컴투스플랫폼에서도 챗봇 서비스를 개발하고 있으며, Hive 기반으로 서비스하고 있는 일부 게임에 챗봇 서비스를 제공하고 있습니다.
컴투스플랫폼의 챗봇 시스템은 사용자 발화의 의도를 추론하는 모델을 기반으로 한 시스템입니다. 이러한 ‘발화의 의도’를 인텐트(Intent)라고 하며, 자연어 처리(Natural Language Processing) 모델을 통해 사용자의 발화를 분석해 가장 적절한 인텐트로 분류한 후, 그에 맞는 답변을 제공하고 있습니다.
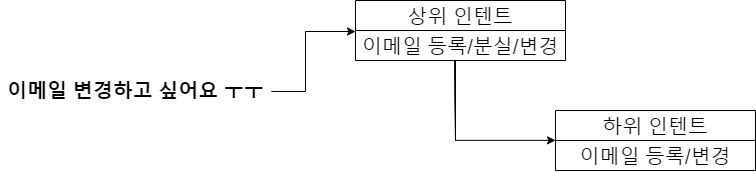
<그림 1. 인텐트 구조 예제>
챗봇 학습을 위한 데이터는 위의 그림과 같이 계층형 구조로 구성되어 있습니다.
상위 인텐트는 여러 개의 하위 인텐트를 포함하는 더 넓은 카테고리이며, 하위로 갈수록 인텐트를 더 세부적으로 분류합니다. 게임에 따라 다르지만, 보통 2~3개의 인텐트 계층으로 이루어져 있습니다.
기존에는 상위 인텐트를 분류하여, 사용자가 하위 인텐트를 선택하도록 서비스를 제공하고 있었습니다. 하지만 더 구체적인 정보를 담고 있는 하위 인텐트를 분류해 제공한다면 사용자에게 더 편리한 사용 경험을 제공할 수 있습니다.
따라서 상위 인텐트뿐만 아니라 하위 인텐트까지 분류할 수 있는 모델 개발이 필요함을 느꼈습니다.
그런데 기존 챗봇과 같은 구조의 모델로 하위 인텐트를 학습하는 것을 테스트해 보았더니 서비스를 제공하기에 충분한 성능이 나오지 않았습니다. 거기에 기존 챗봇은 여러 모델의 앙상블로 이루어져 있기에, 원하는 성능이 나오더라도 상위 인텐트 앙상블 모델과 하위 인텐트 앙상블 모델을 함께 관리해야 하는 유지 보수 측면에서도 효율성이 떨어지는 문제가 있었습니다.
그래서 어떻게 하면 하위 인텐트의 성능을 높이면서, 동시에 유지 보수 측면까지 개선할 수 있을지 고민하게 되었습니다.
상/하위 인텐트는 서로 연관 관계가 있는 계층형 구조입니다. 이러한 특성을 활용해 모델을 학습시키면 상호 긍정적인 영향을 끼칠 수 있을 것이라는 가설을 세웠습니다.
따라서 서로 연관 있는 과제를 함께 활용해 성능을 높이는 Multi Task Learning(MTL)이 이러한 상황에 해결책이 될 수 있다고 판단했습니다. MTL을 활용해 상위 인텐트에서 학습된 정보가 하위 인텐트 학습에 도움을 주도록 해 성능을 높이고, 상/하위 인텐트 추론 모델의 통합을 목표로 MTL 기반 챗봇 모델을 개발하였습니다.
