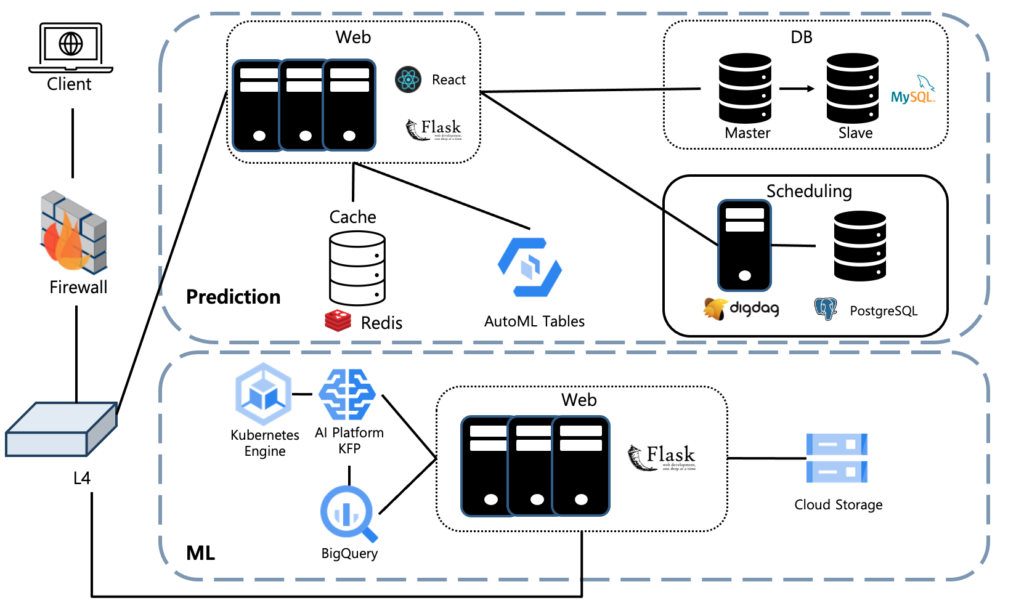
클라이언트는 방화벽을 통해 Hive 콘솔의 예측(Prediction) 웹페이지에 접근 할 수 있습니다.
머신러닝(ML)은 외부에서 접근이 불가하며 예측(Prediction)에서 L4를 통해 API 접근이 가능합니다.
예측(Prediction)은 스케줄링 서버들을 이용하여 AutoML Tables의 검증된 서비스 모델 정보를 DB에 업데이트 하며, 클라이언트가 예약한 일자,시간에 일괄 예측을 수행합니다.
머신러닝(ML) API는 Google Cloud Platform의 BigQuery에 저장된 트레이닝/서빙 수행 이력과 Kubernetes Engine 위의 KFP(Kubeflow Pipeline)의 API를 호출하고, Cloud Storage에 저장한 수행 결과물을 조회합니다.
프론트엔드 구성
그림 6. React와 Mobx
프론트엔드의 기반 라이브러리로 최근의 프론트엔드 웹 개발에서 많이 사용되는 React를 사용 하여 개발하였습니다. (참고:프론트 프레임워크 트렌드)
React를 선택한 이유
Component 단위 작성
JQuery를 통해 DOM을 컨트롤하는 방식의 프론트엔드 개발은 예전부터 많이 사용되었던 방식이지만 문제점이 많았습니다. DOM을 직접 접근하여 조작하다 보니 직관적으로 느껴질 수 있지만 코드가 늘어날수록 어떤 부분에서 상태값이 변하는지 추적하기 어려워지고 유지보수는 고통스러워졌습니다. 컴포넌트는 스스로 상태를 관리하고 캡슐화된 개별적 뷰 단위로 이 컴포넌트를 조합하여 UI를 만들 수 있습니다. 이로 인해 생산성이 높아지고 유지보수가 용이해집니다.
JSX
JSX는 JavaScript를 확장한 문법으로, html 태그안에 JS 코드를 함께 작성하여 하나의 객체를 만들 수 있고 이는 관심사를 분리시켜 객체지향적인 코드를 작성하기 위한 기반이 되고 가독성이 높아집니다.
