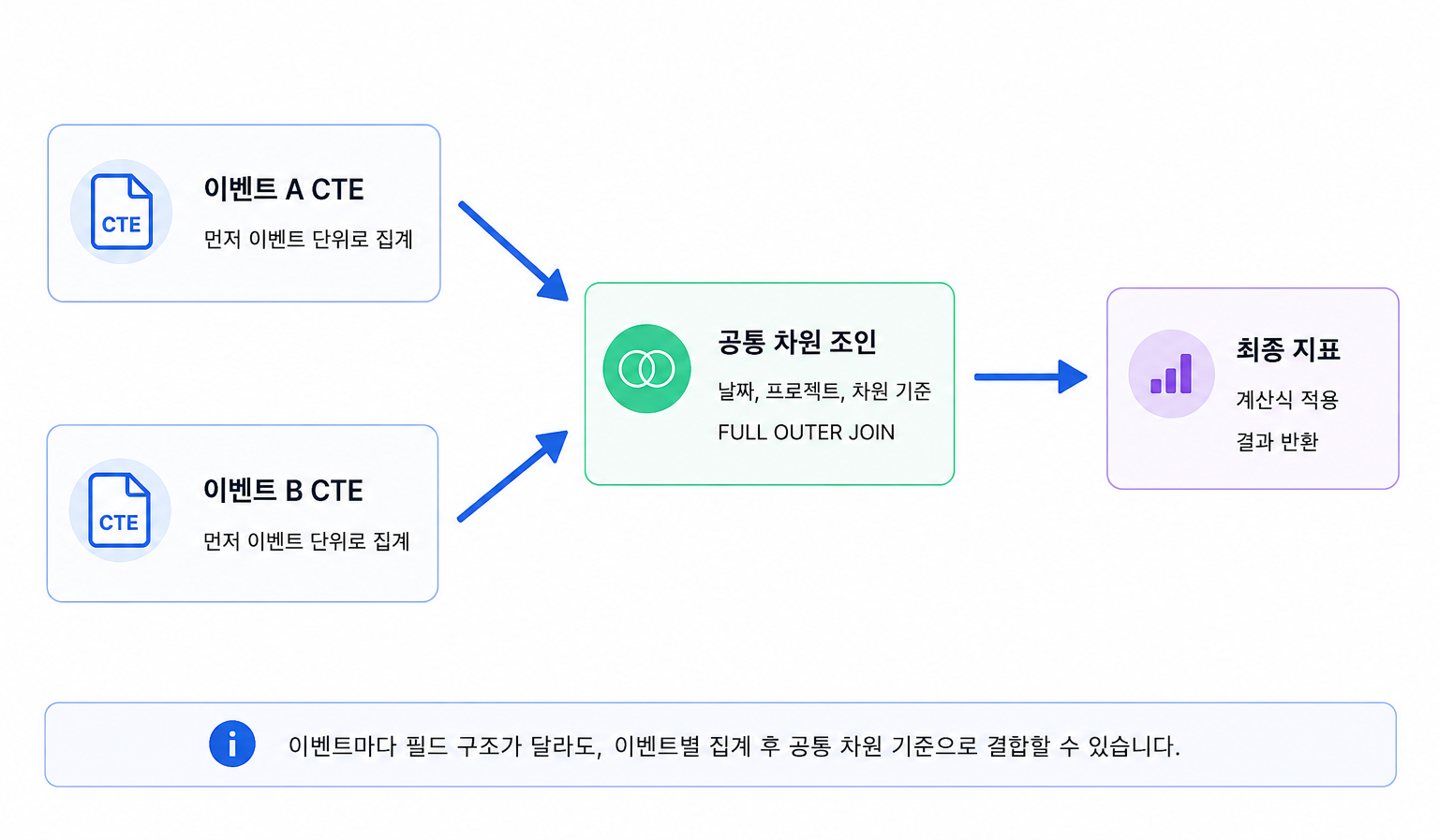
“캐릭터 직업 변경 이벤트 전/후 매출 변화는 얼마인가요?”, “이번 시즌 출석 이벤트가 이탈 유저 복귀에 효과가 있었나요?”, “이번 프로모션 이후 유저가 늘긴 했는데, 어떤 채널에서 유입된 신규 유저의 리텐션이 가장 높은가요?” 오랫동안 사랑받는 게임을 만들고 싶다면 한 번쯤 마주치는 질문들이다. 한정된 리소스 안에서 마케팅 예산을 배분하고, 차기 프로모션을 기획하고, 운영 방향을 결정하기 위해 데이터 분석은 […]