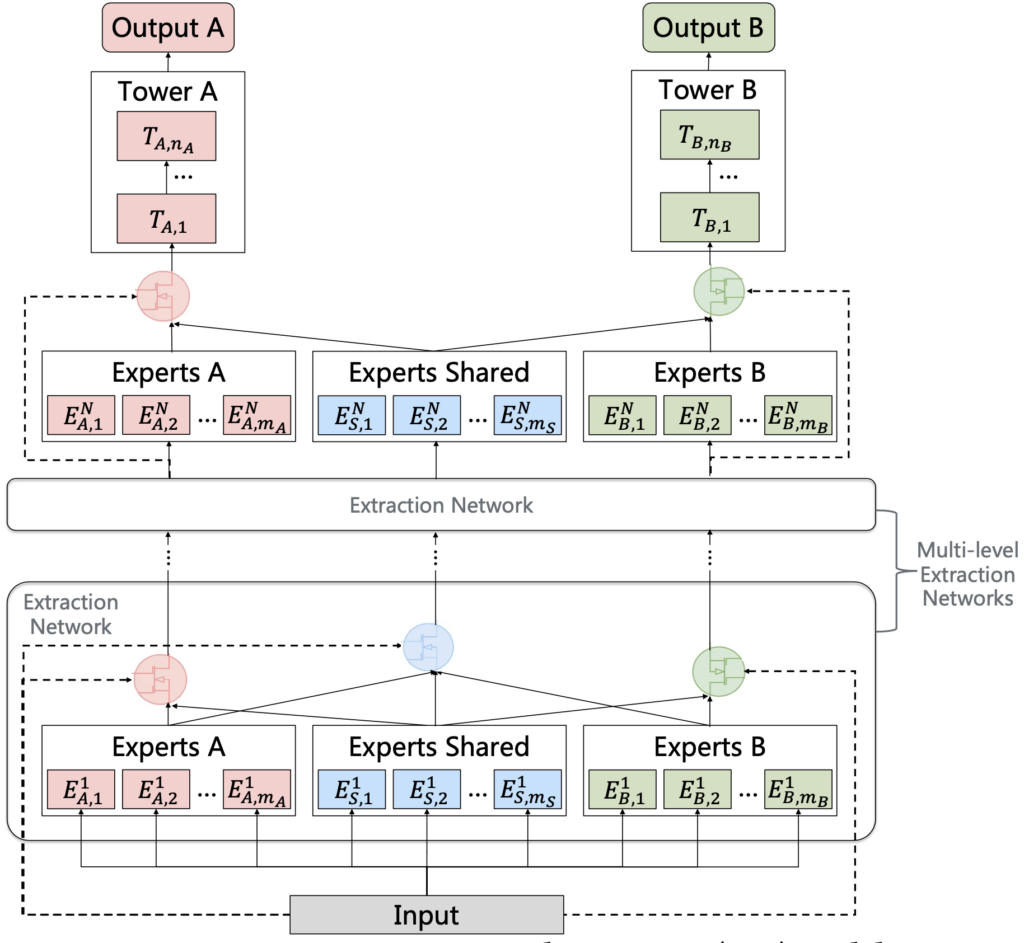
이번 챗봇 개발에는 Hard Parameter Sharing 중에서 PLE(Progressive Layered Extraction)라는 학습 방식을 사용했습니다.
PLE에 대해서 설명하기 전에 기반 개념인 MoE(Mixture of Experts)와 MMoE(Multi-gate Mixture of Experts)의 개념에 대해서 알아보도록 하겠습니다. MoE, MMoE, 그리고 PLE에서 공통으로 사용되는 레이어는 다음과 같습니다.
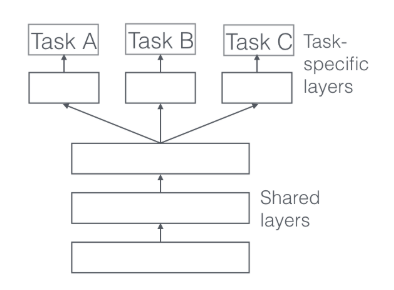
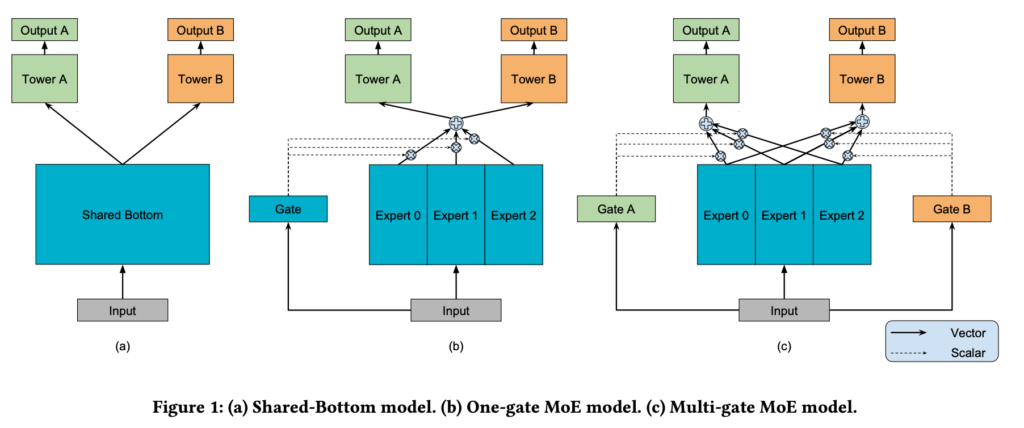
Mixture of Experts (MoE) 여러 Expert 레이어에서 나온 표현들과 Gate 레이어에서 나온 가중치를 가중합(Weighted Sum)하여 학습에 사용되는 과제 레이어에 적용하는 방식입니다. Gate 레이어를 통해 유의미한 표현만 사용될 수 있도록 가중치를 만들어주지만, 모든 과제에 동일하게 적용된다는 단점을 가지고 있습니다.