Virtual DOM
DOM의 변경이 필요할때 Virtual DOM은 변경될 부분의 레이아웃만 계산하여 해당 레이아웃만 실제 DOM에서 리렌더링 하기 때문에, 불필요한 버그를 방지하고 빠른 성능을 보여줍니다.
ES6 문법 사용
웹 개발시 다양한 브라우저 환경으로 인하여 ES6 문법의 사용은 제약이 많지만, React는 기본적으로 webpack과 Babel 라이브러리를 사용하여 ES6 문법의 사용을 가능하게 해줍니다. ES6는 기존 JS에 부족했던 부분에 대한 많은 개선이 있기 때문에 효율적이고 생산적으로 개발할 수 있게 해줍니다.
큰 개발 생태계와 실제 비즈니스에서의 폭넓은 사용
React는 Facebook에서 개발하였고, 이런 거대 IT 기업에서 지원하고 관리하는 React 는 빠르게 큰 생태계를 만들어 왔습니다. 현재 Facebook 뿐만 아니라 Airbnb, 네이버, 카카오 등 많은 수의 기업에서 프론트엔드의 개발에 폭넓게 사용되고 있습니다. 이는 개발 중이나 유지보수 중에 문제가 발생했을 때 더 빠르고 쉽게 해결할 수 있는 가능성을 높여주는 중요한 장점입니다. React 외에 Angular, Vue 등 최근 각광받는 프레임워크 라이브러리들이 있지만 이중에 React는 이러한 장점이 가장 컸습니다.
React는 부모 컴포넌트에서 자식 컴포넌트로의 단방향 데이터 흐름을 지향합니다. 이는 단순한 흐름으로 이해와 관리가 쉽지만, 실제 개발시에 단방향 데이터 흐름만으로 상태 관리를 하기에는 부족한 점이 많기 때문에 Redux, Mobx 같은 상태 관리 라이브러리를 거의 필수적으로 함께 사용하게 됩니다. 대표적인 이 두 개의 상태 관리 라이브러리 중 선택한 것은 Mobx 입니다. (참고:React에서 Mobx 경험기)
Mobx를 선택한 이유
객체지향적
Redux는 함수형 프로그래밍의 영향을 받습니다. 많은 사람들이 객체 지향적 프로그래밍에 더 익숙하기 때문에 Mobx의 구조는 접근이 쉽습니다.
간결함
Mobx의 핵심 구조는 다음과 같이 표현할 수 있습니다
observable 상태에 대해 action을 통해 변화를 주었을 때 이에 대한 reaction 을 할 수 있고, 해당 상태에 대한 computed된 값을 얻을 수 있음
이렇듯 동작하는 구조가 직관적이고 각 개념과 동일하게 매칭되는 키워드로 간결한 코드를 작성할 수 있습니다.
낮은 러닝커브
이해하기 쉽고 간결한 구조는 결국 빠르게 배워 적용할 수 있는 큰 장점이 되고, 단순히 status의 편리한 관리가 필요했던 목적에 부합합니다. Redux는 필요에 따라 더 많은 기능을 제공해 줄 수 있겠지만 목적에 불필요한 기술의 남용은 오히려 통제가 어려워지는 관리 요소가 될 수 있습니다.
자체 디자인과 마크업을 베이스로 적용하였고, 추가로 각 UI 요소 일부에 Material UI 라이브러리를 사용하였습니다. 이를 기반으로 커스텀한 자체 컴포넌트들을 구성하였고, 자체 스타일이 적용되면서 라이브러리와 충돌하는 부분이 없도록 세부 조정을 하였습니다. 프론트엔드는 React 기반의 SPA(Single Page Application)이기 때문에 웹 API를 통해 백엔드와 통신하였습니다. 일반적인 상황에서는 이러한 웹 API 통신만으로 충분했지만 이후 언급할 문제의 해결을 위해 추가적인 통신 방식이 필요하게 되었고, 웹 소켓을 통한 통신이 추가 되었습니다.
백엔드 구성
그림 7. Python Flask RESTful API
백엔드 웹 프레임워크로는 Python Flask를 선택하였습니다.