2026 플레이엑스포 현장 후기: 게임 축제의 열기와 Hive의 글로벌 가능성
국내 대표 복합 게임 쇼 ‘2026 PlayX4’의 개막 국내 대표 게임 전시회 중 하나인 ‘2026 플레이엑스포(PlayX4)’가 지난 5월 21일부터 24일까지 나흘간 경기도 고양시 킨텍스 제1전시장에서 개최됐다. EVENT INFO 2026 플레이엑스포 (PlayX4) 기간 2026.05.21 (목) ~ 2026.05.24 (일)4일간 장소 일산 킨텍스(KINTEX) 제1전시장3홀 · 4홀 · 5홀 주요 내용 국내외 게임사 B2C 게임 전시 · B2B 게임 […]

Goodbye CocoaPods: SPM으로 환승이별 하기
이별할 준비를 하자 “ CocoaPods Trunk Read-only Plan ” iOS 개발자 치고 ‘코코아팟(CocoaPods)’을 모르는 사람이 있을까. 2024년 겨울, 코코아팟이 말했다. “우리, 생각할 시간을 갖자.” 완전한 셧다운이라기보다는 ‘더 이상의 적극적 유지보수를 보장하지 않는다’에 가까운 톤이지만, 사실상의 이별이다. 십수 년간 반쯤 표준이었던 녀석이 돌연 시한부를 선언하며, 우리 Hive SDK는 눈에 그닥 차지 않던 어색한 신예와 예상보다 빨리 […]

바이브 코딩을 넘어 AI 시대 개발 프로세스
2025년 2월, Andrej Karpathy가 X(트위터)에 짧은 글을 올렸다. “바이브 코딩(Vibe Coding)”이라는 표현이었다. AI에 완전히 몸을 맡기고, 코드가 존재한다는 사실조차 잊어버리는 새로운 개발 방식. 그 글은 며칠 만에 수백만 건의 조회 수를 기록했고, 이후 뉴욕타임스·가디언·아스 테크니카가 연달아 보도했다. 콜린스 영어사전은 2025년의 단어로 ‘vibe coding’을 선정했다. 이처럼 AI와 협업하는 개발 방식은 빠르게 확산되고 있다. 개발자는 이제 코드를 […]

Under the Hood: Linux Epoll — 리눅스 커널 소스코드로 살펴보는 epoll의 내부 동작
개론 클라이언트의 요청을 처리하는 서버를 구축할 때는 일반적으로 TCP, UDP 프로토콜을 기반으로 통신을 처리한다. 이때 모든 네트워크 통신은 기본적으로 소켓(Socket)이라는 단위를 통해 관리된다. 아키텍처 관점에서 보면 하나의 프로세스 또는 스레드가 하나 이상의 소켓을 동시에 처리할 수 있다. 하지만 여러 소켓을 효율적으로 처리하려면 I/O Multiplexing(입출력 다중화) 메커니즘이 필요하다. 이를 통해 단일 스레드 또는 프로세스가 여러 I/O […]

웹 상점은 혼자 크지 않는다: 커뮤니티·PG 결제가 완성하는 게임 매출 구조
게임 산업에서 웹 상점은 이제 선택지가 아니라 전략 그 자체가 되었다. 앱 마켓 수수료 절감, 낮은 결제 수수료를 통한 수익 개선, 유연한 글로벌 결제 전략 구성. 표면만 놓고 보면 웹 상점은 더없이 매력적인 무기다. 특히 모바일 게임 시장에서는 앱 마켓의 수수료 구조를 벗어나기 위해 웹 상점을 도입하는 흐름이 빠르게 확산되고 있다. 그런데 정작 많은 게임사들이 […]