Multi-gate Mixture of Experts (MMoE) MoE의 단점을 보완하기 위해 Gate 레이어를 과제 개수만큼 늘린 학습 방식입니다. 이를 통해 Gate 레이어는 과제별로 적합한 가중치를 생성해 각 과제에 적합한 표현을 만들어줍니다.
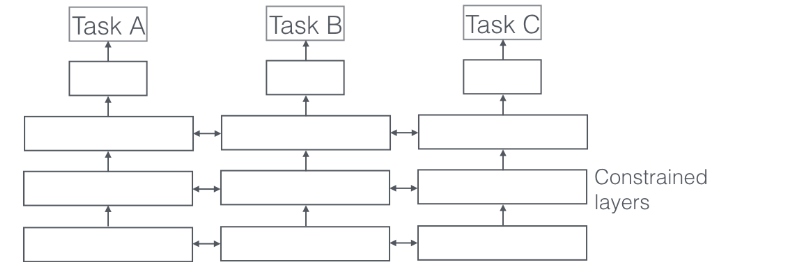
Progressive Layered Extraction (PLE) MTL에서 발생하는 문제인 Negative Transfer와 시소 현상을 해결하기 위해 만들어진 학습 방식입니다. PLE의 특징은 다음과 같습니다.
✅ Expert 레이어를 그룹으로 만들어 각 과제에 특화된 표현 생성
과제 (Task) Expert 그룹: 각 과제에 해당하는 표현을 생성해주는 Expert 그룹
공유(Shared) Expert 그룹: 모든 과제에 적용할 수 있는 표현을 생성해주는 Expert 그룹
✅ Gate 레이어를 통해 각 과제에 특화된 가중치 생성
과제 Gate 레이어: 공유 Experts 그룹의 표현과 Gate 레이어가 해당하는 과제 그룹에서 나온 표현들에 맞는 가중치 생성
공유 Gate 레이어: 모든 Expert 그룹에서 나온 표현들에 맞는 가중치 생성
✅ MoE, MMoE와 동일하게 표현과 가중치에 대해서 가중합 한 후 다음 레이어의 입력값으로 사용
✅ 과제끼리 직접적인 영향을 최소화했기 때문에 Negative Transfer와 시소 현상 해결
이번 챗봇 개발에는 인텐트 분류 모델을 개발하는 것이기 때문에 분류 모델에서 사용되는 Cross Entropy loss를 사용했습니다. 그리고 분류 레이어에 들어가기 전의 표현의 분별력(Discriminative Power)을 높여주기 위해 Margin-Mining loss의 일종인 CurricularFace loss를 결합해서 적용하였습니다.
Margin loss는 margin을 적용해서 같은 분류에 속하는 데이터는 가깝게, 다른 분류에 속하는 데이터는 멀어지게 해주는 손실 함수입니다. 이를 통해 기존 softmax 손실 함수보다 더 강한 분별력을 가질 수 있게 됩니다.
그러나 Ground Truth에 대한 margin만 고려하는 경향이 있고, 모든 분류 값에 대해서 동일한 가중치를 적용하기 때문에 실제 데이터에 적절하지 않을 수 있다는 단점을 가지고 있습니다.
Mining loss는 쉬운 데이터에는 가중치를 줄이고, 어려운 데이터에 대해서 가중치를 높여주는 손실 함수입니다. 이를 통해 모델이 어려운 데이터에 초점을 맞춰서 학습할 수 있게 됩니다.
그러나 어려운 데이터에 대해서 초기에 너무 강조되는 문제가 있기 때문에 오히려 수렴을 방해할 수 있고, 가중치를 직접 선택해야 한다는 단점을 가지고 있습니다.