Flask를 선택한 이유
간결함
아래 코드는 완벽하게 작동하는 플라스크 웹 프로그램입니다. Flask는 이렇듯 간결한 구조로 개발이 가능하기 때문에 생산성이 높습니다.
확장성, 높은 자유도
Flask는 처음부터 모든 기능을 포함하고 있지 않은 마이크로 웹 프레임워크이고 그로 인해 높은 확장성과 자유도를 갖게 해줍니다. Flask 확장 라이브러리들을 붙여서 쓰기가 편하기 때문에 복잡한 규칙을 따라야 하는 다른 무거운 웹 프레임워크에 비해 확장 기능을 다양하게 조합하고 필요한 기능들을 상황에 맞게 선택하여 유연하게 개발할 수 있습니다.
API 구현 목적에 적합
프론트엔드를 React를 통해 SPA로 개발하기 때문에 백엔드에서는 API로 데이터 처리만 제공하면 되어 백엔드의 부담이 줄어듭니다. SPA에서 API 기능을 구현할 때 Flask는 간결한 코드를 통해 빠르게 원하는 기능을 개발할 수 있습니다.
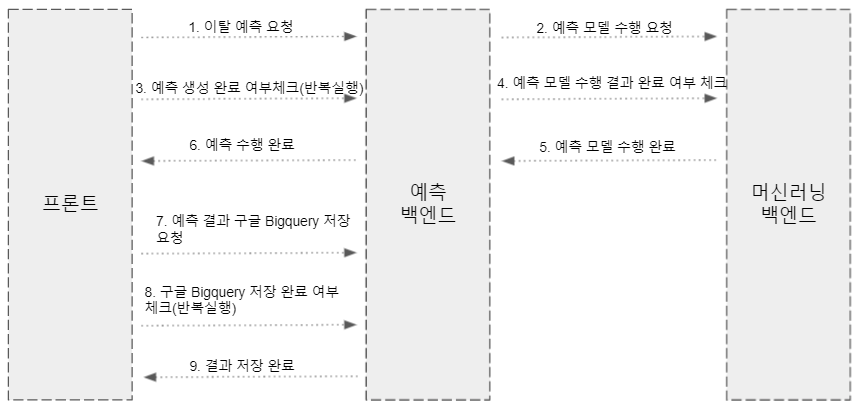
일반적으로 웹 서비스에서 짧은 시간 단위의 응답을 주는 CRUD와 같은 요청은 프론트엔드에서 백엔드로 동기 방식의 HTTP 통신으로 충분합니다. 하지만 예측 서비스는 예측 모델을 수행하고 완료되기까지 오랜 시간이 걸리기 때문에, polling 요청 방식으로 구현하였고, 여러가지 문제점이 발생하였습니다.