Margin-Mining loss는 둘의 단점을 보완하기 위해 만들어진 손실 함수입니다. CurricularFace loss 이전에 MV-softmax loss에서 처음 사용된 개념입니다. 하지만 MV-softmax는 Mining loss와 동일하게 가중치를 직접 선택해 줘야 한다는 단점이 있습니다. 그래서 가중치를 잘못 설정했을 경우 모델이 수렴하지 않는 현상이 생길 수 있습니다. CurricularFace loss는 해당 문제를 해결하기 위해 가중치를 직접 선택하지 않고 학습 스테이지마다 가중치가 조절되도록 했습니다. 그래서 초기에 어려운 데이터에 대해서 강조되던 현상이 완화되고, 학습이 진행되면서 자연스럽게 어려운 데이터에 초점을 맞출 수 있게 되었습니다.
사전학습 모델(Pretrained Model)
MTL 학습 구조를 사용할 때 공통된 입력값으로 시작해야 합니다. 문자 자체를 입력 값으로 사용할 수 없기 때문에 문자를 임베딩(Embedding) 해주는 모델을 활용해서 적절한 입력값으로 만들어주는 과정이 필요합니다. 임베딩 레이어를 통해 입력값을 만들 수 있지만, 임베딩 레이어를 학습시키기 위해서는 수많은 텍스트 데이터가 필요합니다.
출처: Adobe stock
만약 적은 양의 데이터로 학습하게 될 경우 언어의 전반적인 의미를 파악하기 어렵고, 주어진 데이터에 과적합이 되기 때문에 새로 들어온 데이터를 맞추지 못하게 됩니다.
이번 프로젝트에서는 임베딩 레이어를 학습할 만큼 데이터가 충분하지 않았기 때문에 다른 방식으로 접근할 필요가 있었습니다. 데이터가 적을 경우에는 대용량 데이터를 기반으로 학습된 사전학습 모델을 활용해서 전이 학습(Transfer Learning)을 하는 것이 좋은 방법입니다. 자연어 처리 분야의 사전학습 모델은 대표적으로 BERT와 GPT가 있습니다.
출처: Adobe stock
이번 프로젝트에서는 문장의 전반적인 의미를 파악하는 데 강점이 있는 BERT 계열의 모델을 사용했습니다.
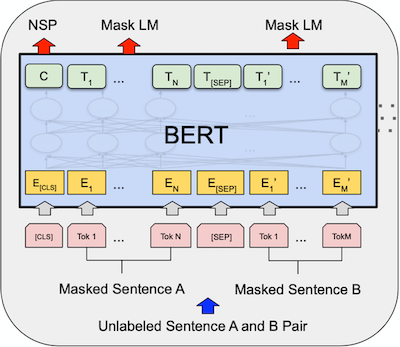
BERT는 트랜스포머의 인코더 구조를 활용했고, 레이블이 없는 텍스트 데이터를 MLM(Mask Language Modeling)과 NSP(Next Sentence Prediction)로 사전 학습한 모델입니다.
MLM: 문장 내의 15% 토큰에 마스킹한 후 마스킹 된 단어가 무엇인지 맞추는 방식
NSP: 두 개의 문장이 서로 연속된 문장인지 맞추는 방식
두 가지 학습 방식을 통해 언어에 대해서 전반적인 이해를 할 수 있게 되고, 다른 과제에 적용했을 때 기존의 지식을 활용해 더 높은 성능을 낼 수 있게 되었습니다.
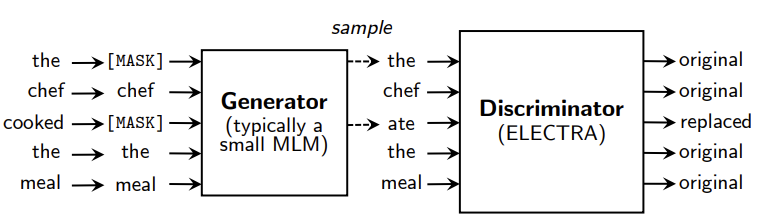
ELECTRA는 생성자(Generator)와 판별자(Discriminator)로 이루어진 모델입니다. ELECTRA는 BERT의 사전학습 방식인 MLM과 NSP 대신에 RTD(Replaced Token Detection)를 활용해서 사전 학습한 모델입니다. RTD는 생성자에서 MLM 방식과 동일하게 마스킹 된 부분이 무엇인지 생성하고, 판별자가 출력된 토큰들이 실제 토큰인지 생성된 토큰인지 학습하는 방식입니다.
BERT와는 다르게 모든 토큰에 대해서 학습할 수 있기 때문에 더 효율적입니다. 그래서 기존 모델들과 비교했을 때 더 빠르게 수렴하고, 동일 시간 학습 시에도 더 높은 성능을 낼 수 있었습니다. 사전 학습 모델은 목적에 따라 다양한 모델이 있습니다.
이번 프로젝트에서는 한국어 모델이면서 대화체에 특화된 사전 학습 모델인 KcBERT와 KcELECTRA를 고민했습니다. KcELECTRA가 더 많은 양의 데이터로 학습하고, 대화체 데이터를 기반으로 한 과제에서 다른 한국어 모델 대비 가장 높은 성능을 보여줬기 때문에 KcELECTRA를 활용해서 개발하게 되었습니다.
학습 데이터에는 각 메시지에 인텐트가 매칭되어 있습니다. 게임에 따라 인텐트의 개수는 2~3개로 상이하며, 데이터에는 게임과 관련된 기능 대화뿐만 아니라 일상 대화도 포함되어 있습니다.
기능: 게임에 관련된 질문 데이터에 따라 인텐트의 개수가 다름
일상: 게임을 제외한 일상 대화 모든 게임 데이터에 동일하게 1개의 인텐트 계층으로 구성
이번 프로젝트에서 사용한 학습 데이터는 다음과 같습니다.
기능 인텐트 계층: 3개 사내 HR
기능 인텐트 계층: 2개 ‘컴투스프로야구’, ‘서머너즈 워: 크로니클’, ‘크리티카’
모델 구조
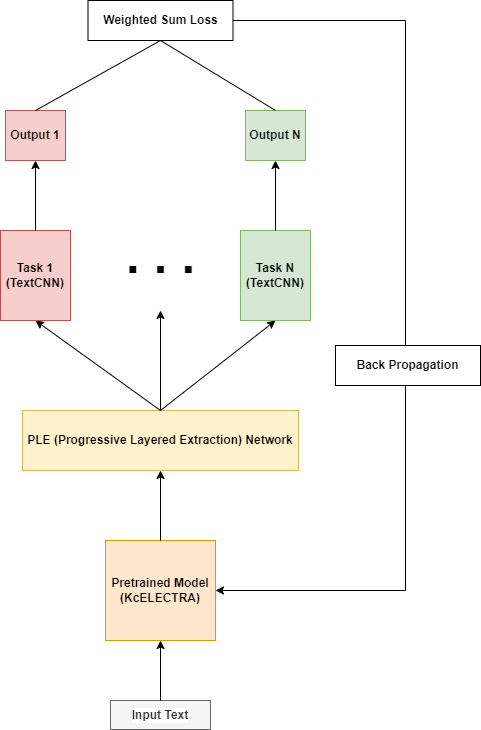
<그림 8. 챗봇 개발에 사용되는 모델 구조>
이번 챗봇 개발에 사용된 모델 구조는 위 그림과 같은 구조로 되어 있고, 다음과 같이 동작합니다.
1문장이 입력으로 들어오면 사전학습 모델을 통해 PLE에 맞는 입력값 생성
2입력값은 PLE 모델에 들어가면서 인텐트 개수만큼의 출력값 생성
3PLE의 출력값들은 각 과제 레이어에 들어가서 최종 인텐트 출력
학습 시에는 각 과제 레이어에서 출력된 값에 대한 loss를 가중합하여 최종 loss 값을 만들어낸 후 역전파(Back Propagation)를 통해 학습
PLE 구조에 사용되는 세부 레이어는 다음과 같이 구성했습니다.
Expert 레이어: 트랜스포머 인코더 레이어 사용
Gate 레이어: 논문에 제시된 방식대로 FC (Fully Connected) 레이어 사용
Task 레이어: 문장에 있는 모든 토큰을 활용해서 분류를 할 수 있는 TextCNN 사용
평가에 사용된 모델들은 다음과 같습니다. 성능 평가 척도로는 정확도(Accuracy)를 활용했습니다.
상용 모델(KoBERT + 앙상블)
MTL 기반 KcELECTRA 모델(1차 실험 모델)
MTL 기반 KcELECTRA 모델(2차 실험 모델, CurricularFace loss 사용)
모든 실험에서 평가 데이터 기준으로 가장 낮은 loss를 기록한 모델에 대해서 정확도를 비교했습니다.