이렇듯 동기 방식의 통신은 오랜 시간이 소요되는 작업에는 적합하지 않았기 때문에 MSA 서비스 간의 비동기 방식의 통신이 필요했습니다. (참고: 마이크로서비스 프로세스 간 통신)
표 1. 동기 방식/비동기 방식 통신
일대일
일대다
동기
요청/응답(request/response)
–
비동기
알림(notification)
발행/구독(publish/subscribe)
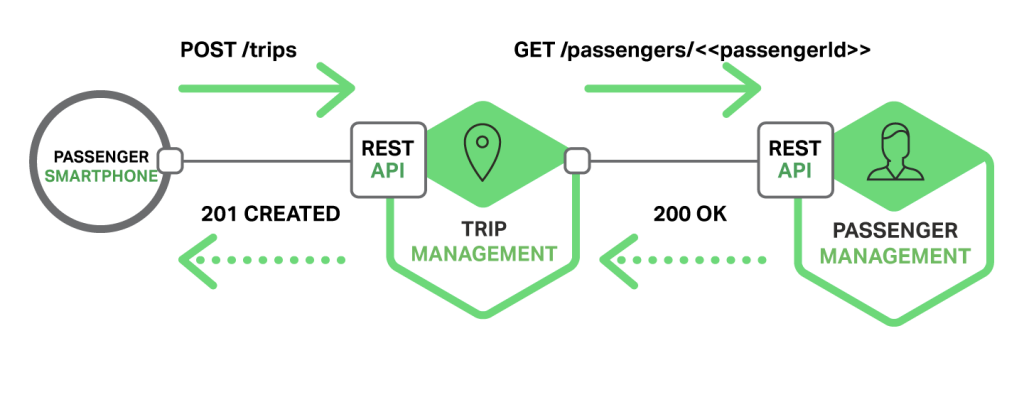
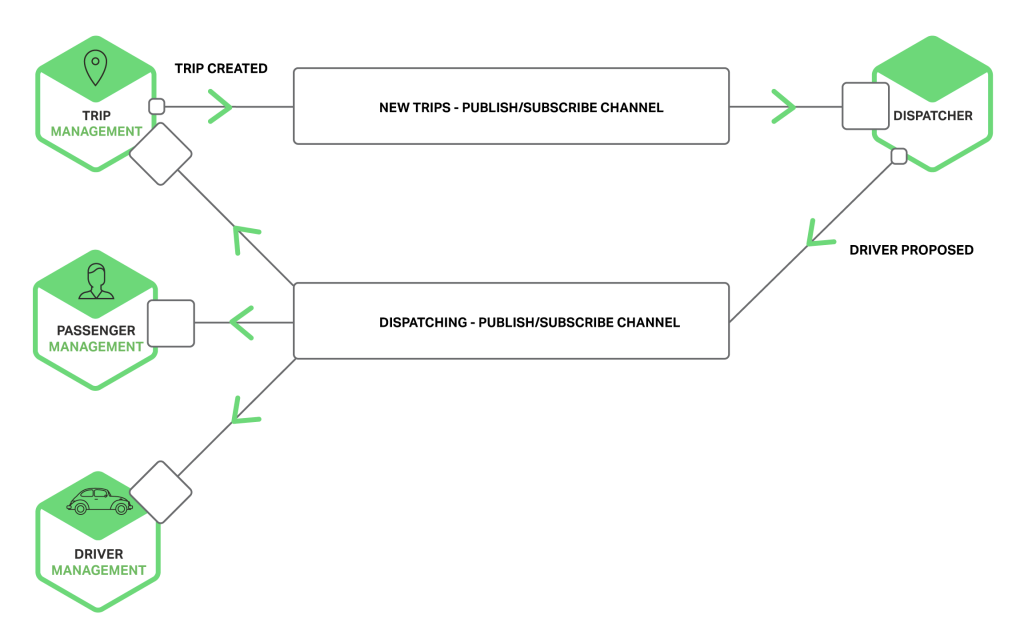
그림 9. 동기 방식 통신의 예그림 10. 비동기 방식 통신의 예
일대다 비동기 통신을 위한 발행/구독 모델 방식으로의 개선을 검토하였고, Event-Driven-Architecture, Observer 패턴의 개념을 일부 적용하여 각 서비스 간의 의존성을 최소화 하였습니다. RabbitMQ, Kafka 등의 비동기 오픈소스 솔루션을 도입하지는 않았는데 현재로선 단순히 상태값에 대한 비동기 통신만이 필요하고 해당 트래픽의 양이 미미하기 때문에 DB를 통한 데이터 제공으로 충분하였기 때문입니다. 추후 비동기 통신의 사용 서비스와 트래픽의 증가함에 따라 이러한 비동기 솔루션을 결합하여 적용하는것도 가능할 것입니다.
개선된 서비스의 플로우는 다음과 같습니다.