1차 실험 결과
상위 인텐트 추론 결과에서 기존 상용 모델과 비교했을 때 MTL 모델에서 성능이 일부 향상되었고, 특히 일상 데이터에 대한 성능은 큰 향상을 보였습니다.
<표 1. 1차 실험 결과>
하위 인텐트는 상위 인텐트에 비해 인텐트의 수가 많기 때문에 성능이 낮습니다. 일상 대화의 경우 인텐트 계층이 1개이기 때문에 하위 인텐트에서도 비슷한 성능을 보입니다.
<표 2. 1차 실험 인텐트별 추론 결과>
기존 상용 모델과 비교했을 때 일상 대화에서 성능이 높아지긴 했지만, 서비스 제공을 위해서는 기능 대화에 대한 성능을 더 높여야 했습니다. 그래서 모델의 성능을 향상하기 위해 다른 방안을 강구하였습니다.
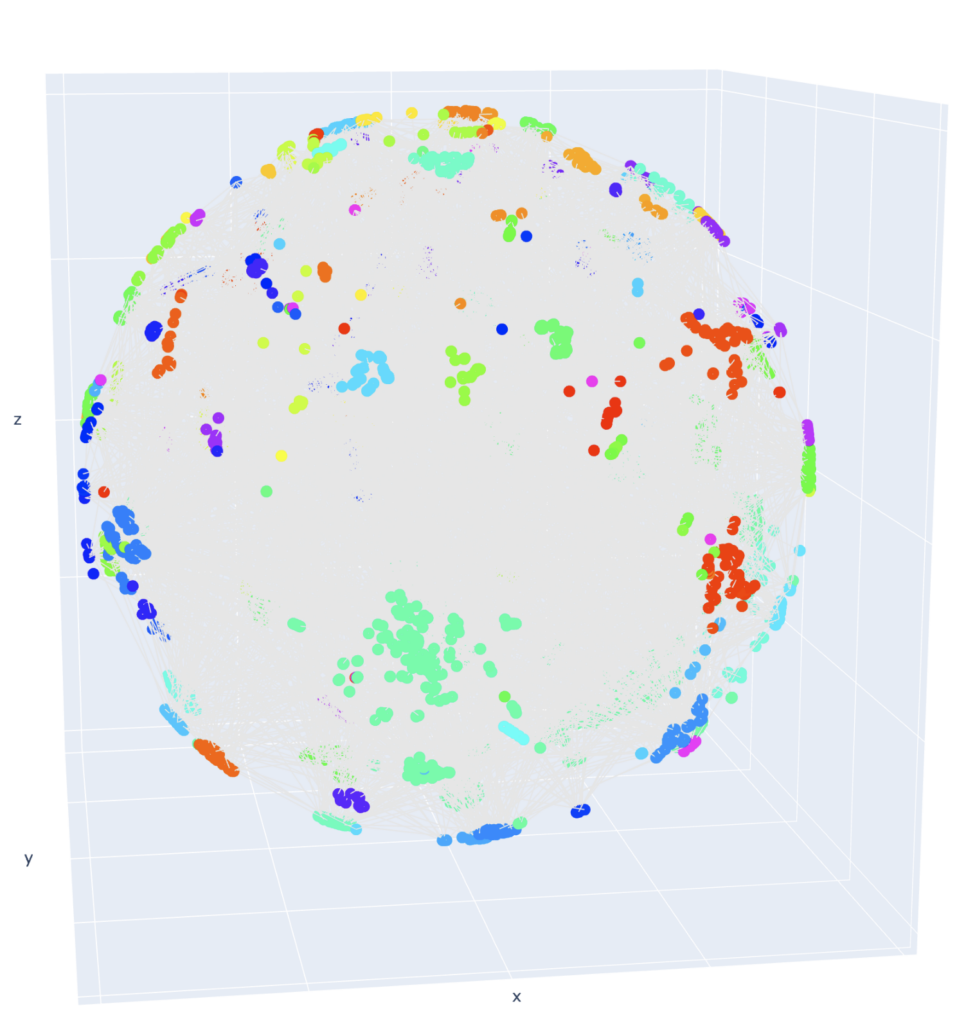
성능을 높이기 위해 여러 논문을 참고하였고, SoftMax 기반 Cross Entropy loss가 분별력 향상에 있어서 한계가 있다는 내용을 확인했습니다. 그리고 이러한 현상이 우리 데이터에 동일하게 나타나는지 확인해 볼 필요가 있었습니다. 그래서 분류 레이어에 들어가기 전의 표현에 대해서 tSNE로 차원 축소 후 시각화해 보았습니다.
다음과 같이 시각화했을 때 군집이 제대로 형성되지 않는 것을 확인할 수 있었고, 이를 근거로 모델이 표현을 통해 인텐트를 분류하는 데 어려움이 있다고 판단했습니다.
추가 실험에서는 표현의 군집들이 구분될 수 있게 만들어주는 손실 함수를 활용하고자 하였고, Margin loss와 Mining loss가 합쳐진 CurricularFace loss를 활용해서 추가 실험을 진행하였습니다.
<그림 9. ‘크로니클’ 데이터 기반 상위 인텐트, 하위 인텐트 시각화>
2차 실험 결과 (CurricularFace loss 적용)
상위 인텐트 추론 결과에서 기존 상용 모델과 1차 실험 모델보다 CurricularFace Loss의 도입으로 성능이 유의미하게 향상되었습니다. 특히 비교적 낮은 성능을 보였던 게임 데이터에 대한 성능이 많이 개선되었습니다.
<표 3. 2차 실험 결과>
하위 인텐트에 대한 성능도 크게 향상된 것을 확인할 수 있었습니다. HR은 성능이 많이 오르진 않았지만, 그 외 게임 데이터를 세부적으로 봤을 때 일상 대화뿐만 아니라 기능 대화에 대한 성능이 많이 개선되었습니다.
<표 4. 2차 실험 인텐트별 추론 결과>
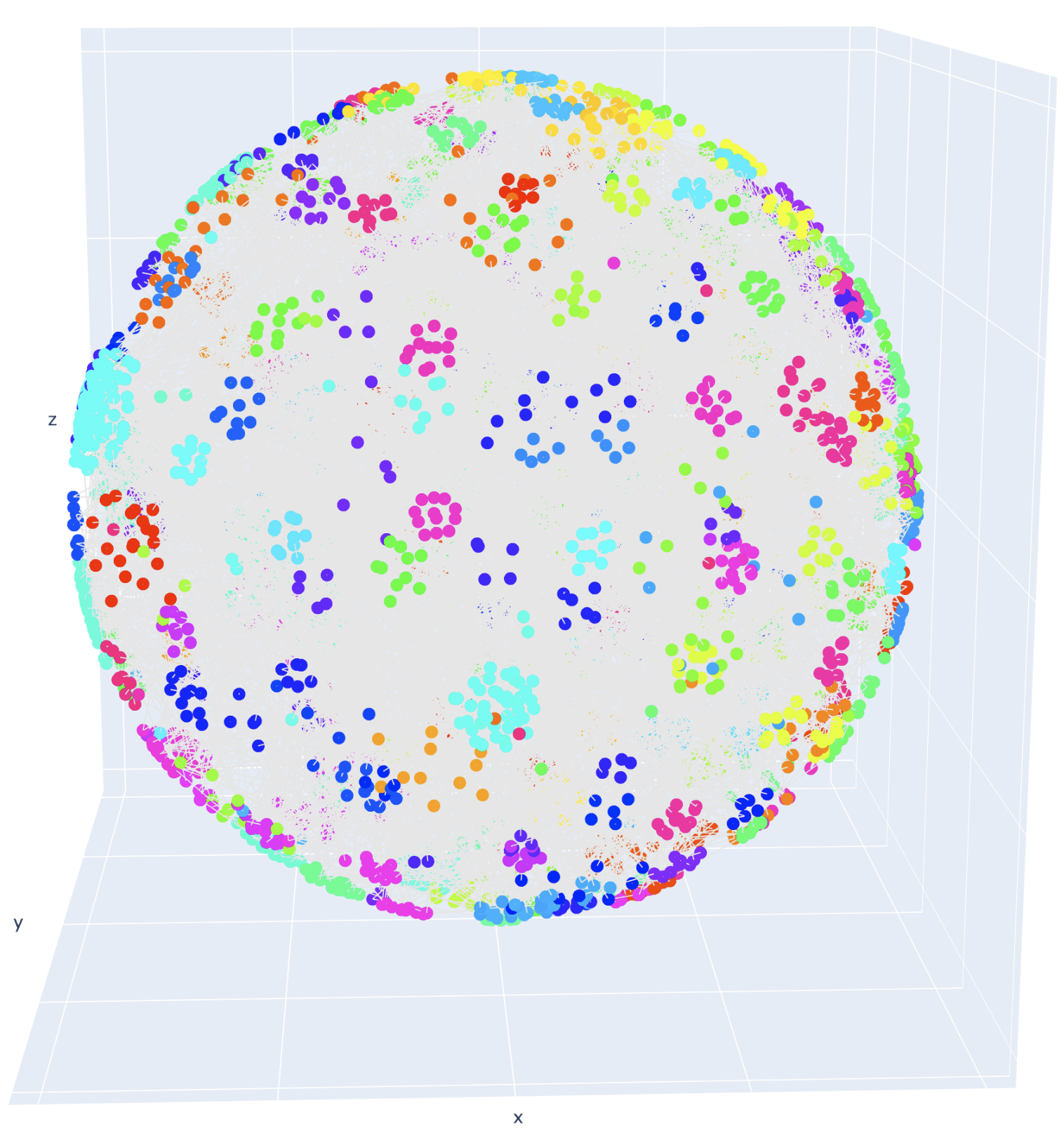
인텐트 추론 시 사용되는 표현에 tSNE를 이용해 시각화 했을 때도 1차 실험 모델 대비 인텐트가 상대적으로 군집이 잘 형성되어 있는 것을 확인할 수 있었습니다. 이를 통해 모델이 1차 모델에 비해서 좀 더 쉽게 분류함에 따라 성능이 올랐을 것이라고 판단하고 있습니다.
<그림 10. ‘크로니클’ 데이터 기반 상위 인텐트, 하위 인텐트 시각화>
결론
MTL 모델이 기존 챗봇 시스템에 적용되었을 때 다양한 이점이 있다는 것을 파악할 수 있었습니다. 성능 면에서도 서비스 중인 모델을 뛰어넘었고, 하나의 모델로 상/하위 인텐트를 함께 추론할 수 있기 때문에 성능과 모델 관리 측면에서 기존 모델보다 장점이 많았습니다. 또한 목적에 따라 인텐트를 골라 사용할 수 있다는 장점을 확인할 수 있었습니다.