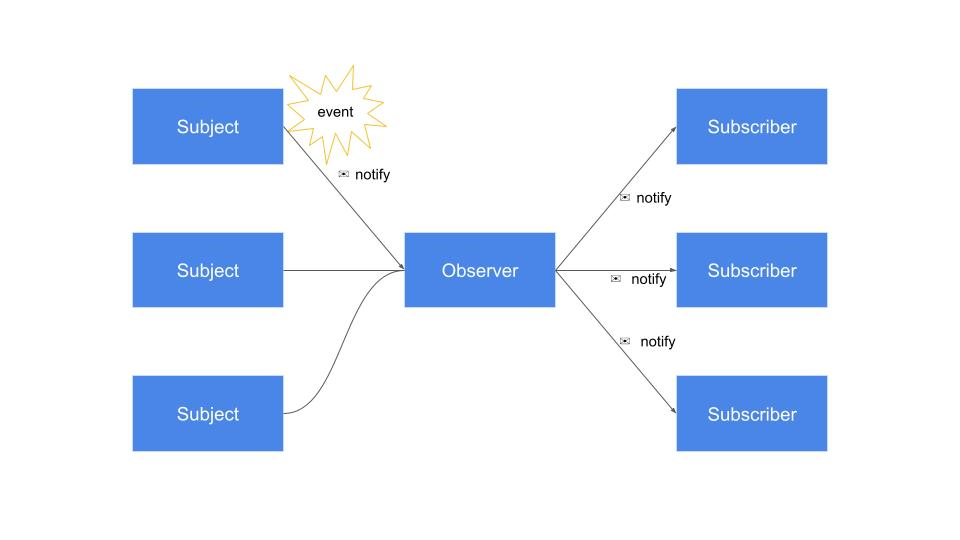
관찰할 Subject(예: 파이프라인 상태)를 정한 후 해당 Subject를 감시할 Observer, Subscriber(예: 예측 서비스)를 DB에 등록
Subject가 데이터 변경시 Subscriber로 notify 요청하거나 Observer가 Subject를 감시 후 데이터 변경시 notify 요청
Subscriber는 해당 알림 요청을 서비스 로직에 맞게 처리
그림 11. Observer 서비스 구조
예측 서비스에서는 Observer 서비스를 통해 ML Serving 파이프라인의 실행과 애널리틱스 세그먼트 스냅샷 생성 후 완료 여부의 알림을 받는 방식으로, 기존의 동기 방식을 대신하여 비동기 방식 통신을 적용하게 되었습니다. 또, 백엔드와 클라이언트 간에도 역시 WebSocket의 비동기 통신을 적용하여 데이터의 변경이 있을때 백엔드에서 프론트엔드로 바로 알릴 수 있는 구조를 만들었습니다. 해당 구조를 적용하는 과정에서 Flask-SocketIO 라이브러리를 도입하였을 때, Gunicorn에 worker-class로 gevent 등의 greenlet 기반의 워커를 적용하였을 때, BigQuery의 결과를 데이터프레임으로 만드는 코드와 쓰레드 생성 부분에서 문제가 생기는 등 일부 이슈가 있기도 했으나 발생한 이슈를 트래킹하여 worker-class 교체로 해결하였고, 최종 적용을 완료하였습니다.
이러한 문제점에 대한 고민을 통해 기존의 아키텍처를 재설계하여 적용한 결과 다음과 같은 개선을 이룰 수 있었습니다.
통신의 효율 증대 및 전체적인 성능 향상
상태 추적과 디버깅이 쉬워짐
중복 데이터의 처리가 필요하지 않게 됨
서비스 간 의존적이지 않은 비동기 통신 적용으로 MSA 구조의 장점을 살림
추후 다른 서비스에서도 빠르게 비동기 통신 로직 적용이 가능
맺음말
머신러닝 기술을 이용하여 제품을 만들고 서비스하는 것에는 많은 어려운 문제들이 있습니다. 단순히 좋은 모델을 만드는 것 뿐만이 아니라, 모델의 성능을 계속해서 유지하는 것이 핵심이고, 그러기 위해서는 모델을 개발하는 것 이상의 것들이 필요합니다.
우리 역시 처음에는 모델을 만드는 것에 집중하였고, 이는 제품을 서비스할 때에 많은 어려움이 있다는 것을 느꼈습니다. 이에, Google의 컨설팅을 통해 파이프라인을 구축하고, MLOps의 개념을 이해하여 업무에 적용시켰으며 그 결과로 안정적인 서비스를 유지할 수 있었습니다.
김윤기, 최보희, 김석근, 성지현
머신러닝 기술을 활용하여 예측 모델 생성과 운영, 서비스를 제공하고 있습니다. 머신러닝은 완벽하지 않지만, 기존의 한계성을 한 단계 뛰어넘을 수 있는 기술이라고 생각합니다. 이 글을 통해 좋은 기술을 각 분야에서 안정적으로 적용하고 사용할 수 있는데 참고가 되었으면 좋겠습니다. 감사합니다.