MTL 모델을 서비스에 적용하기에는 아직 부족한 점이 있지만, 지속적인 실험과 개선을 통해 가까운 시점에 챗봇 서비스에 적용할 수 있을 것입니다.
이혜빈 이번 기회로 자연어 처리를 처음 접해 많이 배울 수 있는 시간이었습니다. 챗봇 외에도 AI 기술을 활용해 더 나은 서비스를 제공하기 위해 노력하고 있습니다. 앞으로도 좋은 글을 통해 개발 과정을 공유해 드릴 수 있도록 하겠습니다.
권대욱 ‘수다꾼’이 아닌 ‘고객 지원’ 챗봇을 개발하고 운영하면서 도입 목적을 확실히 정하고 용도는 되도록 좁게 설정하는 것이 좋다고 느꼈습니다. 챗봇이 아직은 모든 입력에 대해 이해하는 기능에 한계가 있지만, 다양한 연구와 응용을 통해 점진적으로 발전시킬 수 있으리라 생각합니다. 끝으로 최근 출시한 사내 인사 챗봇과 ‘서머너즈 워: 크로니클’ 챗봇에 많은 관심 부탁드립니다(_ _). 감사합니다.
전현민 새로운 모델과 방법론을 공부하고, 같은 업무를 수행하는 팀원들과 논의해 볼 수 있었던 좋은 기회였습니다. 현재 운영하는 챗봇 서비스 모델의 장단점과 발전 가능성에 대해서 생각해 보는 계기가 되었고, AI개발팀의 발전에 있어 작지 않은 한 걸음을 내디딘 연구였다고 생각합니다. 서비스를 발전시키거나 새로운 서비스를 개발하기 위하여, 이번처럼 함께 연구하고 논의할 기회가 앞으로도 많이 생겼으면 좋겠습니다.
AI 개발팀에서 연구한 기술에 대해 소개할 수 있게 되어 영광이었습니다. 이번 연구에 도움을 주신 팀원분들께 감사하다는 말씀드리고 싶습니다. 현재 AI 개발팀에서는 다양한 AI 기술을 연구하고 서비스에 적용하기 위해 많은 노력을 하고 있습니다. 앞으로도 AI 개발팀에서 연구한 기술들을 소개할 수 있도록 노력하겠습니다. 감사합니다!